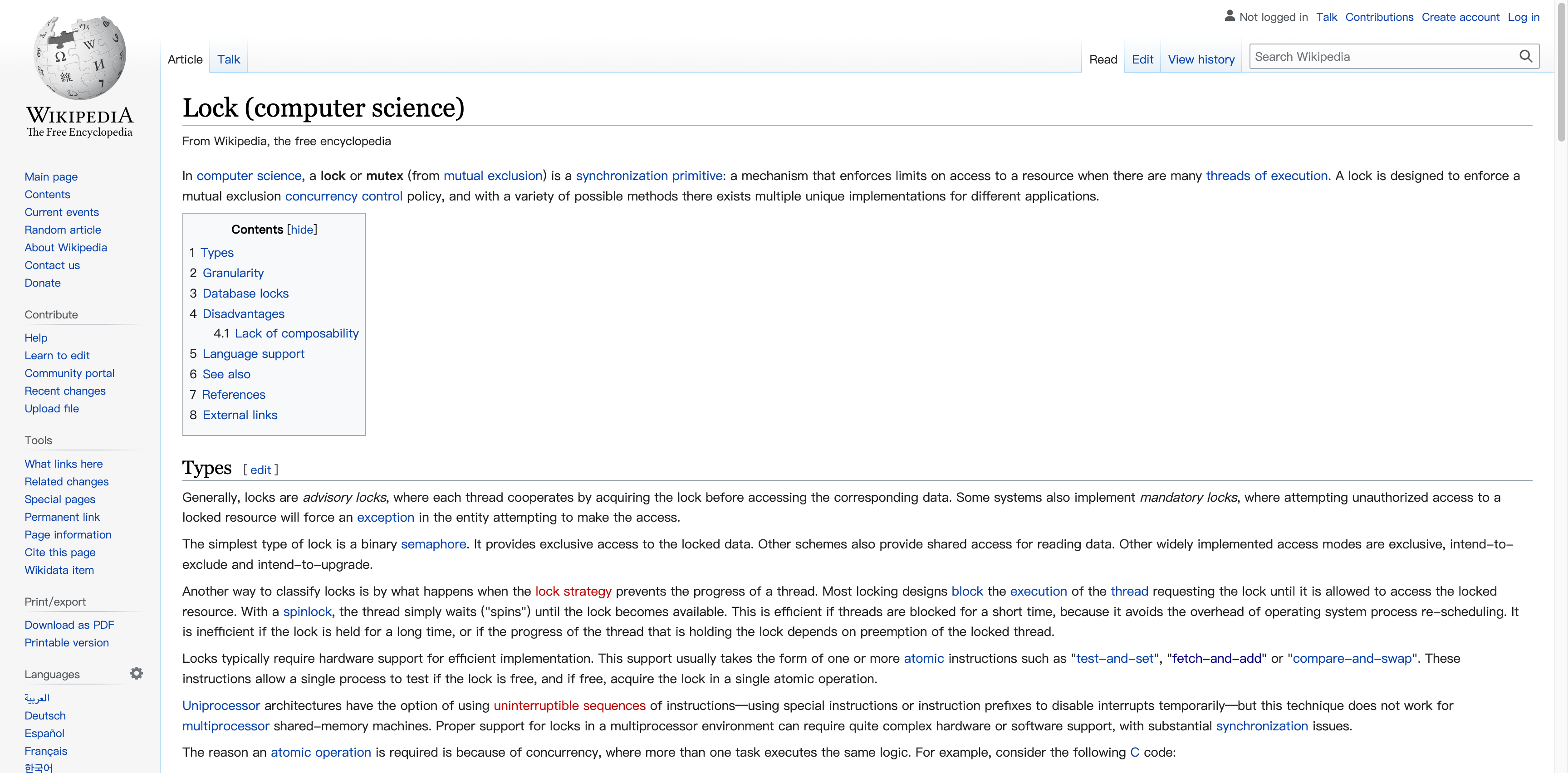
这张图,包含了操作系统访问内存的所有内容,看懂这张图,就看明白了操作系统是如何访问内存的。
CPU访问内存:内存分段与内存分页
一、各种地址
CPU访问物理内存的过程中有很多的地址,包括:物理地址、逻辑地址、有效地址、线性地址、虚拟地址……
所以在介绍CPU访问内存的方式前(也是为了后面的复习),先介绍一下各种地址。
1. 物理地址
物理地址就是物理内存真正的地址,相当于内存中每个存储单元的门牌号,具有唯一性。不管在什么模式下,只有通过物理地址去访问内存,才能够获得数据。什么虚拟地址、线性地址,最终都要转换为物理地址,然后再去访问内存。
在实模式下,并不是直接直接给CPU物理地址,然后CPU去访问内存,而是通过段基址+段内偏移地址,经过段部件的处理,得到物理地址,而后CPU再通过此地址访问内存。
2. 线性地址/虚拟地址
线性地址与虚拟地址本质上就是同一个东西。区别就在于是否打开了分页机制。
在保护模式下,形式上CPU依然通过段基址+段内偏移地址的方式去访问内存,但是此时段基址+段内偏移中段基址已经不再是实模式下真正的地址。而是个称为选择子的东西。
选择子本质是个索引,即数组下标。通过这个索引便能在全局段描述符表(Global Descriptor Table, GDT)这个数组中找到相应的段描述符。段描述符中记录了该段的基地址、大小等信息,这样便得到了段基址。
此时,在保护模式下,段基地址+段内偏移通过查GDT之后得到的地址称为线性地址。若没有开启地址分页功能,此线性地址就被作物理地址来用,可直接访问内存。
若开启了分页功能,此线性地址又多了个名字,就是虚拟地址。虚拟地址、线性地址在分页机制下就是一个东西。 虚拟地址还要经过页部件转换成具体的物理地址,这样CPU才能将其送上地址总线去访问内存。也就是说,在开启了分页功能之后,线性地址还需要经过一次转换,才能得到物理地址。
由于分页功能是需要在保护模式下开启的,32位系统保护模式下的寻址空间是4GB ,所以虚拟地址或线性地址就能访问到4GB范围内的内存。
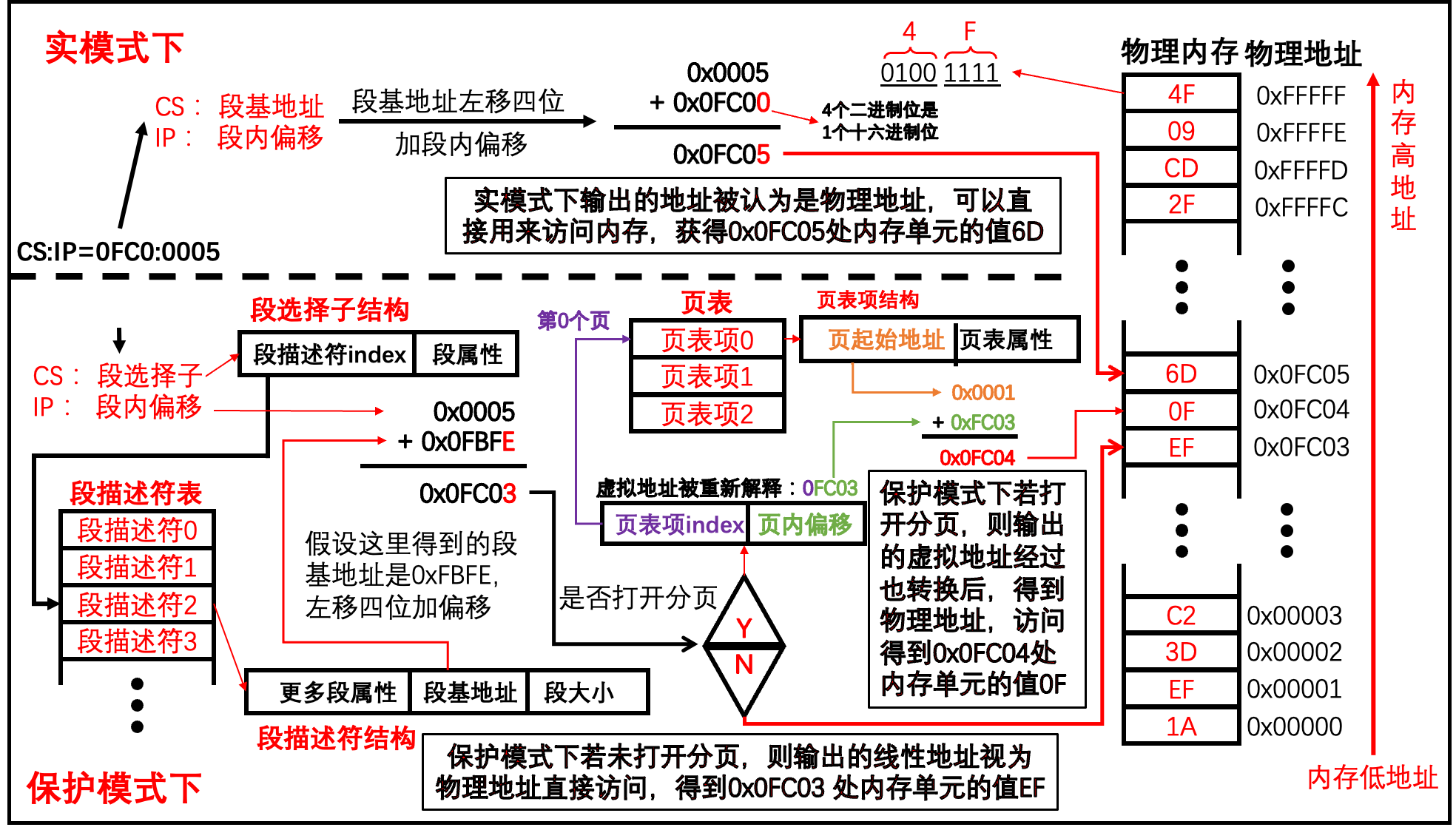
线性地址或者说虚拟地址,都不是真实的内存地址。它们其实都是程序眼中的内存地址,因此描述程序或任务的地址空间。线性地址由于未开启分页机制,因此此时程序眼中的地址空间和物理地址空间其实是一一对应的。而开启分页后,程序眼中的地址空间不和物理地址空间一一对应了,而是存在一个映射关系下图表示了这种关系,线性地址空间和最右侧的物理地址空间是一一对应的,而中间的虚拟地址空间和物理地址空间不是一一对应的。
3. 有效地址/逻辑地址
无论在实模式或是保护模式下,段内偏移地址又称为有效地址,也称为逻辑地址。事实上,有效地址或者说逻辑地址是程序员可见的地址,例如我们在C语言中指针存储的地址的值,其实就是有效地址。
这是因为,虽然说最终的物理地址是需要由段基址+段内偏移组合后经过转换而得到的,但是转换是针对CPU来说的,对于用户来说,我们只需要个给出段基址和段内偏移。由于段基址一般在编译时候已经有默认,而在运行的时候已经被指定,要么是在实模式下的默认段寄存器中,要么是在保护模式下的默认段选择子寄存器指向的段描述符中。所以我们用户其实只要给出段内偏移就行了,这个地址虽然只是段内偏移,但加上默认的段基址,就能够通过转换得到物理地址了。
二、实模式下访问内存:内存分段
说到实模式,就不得不说
Intel 8086 CPU了。虽然说Intel 8086这款CPU在1978年上市的,但是作为最早,也是最成功的CPU,其中诸多标准都被后来的CPU中继承了下来,并且一直延续至今。实模式就是伴随Intel 8086 CPU一起提出的,因此我们下面讲一边讲解Intel 8086 CPU,一边讲解伴随Intel 8086 CPU所提出的实模式以及实模式下的内存访问方式。

1. 什么是实模式
说到内存分段式访问,就得先说
实模式
CPU中本来是没有实模式这一称呼的,而是随着CPU的发展,后面有了保护模式后,为了与老的模式区别开来,所以称老的模式为实模式。
实模式的实体现在:程序中用到的地址都是真实的物理地址,即通过段基地:段内偏移得到的逻辑地址就是物理地址,也就是程序员看到的完全是真实的内存
