
编译原理 1:绪论
1 什么是编译
计算机程序设计语言可以分为三个层次:
机器语言:能够被机器直接理解的语言,这是由计算机的硬件电路设计决定的。- 例如
C706 0000 0002,C706是操作码,表示移入操作。0000和0002是两个操作数。因此C706 0000 0002这行代码的含义就是将数值2移入到地址为0000的内存单元中。 - 但是机器语言人类难以读懂,于是就出现了汇编语言。
- 例如
汇编语言:通过引入助记符,将不好记忆的数字用单词代替。- 例如
MOV X, 2,用MOV代替C706,用X表示地址0000,数值2保持不变。这样在逻辑上,MOV X, 2和C706 0000 0002的功能是一样的。 - 机器无法读懂字母,因此需要通过汇编器将汇编语言的代码翻译成机器语言的代码。对应的把汇编代码翻译为机器代码的过程称为汇编。
- 汇编语言需要专业的计算机从业人员编写,而且汇编语言编写效率不高,不方便编写大型程序,于是就出现了高级语言。
- 例如
高级语言:以一种类似于数学表达式或者自然语言的形式编写程序的语言。- 例如
x = 2,这条指令完成了和前面两条指令相同的功能。 - 机器无法理解自然语言,因此首先需要通过编译器将自然语言形式的高级语言代码翻译成汇编语言的代码,而后通过汇编器翻译成机器语言代码。对应的把高级语言代码翻译成汇编语言代码的过程称为编译。但是有的时候,编译也会包括汇编。
- 例如
因此,编译指的就是将高级语言翻译成汇编语言或机器语言的过程。其中:
- 被翻译的语言称为
源语言 - 将翻译的语言称为
目标语言