此外,所谓模式,指的就是CPU的运行方式,是包含寻址方式、寄存器、指令集合等等在内的所有内容。为此,为了讲解伴随8086 CPU诞生的实模式,我们下面先介绍8086 CPU的相关内容。
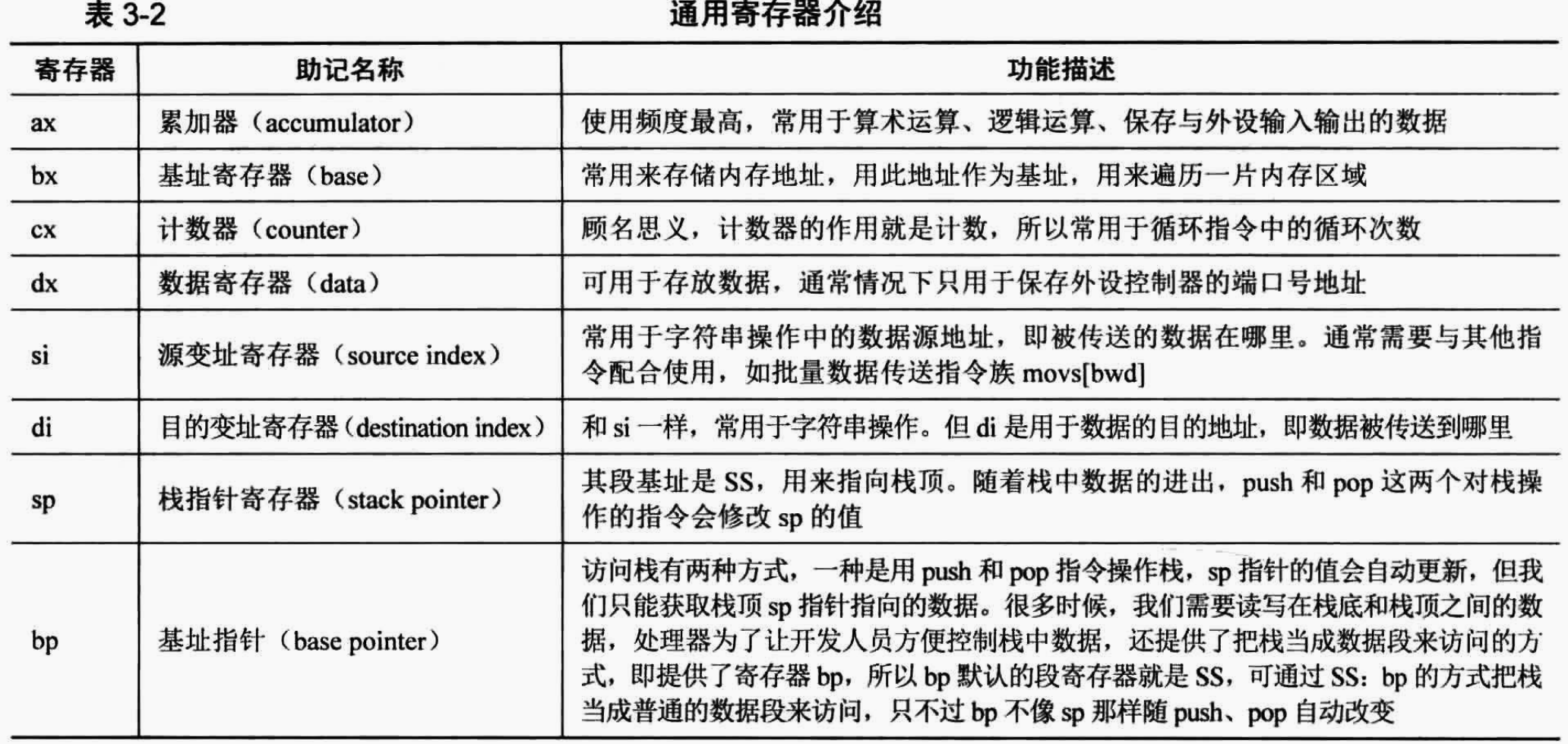
2. 8086的寄存器
寄存器是一种物理存储元件,一般都是集成在CPU上的。因此,CPU访问寄存器并从中获取需要计算的数据所需要的时间比访问内存等等存储介质所需要的时间更短
一般的存储介质要快,因此能够跟上CPU的步伐,所以在CPU内部有很多寄存器用来给CPU存取数据
CPU中的寄存器大致上分为两大类:
- 第一类寄存器是在
CPU内部使用的,对程序员不可见。是否可见不是说寄存器是否能看得见,而是指程序员是否能使用这些寄存器。CPU内部有其运行机制,因此CPU中就会有一些寄存器用于支持CPU去运行这些机制。这些寄存器对外是不可见的,我们无法使用它们来进行诸如加减乘除等通用计算。这些寄存器有专门的用途,例如:全局描述符表寄存器GDTR用于支持保护模式运行(8086上没有,后续的80386就有了)、中断描述符表寄存器IDTR用于支持中断机制、局部描述符表寄存器LDTR用于支持保护模式运行、任务寄存器TR、控制寄存器CR0~CR3、指令指针寄存器IP、标志寄存器flags、调试寄存器DR0~DR7 - 第二类寄存器是对程序员可见的寄存器,即我们进行汇编语言程序设计时,能够直接操作的寄存器,如
段寄存器(CS、DS、SS)、通用寄存器(AX、BX、CX、DS)
虽然说第一类的程序是不可见寄存器,我们没办法直接使用,但是不少不可见寄存器是需要我们来进行初始化的。
此外,不管是8086中的哪一类寄存器,都是16位的
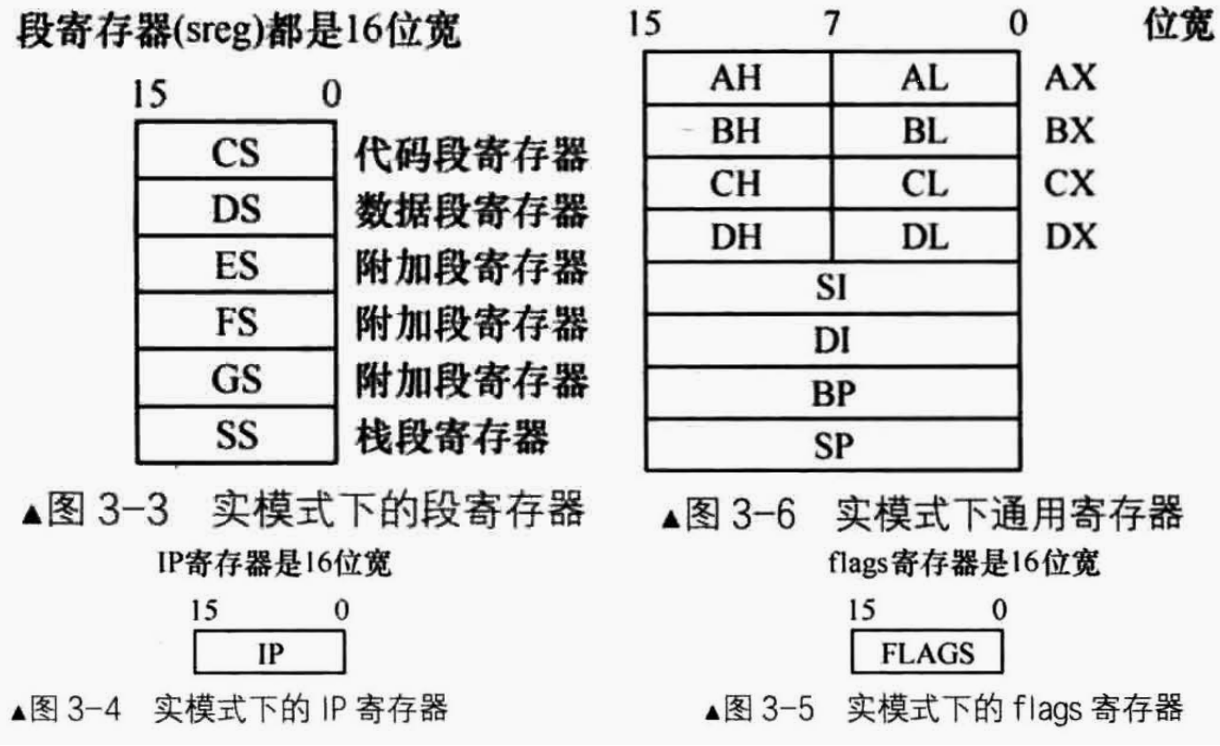
通用寄存器的介绍如下
3. 8086的内存与地址
上面我们介绍了8086中的寄存器,接下来我们介绍8086的内存以及地址。
CPU的工作模式如下:
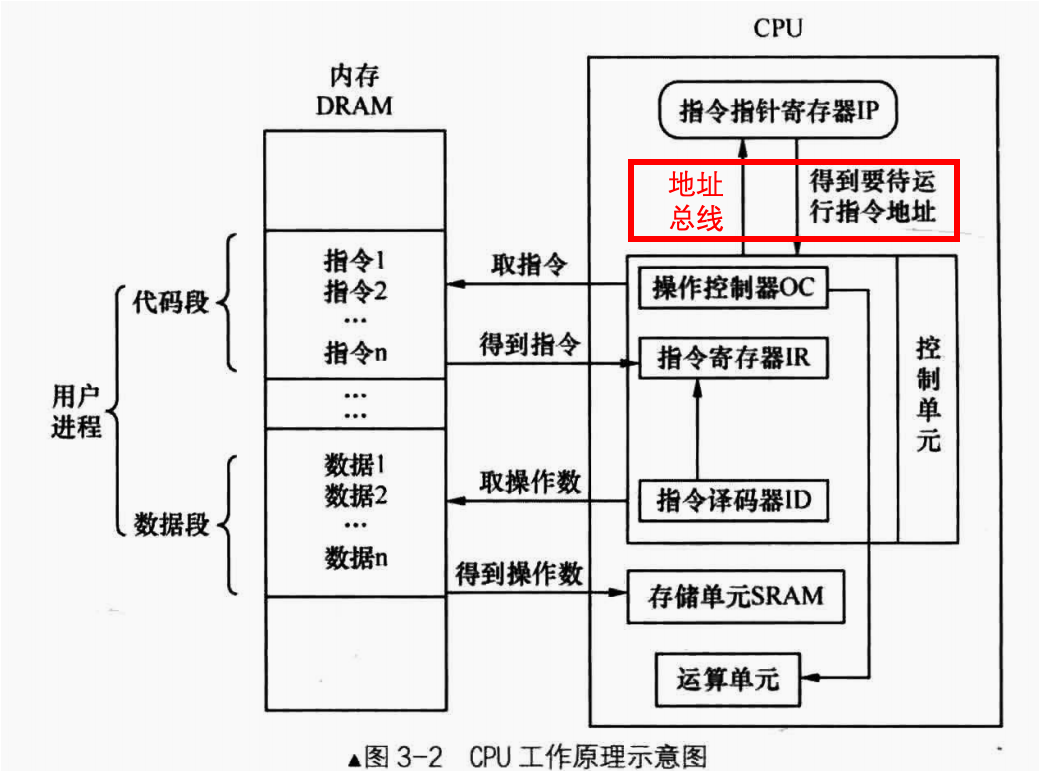
我们将需要访问的内存地址交给CPU中的控制单元,而后控制单元从内存中对应地址的内存单元中获取数据和指令。最后将获取到的指令和操作数交给运算单元进行处理。
8086中地址总线是20位宽,也就是说,8086 CPU能够用20个比特位来标识内存单元。8086 CPU中的控制单元,最多能访问$2^{20}$个内存单元。一般一个内存单元中能够储存8 Bit数据,也就是一个内存单元能储存一个字节的数据。因此,8086 CPU最多能访问$2^{20} B= 1 MB$

注意,比特位/二进制位 和 十六进制位是不同的,后面我们但凡说到位,可能是二进制位也可能是十六进制位,需要读者根据上下文去判断到底是那种位。
4. 8086访问内存
A. 内存分段式访问
我们前面说过,8086 CPU访问内存是需要给出内存的地址的。而8086支持读取1M大小的内存,因此给出的地址必须是20个比特位的。可是关键问题就是8086 CPU,内部寄存器都是 16 位的,
如果我们使用单个寄存器来保存将要访问的内存地址的话,那么我们最多只能访问到0x0000~0xFFFF,即$2^{16}=64KB$内存。
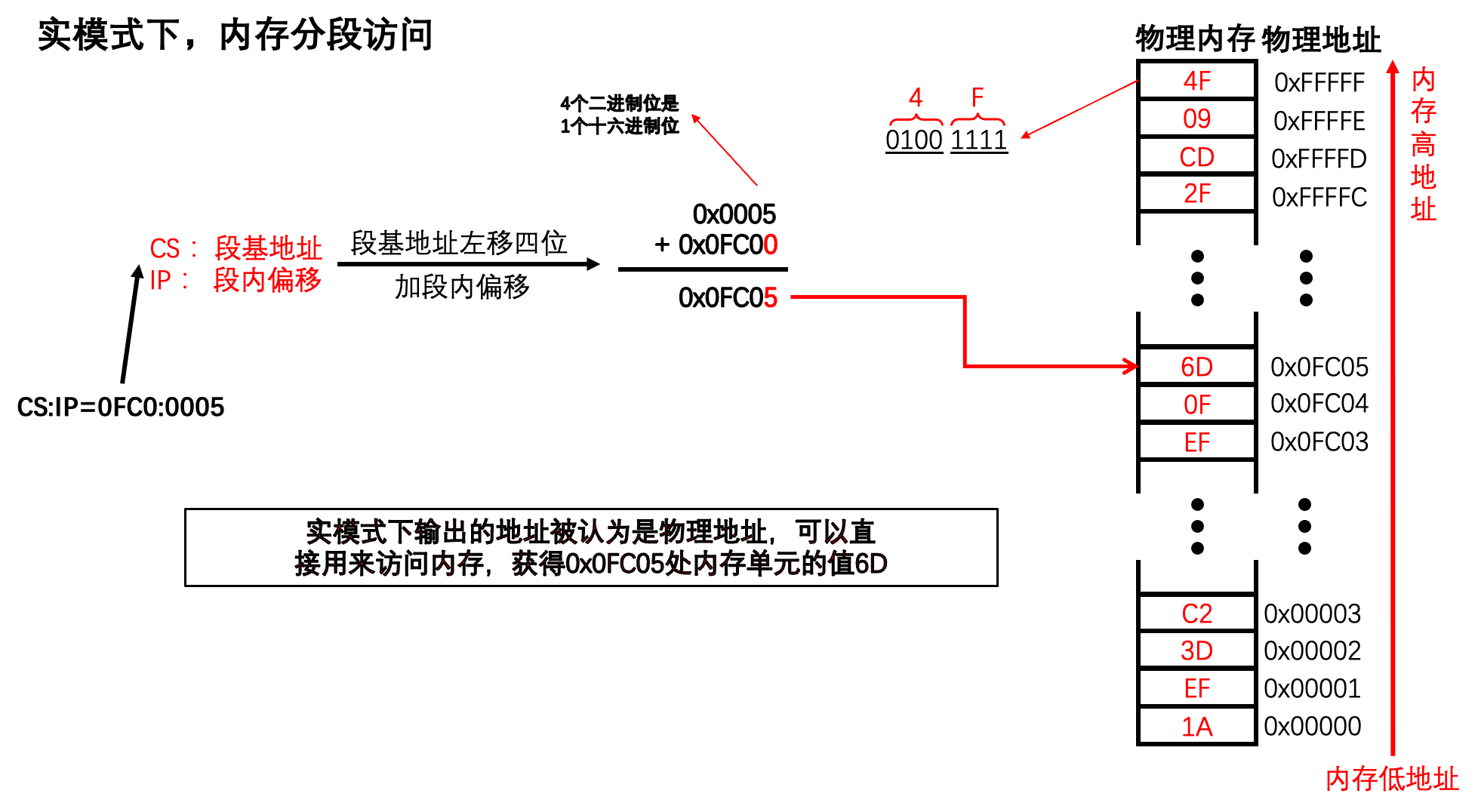
因此,为了解决寄存器宽度和内存地址宽度不匹配问题,8086采用了段基地址:段内偏移的方式来表示将要访问的地址。即将20个比特位位的内存地址,拆成高16位和低16位,分别用两个寄存器保存。而在计算将要访问的内存单元的地址时,将高16位左移四位,而后再和低16位相加,就得到了最终将要访问的内存单元的地址

上面是用二进制来解释的,用16进制来表示的话则如下:

8086这种访问内存的方式,称为内存分段式访问。
B. 内存分段表示法(段基地址:段内偏移)
一般来说,高16位地址称为段基地址/段地址,而低16位地址则称为段内偏移地址,简称为段内偏移。
之所以将高16位称为段地址,是因为,假设我们固定高十六位为0x0FC0不动,那么段内偏移地址的取值范围就是从0x0000~0xFFFF,此时我们能够访问到的内存单元的地址就是从0x0FC00~0x1FBFF。因此,在固定段地址不变的情况下,我们能够访问到64K个连续的内存单元,即能够访问到一小段连续的内存,因此高十六位才称为段地址。