而从高级语言翻译到机器语言的过程中,会涉及到诸多的数学原理和算法。因此编译原理这门课,就是讲解如何把高级语言翻译为机器语言的一门课程。学完这门课程,我们可以设计自己的高级语言,并且实现对应的编译器,即发明自己的编程语言。
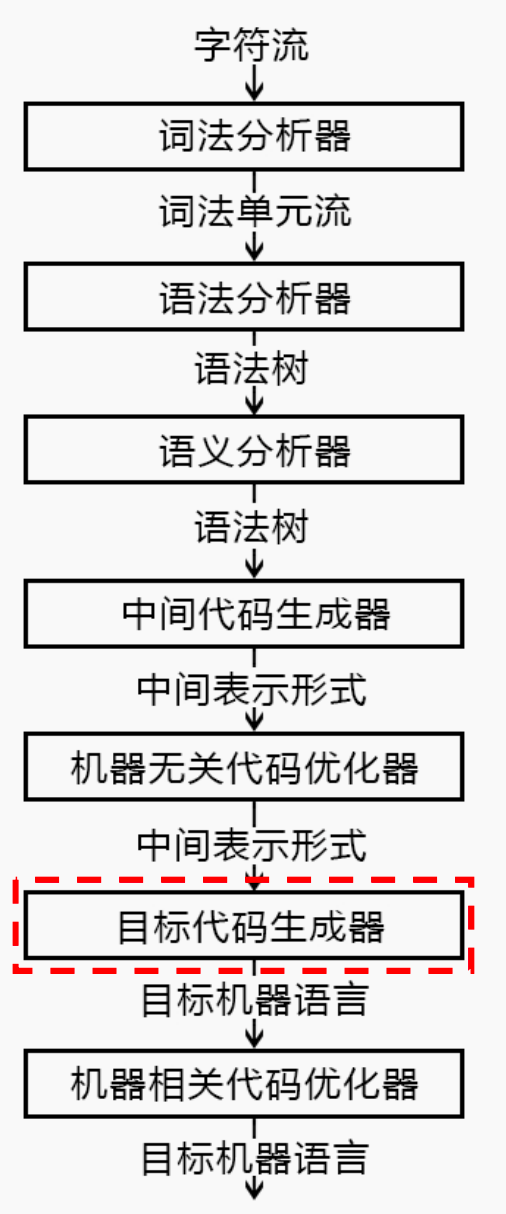
2 编译器在语言处理系统中的位置
一个高级语言(以C语言为例)编写的程序的编译流程如下:

其中:
预处理阶段:我们的源程序可能存储在多个文件中,并且会有称为宏的缩写语句。因此预处理阶段的需要把存储在不同文件中的源程序聚合起来,并且处理宏。完成这些工作的程序称为预处理器。
编译阶段: 经过预处理器预处理后我们的源程序此时就成了一个巨大的文件。这个时候,在编译阶段,编译器把我们的高级语言的代码翻译成汇编语言代码。汇编阶段:在汇编阶段,汇编器将翻译得到的汇编语言形式的代码翻译成可重定位的机器代码。未来在程序运行时,加载器会修改可重定位代码中的地址到合适的为止
链接阶段:在链接阶段,链接器将多个可重定位的机器代码文件(包括库文件)连接到一起,解决外部内存地址问题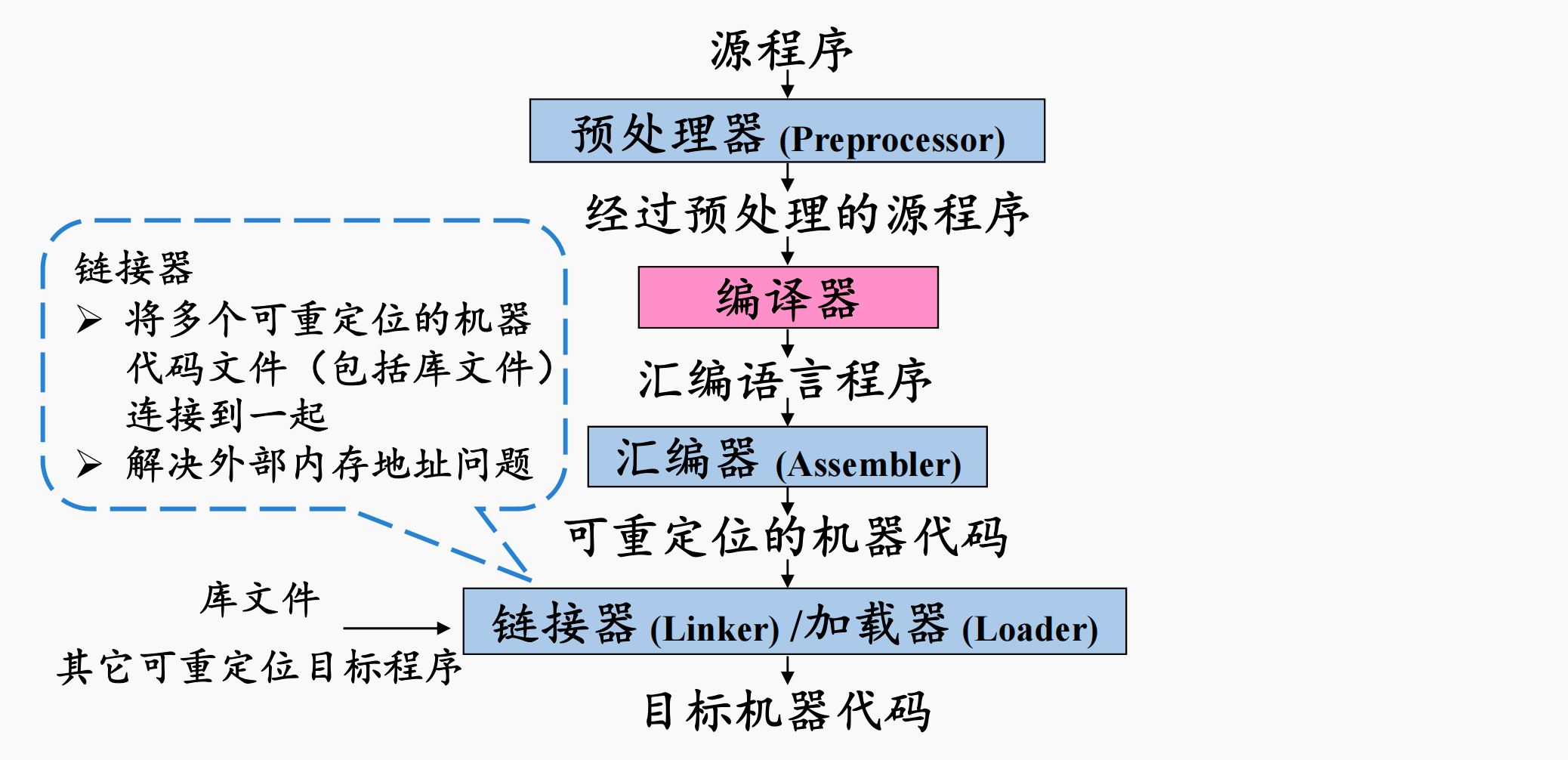
3 编译系统的结构
编译的本质就是翻译,编译器的输入是高级语言程序,输出是汇编语言程序/机器语言程序

我们举一个人工英汉翻译的例子:In the room , he broke a window with a hammer
翻译的步骤大体有两步:
- 第一步:在源语言层面,分析句子的含义,得到句子的语义,这一步称为
语义分析 - 第二个:根据句子的语义,用目标语言将含义表达出来即可
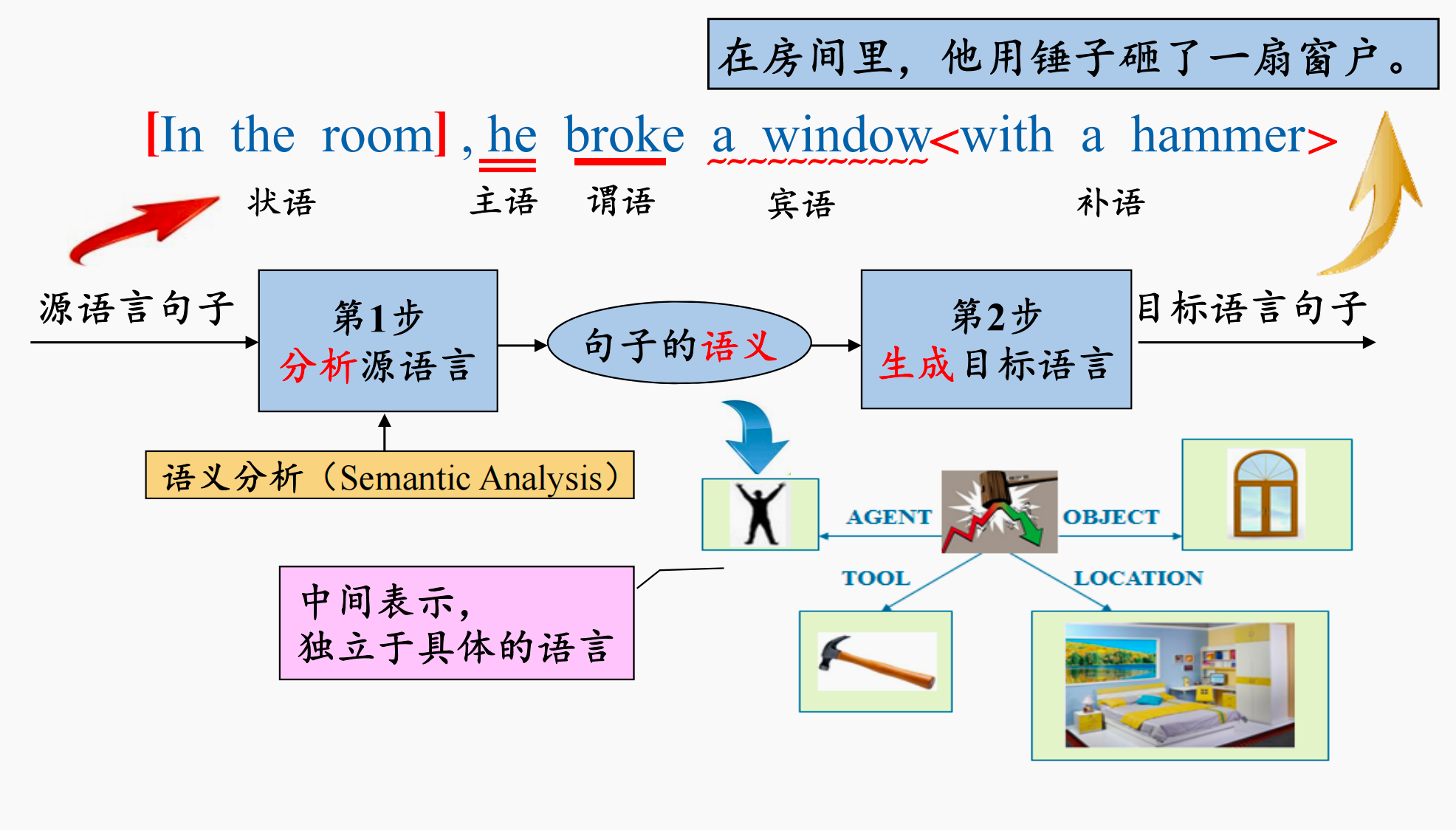