高16位称为段地址理解了,那么低16位称为段内偏移就更好理解了,低16位表示了我们将要访问的内存单元在这一小段中的偏移,因此称为段内偏移地址,简称段内偏移。
因此,相比于我们直接给出一个五位的内存地址,例如0x0FC05,我们现在也可以用段基地址:段内偏移的分段表示法来表示内存单元的地址,例如0x0FC0:0x0005
而在内存分段访问的方式下,一个内存单元的地址其实有多个表示方式,例如0x0F111,可以是0x0F11:0x0001,也可以是0x0F10:0x0011,还可以是0x0F00:0x0111,甚至是0x0E00:0x1111,只要按照规则计算出来的地址是对的就可以
C. 段寄存器与基址寄存器
我们上面说,8086中将20位的内存单元地址拆分为16位的段地址与16位的段内偏移,而段地址与段内偏移分别用两个寄存器保存。
一般来说,段地址使用专门的段寄存器来保存。这是因为,段地址在使用的时候必须要左移四位(乘以16),因此将段地址保存在特殊的寄存器中,而后使用段寄存器来计算要要访问的内存单元的地址的时候默认乘以16即可。
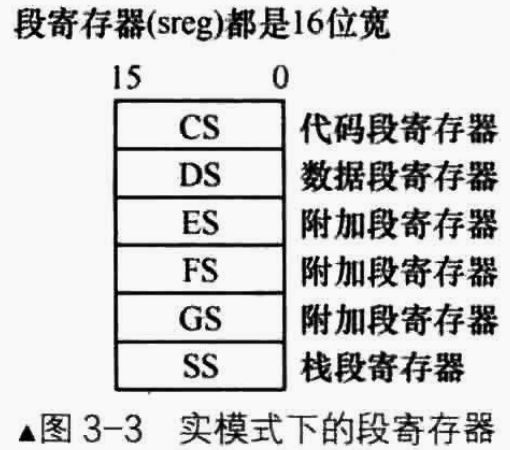
而由于低16位的段内偏移在计算的时候不需要经过特殊的计算,直接加就行了,因此可以存储在除了段寄存器以外的任何寄存器中(不严谨的说)。但是一般大家还是把段内偏移地址存储在通用寄存器中。因为通用表示既能存储加数与被加数等参与计算的数据,也能存储地址。
此外,虽然所有的通用寄存器都能存储地址,但是一般还是把地址存储在bx、si、di、sp和bp这几个寄存器中。
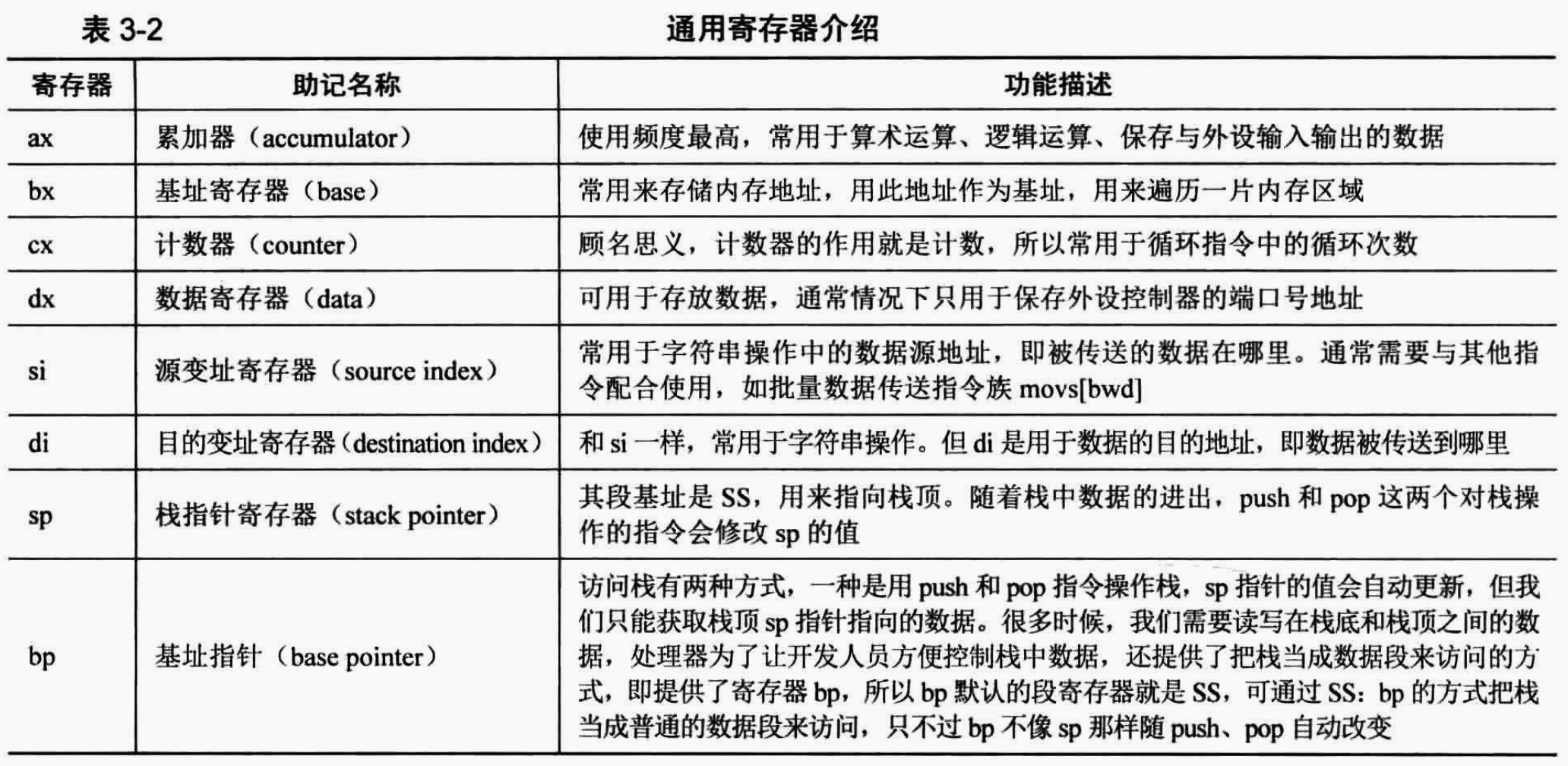
D. 段与段之间的关系
我们上面讲到,8086访问内存是按照段基地址:段内偏移的形式来访问内存的,而段基地址能够去标识一段内存。所以我们其实可以把1M的内存分成多个不同的段。那么就有一个问题,就是8086把内存分出来的多个段之间的关系到底是什么样的呢?
事实上,段与段之间的关系可以是任意的,即段与段之间的关系完全可以是下面的三种关系之一:
- 相邻
- 相离
- 相交
这是因为,段只是为了我们表示一个地址方便,方便我们能够用8086中16位的寄存器去表示出来20位的地址,因此只需要能够将20位地址表示出来即可,没有必要要求段密铺满整个内存
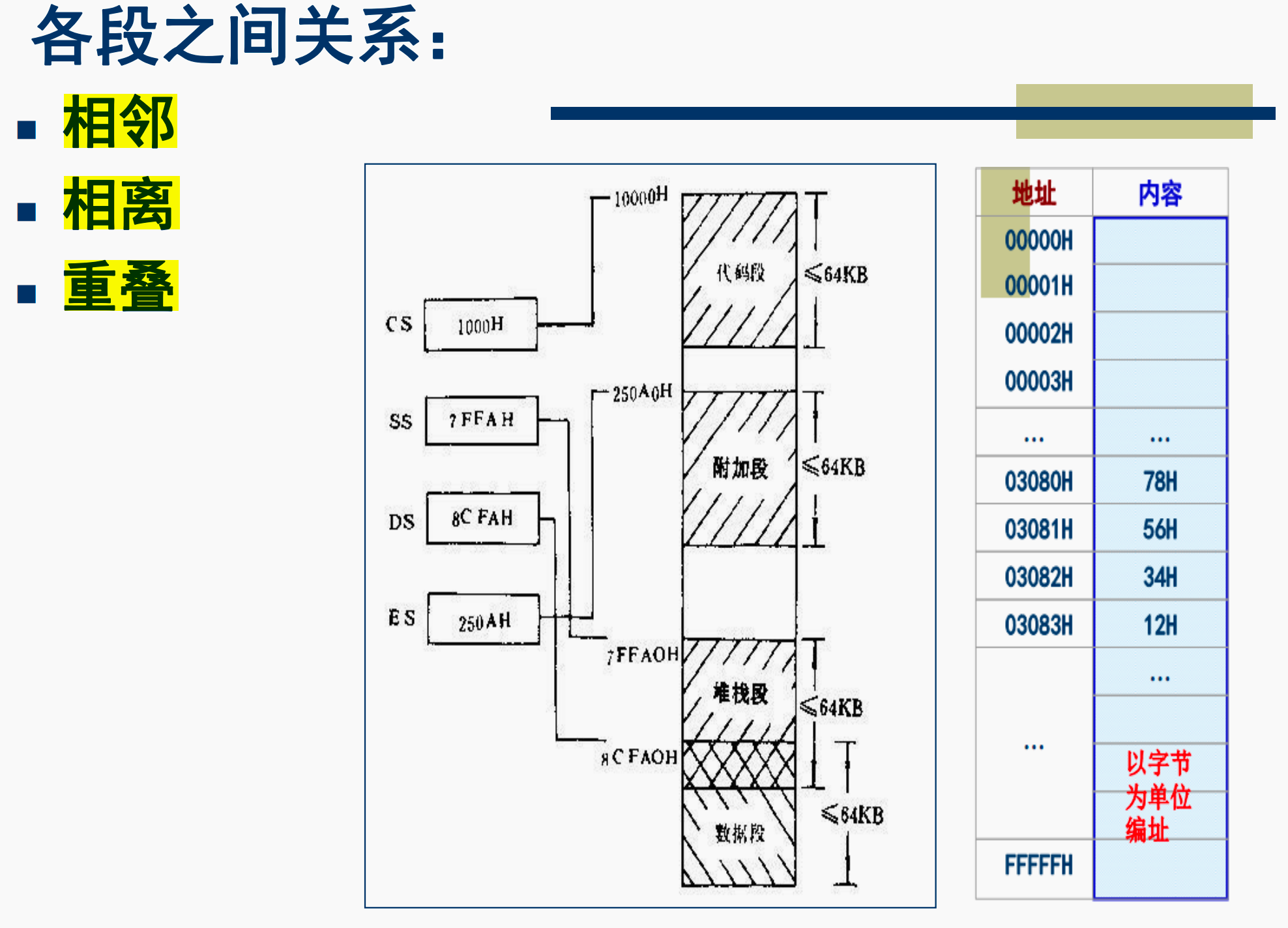
5. 总结
最后,实模式下内存的访问方式就是内存分段是访问,而我们用一张图来总结总存分段式访问:
三、保护模式下访问内存:内存分段与内存分页
我们上面讲了8086的实模式,以及实模式下CPU访问内存的方式。我们接下来就要讲保护模式了。类似于实模式是伴随Intel 8086 CPU一起诞生的,保护模式是伴随Intel 80386 CPU一起诞生的。因此,我们下面也是一百年讲解Intel 80386 CPU,一边讲解伴随Intel 80386 CPU所提出的保护模式。

1. 实模式的问题
在讲解保护模式之前,我们先讲讲实模式的优点和缺点,也只有这样我们才能更好的明白为什么会有保护模式。
实模式的优点
实模式的优点主要就是简洁、好理解。可能一个小时左右就能够学明白实模式。
实模式的缺点
实模式的缺点有很多,主要分为两个方面:
- 实模式的第一个缺点就是使用的地址都是真实的物理地址,难以支持多程序并行。如果有多个程序运行的话,多个程序都是驻留在内存中的。而由于实模式下程序使用的都是真实的物理地址,因此很有可能两个程序都要修改同一个内存单元的值。那么这样就会导致多个程序运行的结果都不会。所以实模式难以支持多个程序并行。关于不支持程序并行运行的内容,后面在分页机制中有更多的介绍。
- 实模式的第二个缺点就是不安全。实模式下,程序访问、修改一个内存单元只需要给出内存单元的地址即可。而在
8086 CPU访问地址的过程中,没有任何权限的检查,给出地址就可以访问、修改该地址对应的内存单元的内容。而由于程序可随意修改自己的段基址,因此实模式下,任何程序都可以任意访问、改变所有内存。而操作系统和用户程序一样,都是软件,在运行时都是驻留在内存中的。因此用户程序在运行的时候实际上是可以改变操作系统的程序的,因此如果用户程序写的烂的话,那么就很有可能修改了操作系统的代码,从而导致系统死机。这个时候只能断电重启,而且所有计算到一半的数据全部丢失。
事实上,实模式还有第三个缺点:
- 实模式的第三个缺点就能够访问的内存太小了。
8086 CPU的地址总线只有20位,能够访问的内存只有1M。1M的内存在1978年Intel 8086 CPU刚发售的时候还足够用,但是后来随着计算机快速的发展,1M的内存基本上很快就不够用了。所以实模式下,能够访问的内存太小了。这个缺点事实上是由于8086的地址总线只有20位,因此如果想要弥补这个问题的话,那么就必须要加大其地址总线的位数。
实模式的缺点比较多,没办法,因为实模式是最早的CPU的运行模式。而也正是因为实模式有这么多的缺点,我们需要去弥补,才推动了计算机的发展,从而就有了保护模式。
而正是为了解决8086 CPU实模式的不安全性与不支持多程序并行,80386 CPU分别提出了保护模式和分页机制。同时通过提升CPU宽度从16位到32位,解决了访问内存有限的问题。
类似于实模式是伴随8086 CPU提出的,想要学明白保护模式和分页机制,必须要先学明白80386 CPU相关的知识。下面我们就将讲解80386 CPU,而后再讲解80386 CPU伴随的保护模式与分页机制。
2. 80386的运行模式
8086 CPU作为最早的CPU,因此只能在实模式下运行。而作为后来者的80386一方面支持在保护模式下运行,另外一方面也能够在实模式下运行。
事实上,所有的后来的CPU都支持在实模式下运行,并且开机后就处于实模式下运行,必须要手动切换到保护模式才能运行在保护模式下。但是由于实模式存在的问题太多,因此绝大部分的操作系统,都只是在CPU刚上电处于实模式的时候运行操作系统加载的程序。
在完成操作系统最基础功能的加载后,就将CPU切换到保护模式下运行。
3. 80386的寄存器
8086 CPU的寄存器是16位CPU,其寄存器是16位。而80386 CPU是32位的CPU,因此80386 CPU中的寄存器是32位的。
80386 CPU作为从8086 CPU中发展出来的,其寄存器基本就是将8086 CPU中的16位寄存器扩展到了32位寄存器
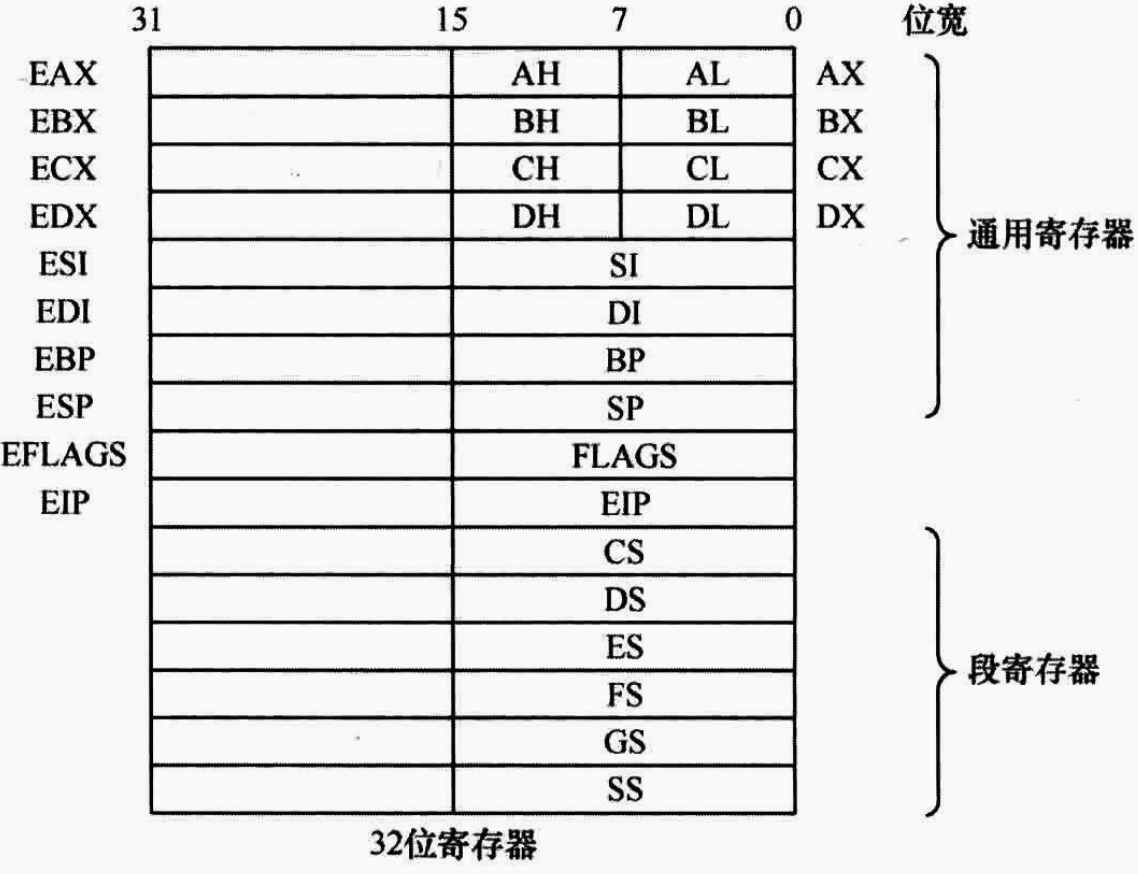
但是为了和8086 CPU兼容,因此80386 CPU是支持仅使用低16位寄存器的。所以在80386 CPU刚上电的时候,80386和8086基本没啥区别,就是运行的速度比8086快而已。
此外,关于80386中的段描述符缓冲寄存器(Descriptor Cache Register),我们这里先不讲,等后面讲完了80386访问内存的方式我们再讲这个。
4. 80386的内存和地址
80386 CPU的工作模式和8086的工作模式没有变化,都是一样的:我们将需要访问的内存地址交给CPU中的控制单元,而后控制单元从内存中对应地址的内存单元中获取数据和指令。最后将获取到的指令和操作数交给运算单元进行处理。
我们上面说过,80386乃至后来的所有的CPU,在上电之后CPU默认都是在实模式下运行的,此时所有寄存器,包括地址总线都和8086的是一样的,因此此时在实模式下的80386只能访问到内存的低端1MB内存。
在我们上电、通过手动将80386从实模式切换到保护模式后,才能够使用80386中32位的寄存器,而地址总线也从20位升级成了32位。因此,保护模式下80386最多能访问$2^{32}$个内存单元。一般一个内存单元中能够储存8 Bit数据,也就是一个内存单元能储存一个字节的数据。因此,80386 CPU最多能访问$2^{32} B= 4 GB$的内存。
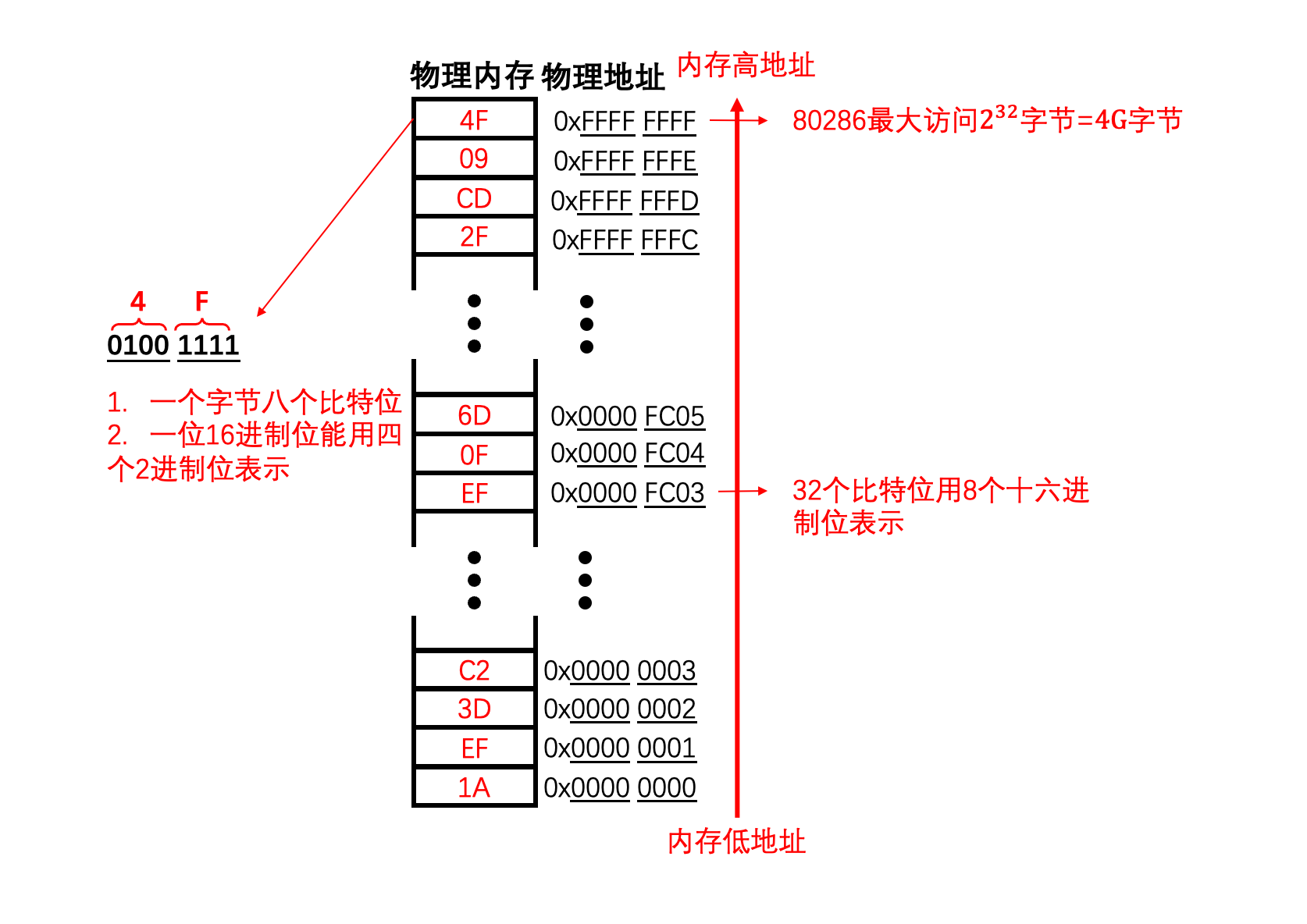
注意,比特位/二进制位 和 十六进制位是不同的,后面我们但凡说到位,可能是二进制位也可能是十六进制位,需要读者根据上下文去判断到底是那种位。
5. 80386访问内存:保护模式(未开启分页)
为了解决
8086中的不安全问题,80386提出了保护模式来解决不安全问题。
A. 如何管理权限
我们先从根源思考一下导致8086 CPU的实模式访问内存不安全的根源所在,而后再提出解决方案。
导致8086 CPU内存不安全访问的根本原因,就是因为我们将所有的段都视为同等地位的段,而没有区分段与段之间的区别。理论上来说,操作系统程序的段应该权限更高,用户程序在运行的时候不能访问操作系统程序的段,而能够访问用户程序自己的段。