我们进行语义分析,通常是从划分句子的成分开始下手。例如我们首先找出句子的核心谓语动词broke,这样就明白了这句话一半的意思。而后顺势找出主语、宾语、状语等成分
在描述句子的语义的时候,我们希望可以借助与语言无关的对象将其描述出来,例如我们可以使用一个图。图中的节点就是句子的成分,即谓语、宾语、主语……而边则表示节点与节点间的关系,例如打的受试者是窗户,发出者是人……这种与语言无关的描述句子内容的对象,称为中间表示
因此,通过上面的介绍,我们知道了,进行语义分析,是需要从划分句子的成分开始的。而句子中的成分都是各类短语。因此我们需要分析各类短语在句子中的成分,因此我们需要进行语法分析
短语是由单词组成的。因此我们为了进行语法分析,需要先进词法分析
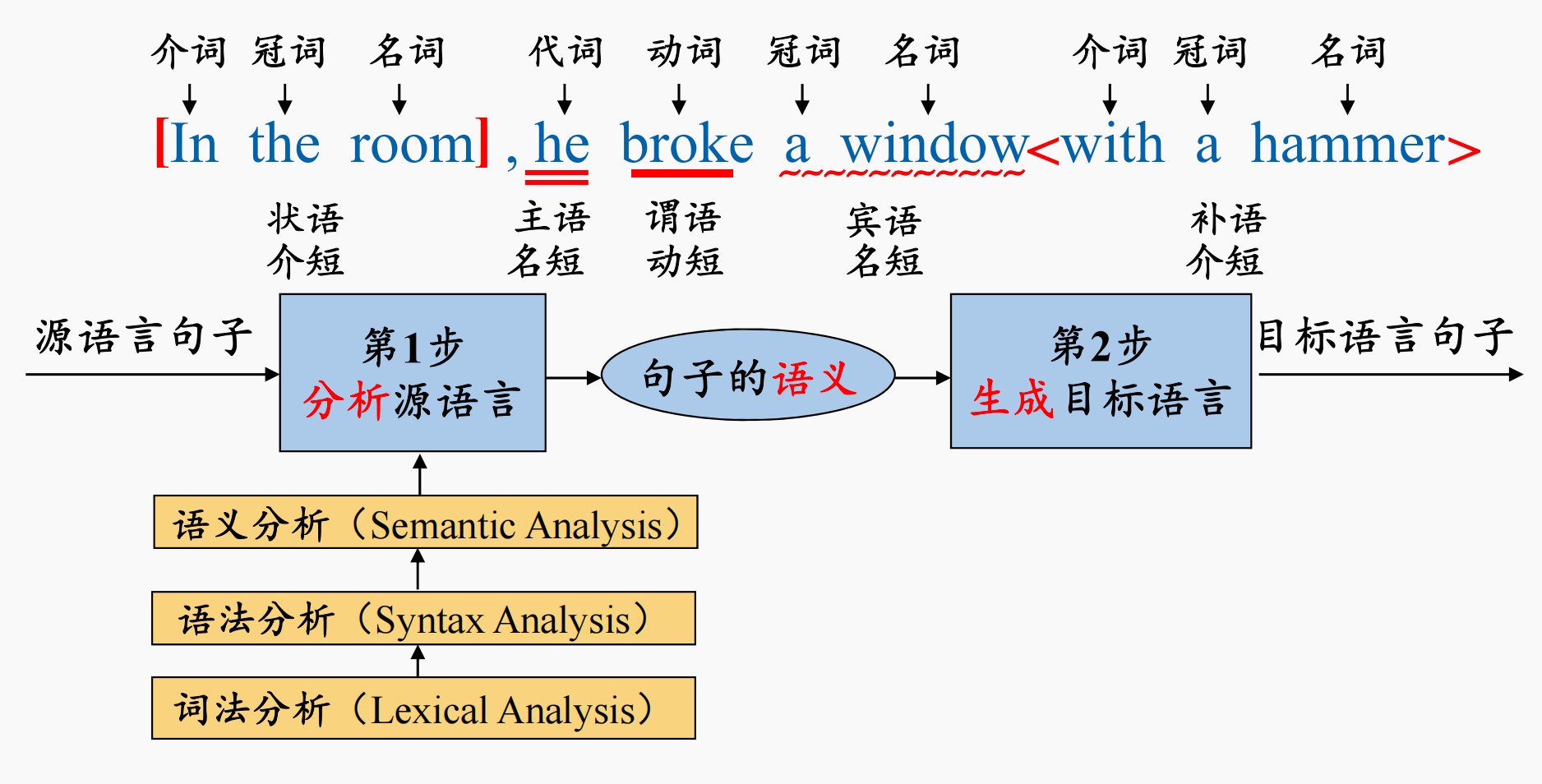
综上,我们就得到了一个句子翻译的过程:
- 首先进行词法分析,得到句子中各个单词的词性和词类
- 而后进行语法分析,得到句子中的各类短语,从而获得句子的结构
- 接下来进行语义分析,得到句子中各个短语在句子中充当的成分,以及与核心谓语动词之间的关系
- 最后给出中间表示形式

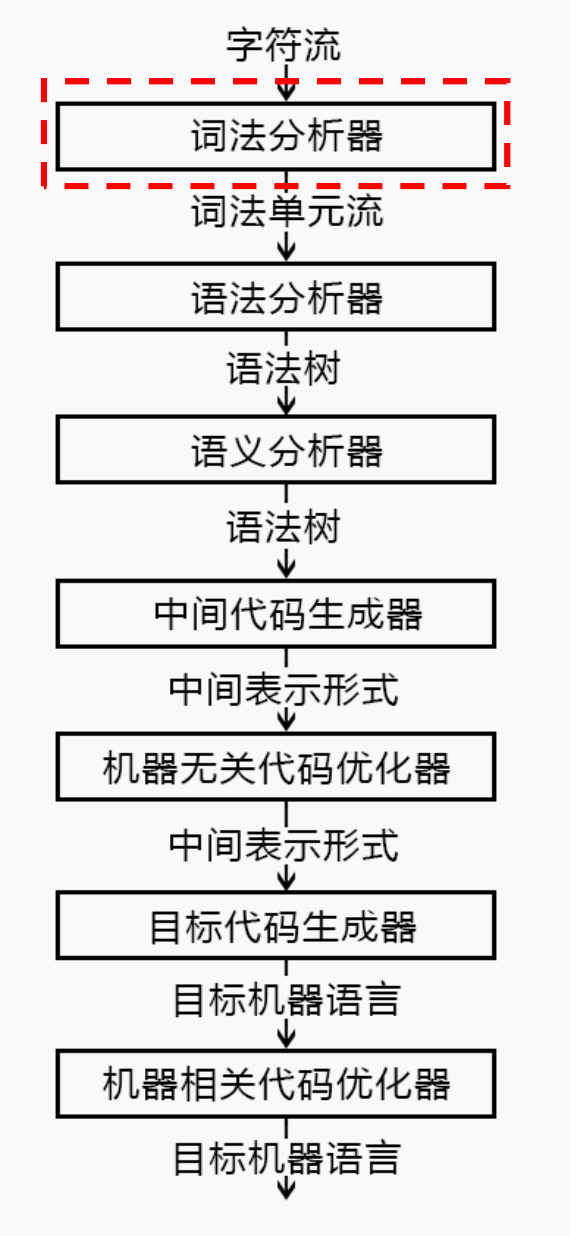
事实上,编译器在工作的时候也会经过这样的几个步骤,称为阶段:
- 前几个阶段对源语言进行分析,输出中间表示,因此称为
前端 - 后几个阶段对中间表示进行分析,输出目标语言,因此称为
后端

PS:目前有理论可以做到在语法分析的同时进行语义分析,这一技术称为语法制导翻译,此时语法分析器、语义分析器和中间代码生成器是同一个东西
4 词法分析 Scanning
我们接下来详细介绍一下词法分析
词法分析是编译的第一个阶段
词法分析的任务是从左向右逐行扫描源程序的字符,识别出各个单词,确定单词的类型,而后将识别出的单词转换成统一的机内表示——词法单元(token)的形式
token是一个二元组,由<种别码, 属性值>构成。
种别码表示单词具体的种别。自然语言中每个单词都有一个词性,例如名词、动词……
程序设计语言中的单词,主要分为以下五类:

其中:
关键字是有限的,因此我们可以为每一个关键字分配一个种别码标识符是无限的,因此我们可以将所有的标识符视为一类具有同一词性的词语,即为所有的标识符分配同一个种别码。而为了区分不同的标识符,我们使用属性值来保存标识符具体的名称常量类似标识符,也是无限的,但是会有类型的区分。因此我们为同一类型的常量分配同一个种别码,使用属性值来区分同一类型的、不同的常量运算符是有限的,因此可以一词一码或者根据运算符的类型(算术运算符、关系运算符、逻辑运算符……)一型一码界限符和关键字类似,一词一码
A 词法分析举例
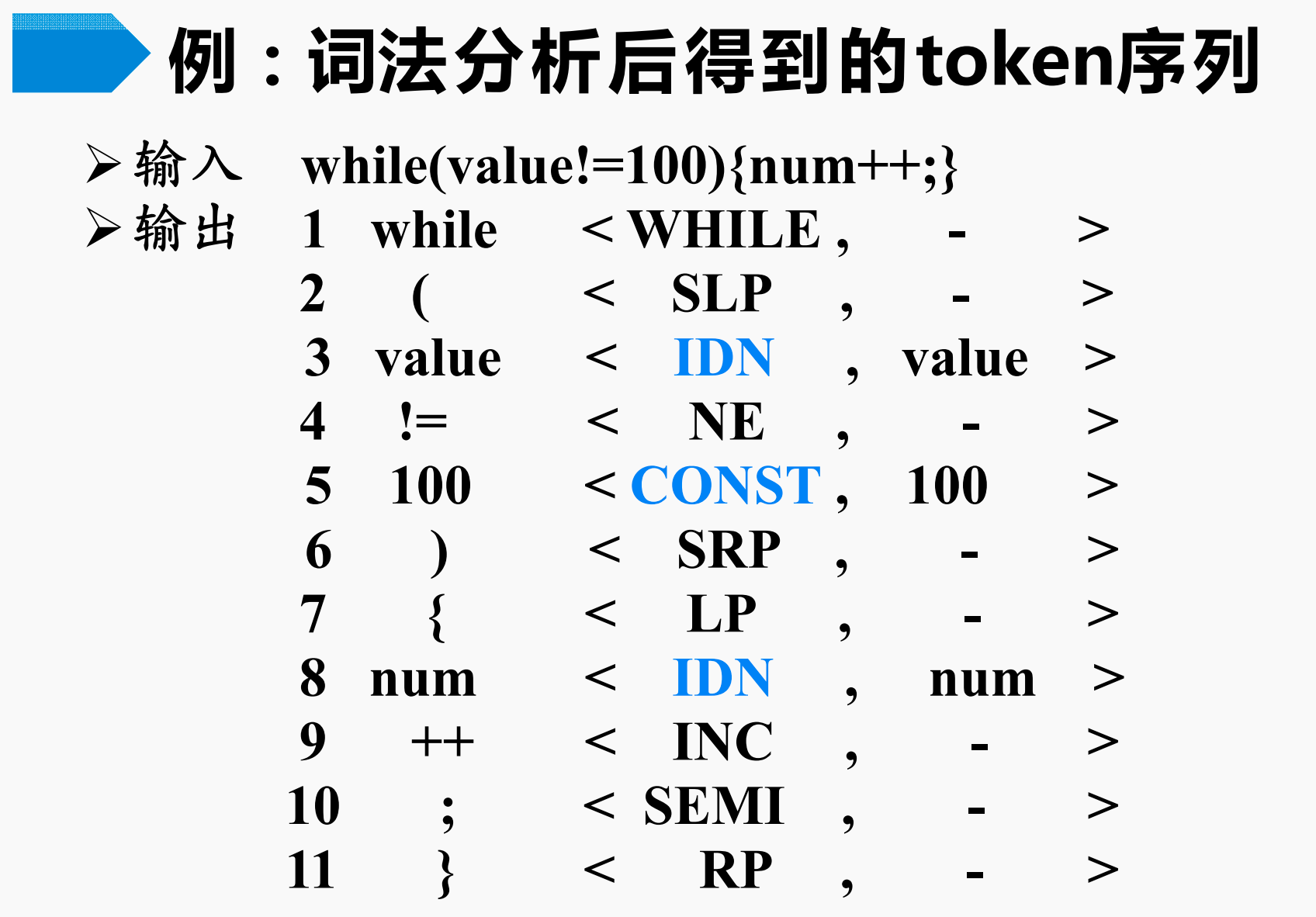
根据上述词法分析的原则,我们针对这段代码进行词法分析:
while(value != 100) {
num++;
}
按照上面所说的词法分析的注意事项,可以得到词法分析的结果,即token序列为:
< WHILE , - >, < SLP , - >, < IDN , value >, < NE , - >, < CONST , 100 >, < SRP , - >, < LP , - >, < IDN , num >, < INC , - >, < SEMI , - >, < RP , - >
注意:
- 种别码应该是整数,这里为了方便去理解,所以使用宏定义的符号常量
- 当种别码可以区分
token的时候,属性值留空,否则使用属性值来保存token的字面值
5 语法分析 Parsing
语法分析是编译的第二个阶段

语法分析的任务是从词法分析器输出的token序列中识别出各类短语,并构造语法分析树
- 语法分析树描述了句子的语法结构
A 赋值语句的语法分析树
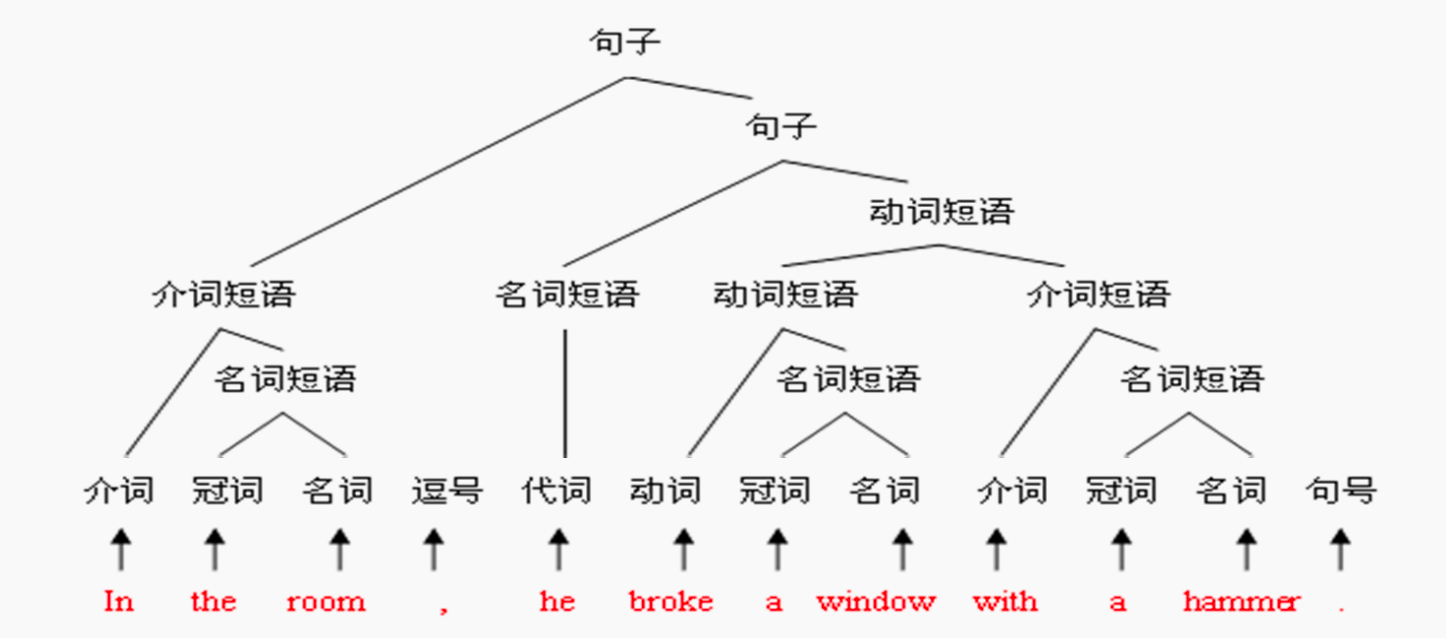
我们举一个赋值语句position = initial + rate * 60;的语法分析树:
- 首先进行词法分析,得到该赋值语句的
token序列:<id, position> <=> <id,initial> <+> <id, rate> <\*> <num,60> <;> - 针对
token序列构建语法分析树
可以看出:
- 一个标识符可以构成一个表达式
- 表达式和表达式经过运算得到表达式
- 标识符和一个赋值符号再加上一个表达式可以得到一个赋值语句

B 声明语句的语法分析树
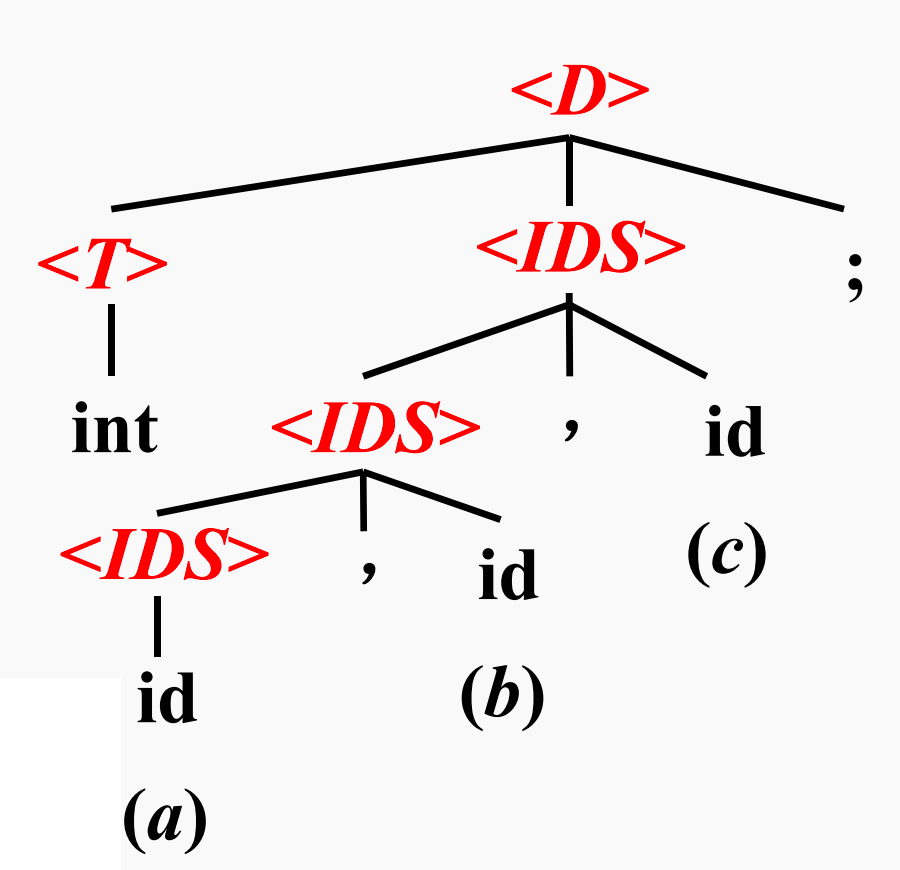
我们首先给定声明语句的文法。文法就是一系列规则组成的集合。声明语句的文法为:

其中:
<D>表示Declaration,即表示声明语句<T>表示Type,即类型<IDS>表示IDentifier Sequence,即标识符序列
因此,声明语句的文法的
- 第一个规则表示:声明语句由一个类型+一个标识符组成
- 第二个规则表示:类型可以是
int、real、char、bool - 第三个规则表示:标识符序列可以就是标识符本身,也可以是一个标识符序列在拼接一个标识符