所以,我们需要做的,就是为段赋予每个段的权限等级,而后修改一下计算物理地址的方式,从而在8086 CPU计算物理地址的基础上再额外进行权限检查。
因此,相比于单纯的段基地址:段内偏移的形式,80386 CPU就是使用了更加安全、高级的段描述符。
B. 段描述符(Segment Descriptor)
对于IA32架构的处理器(就是我们大多数人现在所用的处理器),访问内存采用段基地址:段内偏移形式,即使到了保护模式,为了兼容实模式,也是绕不开这个限制的,这是骨子里的问题。所以,保护模式中访问内存依旧是按照段基地址:段内偏移的方式来访问内存的。
其次,为什么淘汰了实模式而发明了保护模式?最主要的是安全问题。基于以上两方面,CPU工程师既要保证保护模式下的内存访问依然是段基址:段内偏移的形式,又要有效提高了安全性。
之前在16位模式下,访问内存时只要将段基址加载到段寄存器中,再结合偏移地址就行了,段寄存器太小了,只能存储 16 位的信息,甚至连 20 位地址都要借助左移4位来实现。现在为了安全性,总该为内存段添加一些额外的安全属性吧?问题来啦,这些用于安全方面的属性,该往哪放呢?寄存器由于只有32位寄存器,也才刚刚够存放32位地址,因此额外用于提高安全性的描述段的属性的值就没有办法放在寄存器中了。排除了寄存器,自然只剩下内存了。
相对寄存器来说,内存可是非常大的,既然有了那么大的内存可用,我们其实就可以添加更多的信息,把安全做得更加彻底一些。那么现在问题就成了:要用哪些属性来描述这个内存段呢?
首先,先要解决实模式下存在的问题:
- 实模式下的用户程序可以破坏存储代码的内存区域,所以要添加个内存段类型属性来阻止这种行为。
- 实模式下的用户程序和操作系统是同一级别的,所以要添加个特权级属性来区分用户程序和操作系统的地位。
其次,是一些访问内存段的必要属性条件:
- 内存段是 片内存区域,访问内存就要提供段基址,所以要有段基址属性。
- 为了限制程序访问内存的范围,还要对段大小进行约束,所以要有段界限属性。
最后,要改进就改得彻底一些,所以多增加了一些约束条件,这些马上就会讲到。
我们这里只是说了一小部分内存段的属性,反正零零散散,一个段的基地址加上这个段的各种属性,加起来会占不少字节呢。而这些用来描述内存段的属性被放到了一个称为段描述符(Descriptor)的结构中,顾名思义,该结构专门用来描述一个内存段,该结构是8字节大小。描述符具体得结构如下:
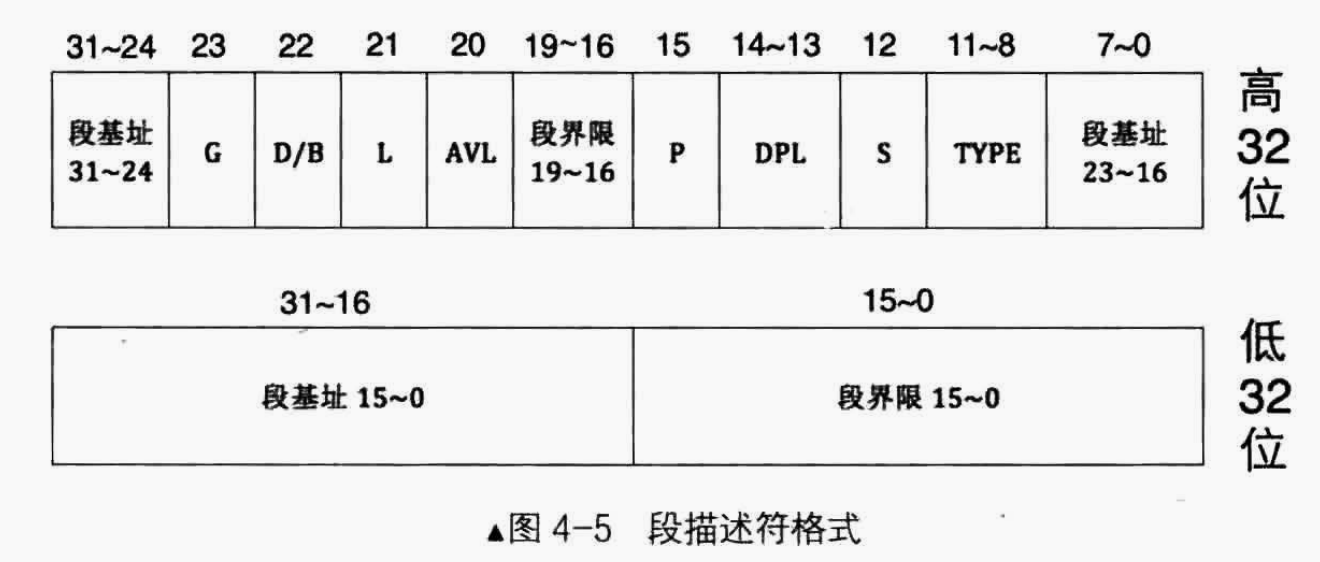
注意,段描述符是8字节大小,上面的途中为了方便展示,才将其“人为地”分成了32位和高32位,即两个4字节。而在内存中,它们是连续的8字节,这样CPU
才能读取到正确的段信息。
关于短描述符结构的解释如下:
段基地址:保护模式下地址总线宽度是 32 位,因此每个地址都是32位的。段基址也需要用32位地址来表示。但是段基地址之所以被拆成了三部分(0~23位、16-19、24~31位),这个主要是历史遗留问题。保护模式也不是一下就建立起来,也是经过了8088、80186、80188等好几代产品的发展,所以才导致了段基地址被拆成了三部分。段界限表示段边界的扩展最值,即当前段向高字节最大能访问到那里,或向低字节最小访问到那里扩展方向只有上下两种。对于数据段和代码段,段的扩展方向是向上,即地址越来越高,此时的段界限用来表示段内偏移的最大值。对于栈段,段的扩展方向是向下,即地址越来越低, 此时的段界限用来表示段内偏移的最小值。无论是向上扩展,还是向下扩展,段界限的作用如同其名,表示段的边界、大小、范围。段界限用 20 个二进制位来表示。
段界限有两种不同的单位,它的单位要么是字节,要么是4KB。当前段的短界限的单位到底是字节还是4KB取决于描述符中的G位来指定的。因此当前段的大小计算就是:$段界限值\times单位$,故段的大小要么是$2^{20}\ Byte = 1\ MB$,要么是$2^{20} \times 2^{12} Byte= 2^{32}Byte=4\ GB$
- 段接线被拆成两部分也是由于历史问题。
G位表示段界限的粒度。G=1则段界限单位为4KB,此时当前段1M。如果G=0位为 ,表示段界限粒度大小为1字节。S位表示当前段时系统段还是用户段。S=0则表示当前段位系统段,S=1则表示当前段位用户段。type字段目前用不到,后面再讲。DPL字段(Descriptor Privilege Level) ,即描述符特权级,这是保护模式提供的安全解决方案,将计算机世界按权力划分成不同等级,每一种等级称为一种特权级。这两位能表示4种特权级,分别是0~3级特权,数字越小,特权级越大。特权级是保护模式下才有的东西,CPU由实模式进入保护模式后,特权级自动为0。因为保护模式的代码已经是操作系统的一部分,所以操作系统应该处于最高的特权级。用户程序通常处于3特权级,权限最小。某些指令只能在0特权级下执行,从而保证了安全。P字段(Present) ,即段是否存在。如果段存在于内存中,则P=1,否则P=0。P宇段是由CPU来检查的,如果为0,CPU将抛出异常,转到相应的异常处理程序,此异常处理程序是咱们来写的,在异常处理程序处理完成后(即将段从外存中调入到内存的之后)要将P设置为1。也就是说,对于P宇段, CPU 只负责检查,咱们负责赋值。不过在通常情况下,段都是在内存中的AVL字段(AVaiLable) ,用来表示当前段是否是可用的。不过这可用是对用户来说的,操作系统可以随意用此位。对硬件来说,它没有专门的用途,这个是专门给软件使用的。L字段(Length),用来表示当前段是否是64位代码段。L=1表示当前段为64位代码段,否则表示32位代码段。这目前属于保留位,因为我们目前讨论的是32位的CPU,所以这一位为0便可。D/B字段,用来指示有效地址(段内偏移地址)及操作数的大小。- 有没有觉得奇怪,实模式己经是32位的地址线和操作数了,难道操作数不是32位大小吗?其实这是为了兼容
80286 CPU的保护模式,80286 CPU的保护模式下的操作数是16位。既然是指定“操作数”的大小,也就是对“指令”来说的,与指令相关的内存段是代码段和枝段,所以此字段是B。对于代码段来说,D=0表示指令中的有效地址和操作数是16位,段内偏移用IP寄存器。若D=1表示指令中的有效地址及操作数是 32 位,段内偏移用EIP寄存器。 - 对于栈段来说,此位是
B位,用来指定操作数大小,此操作数涉及到栈指针寄存器的选择及栈的地址上限。若B=0,则使用的是sp寄存器,也就是栈的起始地址是 16 位寄存器的最大寻址范围,0xFFFF。若B=1,则使用的是esp寄存器,也就是栈的起始地址是32位寄存器的最大寻址范围,0xFFFFFFFF
- 有没有觉得奇怪,实模式己经是32位的地址线和操作数了,难道操作数不是32位大小吗?其实这是为了兼容
补一个短描述符指向内存的图
C. 全局段描述符表与GDTR寄存器
一个段描述符只用来定义(描述)一个内存段。代码段要占用一个段描述符、数据段和战段等,多个内存段也要各自占用一个段描述符,这些描述符放在哪里呢?答案是放在全局描述符表(Global Descriptor Table, GDT)中。全局描述符表相当于是描述符的数组,数组中的每个元素都是8字节的描述符。可以用选择子(马上会讲到)中提供的下标在GDT中索引描述符。
为什么将该表称为全局段描述符表?全局体现在多个程序都可以在全局段描述符表中添加自己的段描述符,因此全局段描述符表是系统公用的,因此称为全局段描述符表。
全局描述符表位于内存中,需要用专门的寄存柑旨向它后,CPU才知道它在哪里。这个专门的寄存器便是GDTR,即GDT Regiter,专门用来存储GDT的内存地址及大小。 GDTR是个48位的寄存器,其结构如下:
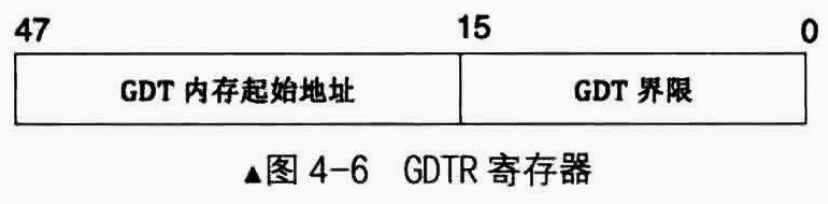
事实上,我们在最前面介绍过CPU中的寄存器分为两类,一类是程序员可见的寄存器,用于完成通用的计算,另外一类是程序员不可见的寄存器,用于支持CPU运行的机制,程序员只负责初始化。GDTR寄存器就是程序员不可见的寄存器中的一种。
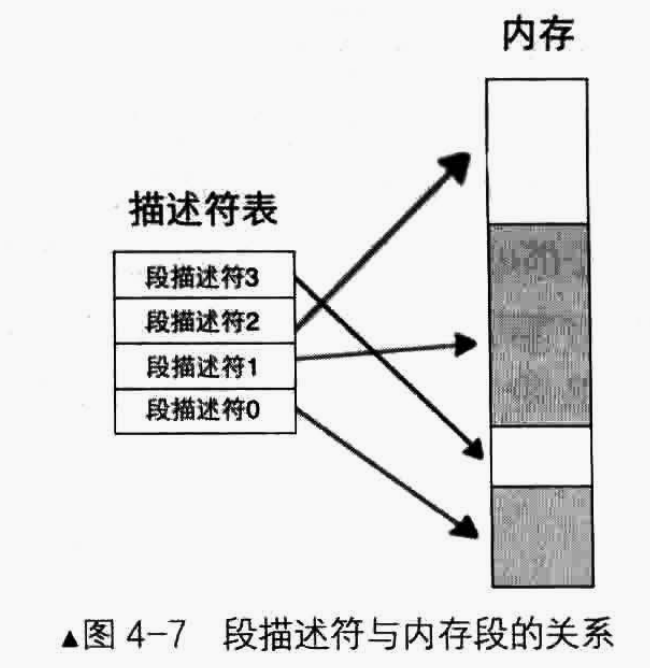
D. lgdt指令
而对于GDTR寄存器的初始化,不能够用mov gdtr这样的汇编指令进行初始化,有专门的指令来做这件事,这就是lgdt指令。lgdt是专门用于设置GDTR寄存器的指令。而lgdt这个指令非常特殊,我们在前面说任何CPU刚上电都是处于实模式,需要用户手动切换到保护模式中去,因此lgdt这个指令就是在实模式下运行的指令,而设置GDTR寄存器就是从实模式到保护模式需要干的事之一。