因此,根据声明语句的文法,我们构建下述生命语句的语法分析树
int a, b, c;
6 语义分析
语义分析是编译的第三个阶段。

通常,高级语言中的语句有两种:
- 声明语句,即在分配存储空间,并将该存储空间和一个标识符关联
- 执行语句,即执行多条指令,得到执行的结果和效果
而前面通过词法分析拿到了token序列、词法分析拿到了语法分析树之后,接下来的语义分析就针对输入的语法分析树来分别处理这两类语句。
简单的说,语义分析的任务就是分析语法分析树,构建符号表,同时检查语法错误。我们接下来详细对其进行介绍
A 语义分析的任务
具体而言,语义分析阶段的任务有两个:
- 收集标识符的属性信息
- 语义检查
1. 收集标识符的属性信息
程序中声明语句声明的标识符需要在内存中分配一定的空间存储,因此语义分析收集标识符的属性的目的之一就是确定为各个标识符分配的存储空间的大小。
具体来说,需要为每个标识符收集如下信息:
种属(Kind):简单变量、复合变量(数组、记录……)、过程(函数)、宏、……
类型(Type):整形、布尔、字符、指针、……
存储位置、长度(ADDR):例如一个实型数组
x,有八个元素,假设每个实型变量占用8个字节,那么实型数组x占用64个字节,相对地址为0~63,则整形变量i的起始地址为64,以此类推,j相对地址为68
值(Value)
作用域
对于种属为函数的标识符,还需要知道函数的参数和返回值信息,具体包括:
- 参数个数、参数类型、参数传递方式、返回值类型、……
在语义分析阶段,收集的这些标识符的信息,都会存放在一个称为符号表(Symbol Table)的数据结构中。
- 符号表中每一个记录都对应一个标识符