但事实上,进入保护模式需要有GDT,但进入保护模式后,可能还要重新加载一个新的GDT。在保护模式下重新换个GDT的原因是实模式下只能访问低端1MB空间,所以GDT只能位于低端1MB之内。但在进入保护模式后,访问的内存空间突破了1MB的限制,根据操作系统的实际情况,有可能需要把GDT放在内存的其他位置上,因此在进入保护模式之后,可能还需要重新加载GDTR寄存器,因此lgdt指令实际上既能在实模式下运行,也能在保护模式下运行。
ldgt指令的格式如下
lgdt 48位内存数据
之所以是48位内存数据,主要就是GDTR寄存器是48位的,6个字节。因此lgdt指令后面其实只需要给第一个字节的内存单元地址即可,CPU会自动的读取6个字节。
E. 段选择子:段内偏移
段描述符有了,描述符表也有了,我们该如何使用它呢?下面我们引出新的概念段选择子。
段寄存器CS/DS/ES/FS/GS/SS,在实模式下时,存储的是段基地址,即内存段的起始地址。而在保护模式下时,由于段基址已经存入了段描述符中,所以段寄存器中再存放段基址是没有意义的,此时在段寄存器中存入的是一个称为选择子(Selector)的东西。
选择子本质上就是一个索引值(其实还有其他属性)。用此索引值在段描述符表中索引就可以得到相应的段描述符,这样,便在段描述符中得到了内存段的起始地址和段界限值等相关信息。因此,在保护模式下,我们访问内存依旧是通过内存分段的方式访问的内存,但是不同的是,此时是段选择子:段内偏移的形式去访问内存的
实模式下段选择子的结构如下:

由于实模式下段寄存器是16位,所以段选择子也是16位。
- 段选择子低2位即第
0~1位,用来存储RPL(Request Privilege Level),即请求特权级,可以表示0~3四种特权级。关于RPL可以简单的理解为请求者的当前特权级(不理解也没关系,因为我们这里着重讲解访问内存的方式,在这里他不重要) - 段选择子的第2位是
TI位,即Table Indicator,用来指示选择子是在GDT中,还是LDT中索引描述符(LDT我们稍后就会讲到)。TI=0表示在GDT中索引描述符,TI=1表示在LDT中索引描述符 - 选择子的高13位,即
3~15位是描述符的索引值,用来在GDT中索引描述符(TI=0时)。前面说过GDT相当于一个描述符数组,所以选择子中的索引值就是GDT中的下标。
需要注意的是,由于实模式下选择子的索引值有13位,而$2^{13}=8192$ ,故实模式下,段选择子最多可以索引8192个段,因此实模式下GDT中最多定义8192个描述符。
选择子的作用主要是确定段描述符,确定描述符的目的,一是为了特权级、界限等安全考虑,最主要的还是要确定段的基地址。虽然到了保护模式,但IA32架构始终脱离不了内存分段,即访问内存必须要用段基址:段内偏移地址的形式。保护模式下的段寄存器中已经是选择子,不再是直接的段基址。段基址在段描述符中,用给出的选择子索引到描述符后,CPU自动从段描述符中取出段基址,这样再加上段内偏移地址,便凑成了段基址:段内偏移地址的形式
所以在保护模式下,我们就从原本最简单的段基地址:段内偏移的形式转变成了段选择子:段内偏移的形式。而且由于段描述符中的段基地址就是32位的,因此不需要再将段基址乘以16后再与段内偏移地址相加。
举个例子:
假设选择子是
0x8,将其加载到ds寄存器后,访问ds:0x9所对应的内存单元。其过程为:
- 拆分选择子。
0x8的0~1位是RPL位,其值为00。第2位是TI位,其值表示是在GDT中索引段描述符还是在LDT中索引段描述符。这里TI=0所以就是在GDT中索引段描述符。用0x8的高13位0x1在GDT中索引。- 索引段描述符。这里高13位是
0x1,因此索引的就是也就是GDT中的第1个段描述符(GDT中第0个段描述符故意置空,是不能用的,因此可用的段描述符从索引1开始)。- 拼接段基地址和段内偏移。假设第
1个段描述符中的3个段基址部分,拼接后的值为0xl234,则CPU将0xl234作为段基址,与段内偏移地址0x9相加,0x1234+0x9=0x123D- 访问内存地址。用所得的和
0xl23D作为访存地址,开始访问注意,我们上面故意忽略了诸如