- 记录的每一个字段都对应标识符的一个属性
- 为了实现固定长度,通常将标识符
token的属性值存放到字符串表中,而后将NAME字段设置为起始地址和长度,从而固定NAME字段的长度

2. 语义检查
程序的错误可能发生在运行时,也可能发生在编译时。编译时检查出的错误就是因为程序的语句不符合语法。
因此,在语义分析阶段,要进行的第二个任务就是进行语义检查。通常会检查下述错误:
- 变量或过程未经声明就使用
- 变量或过程名重复声明
- 运算分量种属不匹配。注意这里的是种属,不是类型,即检查的是类似于
数组名 + 函数名这样的错误。 - 操作符与操作数之间的类型不匹配
- 数组下标不是整数
- 对非数组变量使用数组访问操作符
- 对非过程名使用过程调用操作符
- 过程调用的参数类型或数目不匹配
- 函数返回类型有误
7 中间代码生成
常用的中间表示有两种:
- 三地址码(
Three-address Code) - 语法结构树/语法树(
Syntax Trees)- 注意,语法树又称为语法分析树、抽象语法树(
Abstract Syntax Tree,AST)
- 注意,语法树又称为语法分析树、抽象语法树(
介绍语法树我们在前面词法分析的时候就已经获得了,而三地址码则是类似于汇编指令的代码。因为后面会详细介绍语法分析树,因此所以这里介绍一下三地址码。
三地址码
三地址码由类似于汇编语言的指令序列组成,每个指令最多有三个操作数(operand)。每个操作数使用一个地址表示,因此称为三地址码。
地址可以是:
- 源程序中的名字(
name) - 常量(
constant) - 编译器生成的临时变量(
temporary)
一般常用的三地址码有:

三地址码通常由下面三种表示:
- 四元式(
Quadruples) - 三元式(
Triples) - 间接三元式(
Indirect Triples)
比较常用的是四元式,即将三地址码表示为(op, y, z, x)的四元式,例如四元式表示三地址码为:

需要注意的是:三地址指令序列唯一确定了运算完成的顺序
使用三地址码生成下面这段C语言代码的中间表示:
while (a<b){
while (a<b){
if (c<5)
while(x>y)
z=x+1;
else
x=y;
}
}

8 编译器的结构
编译器前段部分到中间代码就结束了,接下来我们讲解一下编译器后端的结构
A 目标代码生成器
我们前面在中间代码生成的时候生成了与源语言、与目标平台均无关的中间表示。但是为了能够得到可以在目标平台运行的程序,我们还需要将中间表示形式转换为目标语言。
而完成这一功能的就是编译器,具体来说是编译器中的目标代码生成器:
- 目标代码生成以源程序的中间表示形式作为输入,并把它映射到目标语言
- 目标代码生成的一个重要任务是为程序中使用的变量合理分配寄存器
B 代码优化器
所谓代码优化,是为改进代码所进行的等价程序变换,使其优化后的程序运行得更快一些、占用空间更少一些,或者二者兼顾
这一步通常是对程序员写的程序中的指令进行逻辑上的等价变换,例如int i = 12; i = 15;直接优化为int i = 15;
优化也是分为两部分:
- 中间无关代码优化,这个就是对代码逻辑进行优化
- 目标平台代码优化,这个就是由于目标平台,例如
RISC-V对一些指令进行了优化,例如一些原子指令,所以这一步就是将中间无关代码中的指令使用目标平台的、等效的、高效率指令替换