PRL特权检查等等步骤,是为了强调最终物理地址获取的流程
上面例子中提到了GDT中的第0个段描述符是不可用的,原因是定义在GDT中的段描述符是要用选择子来访问的,如果使用的选择子忘记初始化,选择子的值便会是0 ,这便会访问到第0个段描述符。为了避免出现这种因忘记初始化选择子而选择到第0个段描述符的情况, GDT中的第0个段描述符不可用。也就是说,若选择到了GDT中的第0个段描述符,处理器将发出异常。
F. 局部段描述符表
按理说全局段描述符强调全局就是为了和局部区别开,那么我们就会问到底有没有局部段描述符表?还真有。
局部描述符表(Local Descriptor Table,LDT) ,它是CPU厂商为在硬件一级为原生支持多任务而创造的表。按照硬件厂商的设想,一个任务对应一个 LDT 。然而,在现代操作系统中很少有用 LDT 的,属实是硬件厂商的意淫了。所以这里就捎带着说一下,点到为止。
CPU厂商建议每个任务的私有内存段都应该放到自己的段描述符表中,该表就是 LDT,即每个任务都有自己的 LDT 。随着任务切换,也要切换相应任务的LDT。LDT也位于内存中,其地址需要先被加载到某个寄存器后,CPU 才能使用LDT,该寄存器是LDTR,即LDT Register。同样也有专门的指令用于加载LDT,即lldt。以后每切换任务时,都要用lldt指令重新加载任务的私有内存段。
LDT虽然是个表,但其也是一片内存区域,所以也需要用全局段描述符(即GDT中的描述符)在GDT中先注册。段描述符是需要用选择子去访问的。故lldt的指令格式为:
lldt 16位寄存器/16为内存
无论是寄存器,还是内存,其内容一定是个选择子,该选择子用来在GDT中索引LDT的段描述符。
LDT被加载到LDTR寄存器后,之后再访问某个段时,选择子中的TI位若为1 ,就会用该选择子中的高13位在LDTR寄存器所指向的LDT中去索引相应段描述符。
LDT中的段描述符和GDT中的一样,与GDT不同的是LDT中的第0个段描述符是可用的,因为访问内存时提交的选择子中的TI位,TI位用于指定GDT,还是 LDT,TI=1 则表示在LDT中索引段描述符,即必然是经过显式初始化的结果,完全排除了忘记初始化的可能。
G. 总结
在保护模式下,未开始分页机制时,通过段选择子:段内偏移这一访问内存的方式流程我们上面就全部讲解完了。
总结如下:
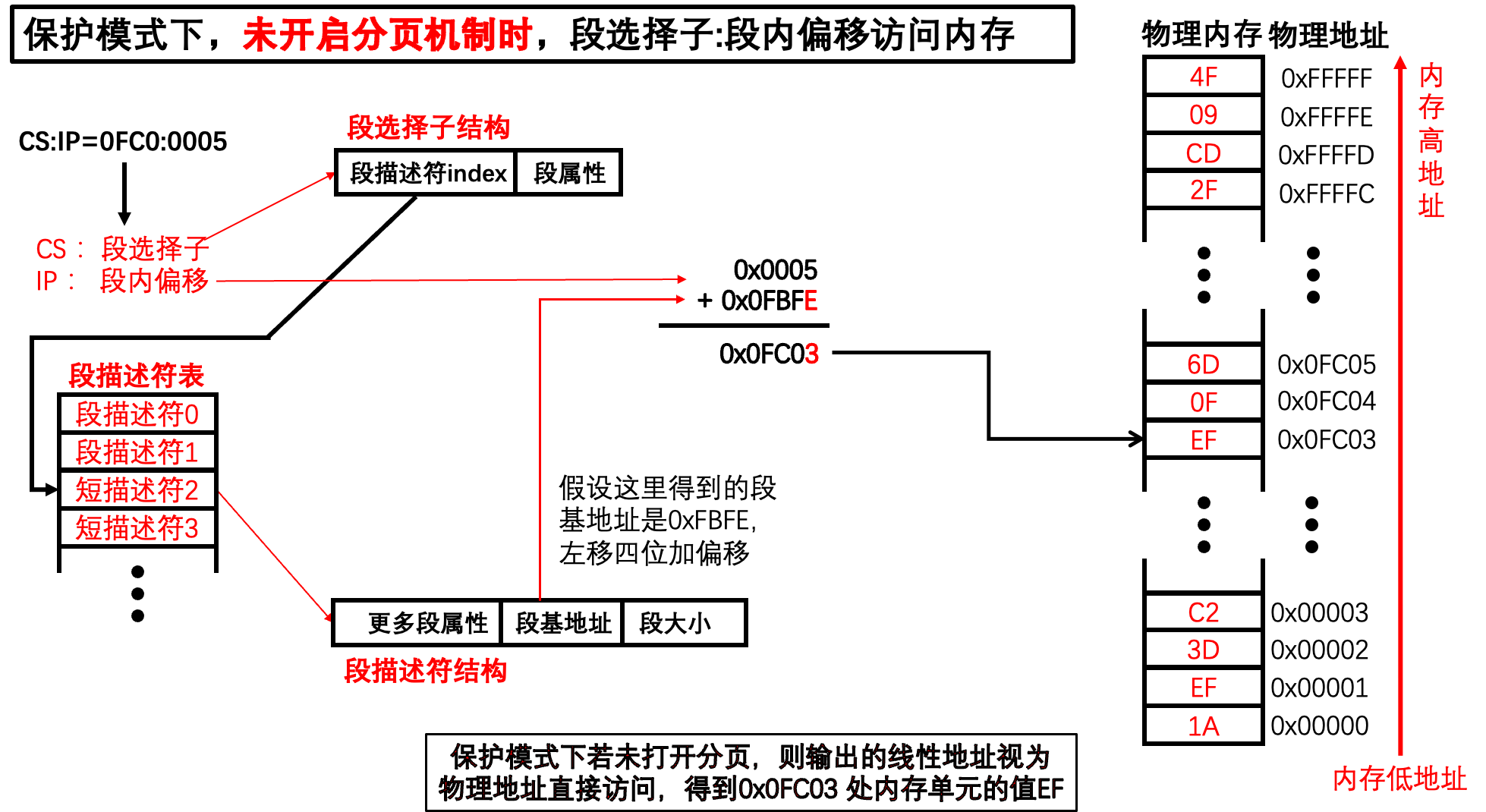
6. 80386访问内存:保护模式(开启分页)
为了解决
8086不支持多程序并行运行问题,80386在保护模式的基础上提出了分页机制来解决程序并行运行问题。
我们在上面说到,8086 CPU存在的最大的两个问题,一个是安全性问题,另外一个就是不支持多程序并行运行。80386中使用保护模式主要是解决了安全性问题,但是即便是保护模式,也依旧没有解决并行运行问题。
为了解决并行运行问题,80386 CPU中还提出了分页机制。
再开始讲解分页机制之前,我们需要明白的是,分页机制和保护模式两者并不是互相冲突的,也就是说并不是开启了保护模式就不能使用内存分页机制,使用内存分页机制就不能开启保护模式。相反,内存分页机制是建立在保护模式基础上的,内存分页机制就是为了提高保护模式不支持多程序并行运行的问题才提出来的。
A. 内存分段机制的问题:内存碎片
前面不管是实模式还是保护模式,我们访问内存都是通过内存分段的方式进行的。即将内存中的某一小段连续的内存分配给某个进程使用,而后该进程就使用这段内存。
可是,我们在最前面说内存分段机制不支持多个程序并行运行,我们通过举下面的例子来进行说明。
我们模拟多个进程并行的情况。
- 在第1步中,系统里有3个进程正在运行,进程
A、B、C各占10MB、20MB、30MB内存,物理内存还剩下15MB可用- 到了第2步,此时
进程B己经运行结束,腾出20MB的内存,可是待加载运行的进程D需要20MB+3KB的内存空间,即20483KB。现在的运行环境未开启分页功能,“段基址+段内偏移”产生的线性地址就是物理地址,程序中引用的线性地址是连续的,所以物理地址也连续。虽然总共剩下35MB内存可用,可问题是明摆着的,现在连续内存块只有原来进程B运行结束后释放的20MB和最下面可用内存15MB,哪一块都不够进程D用,这时候进程D就无法运行
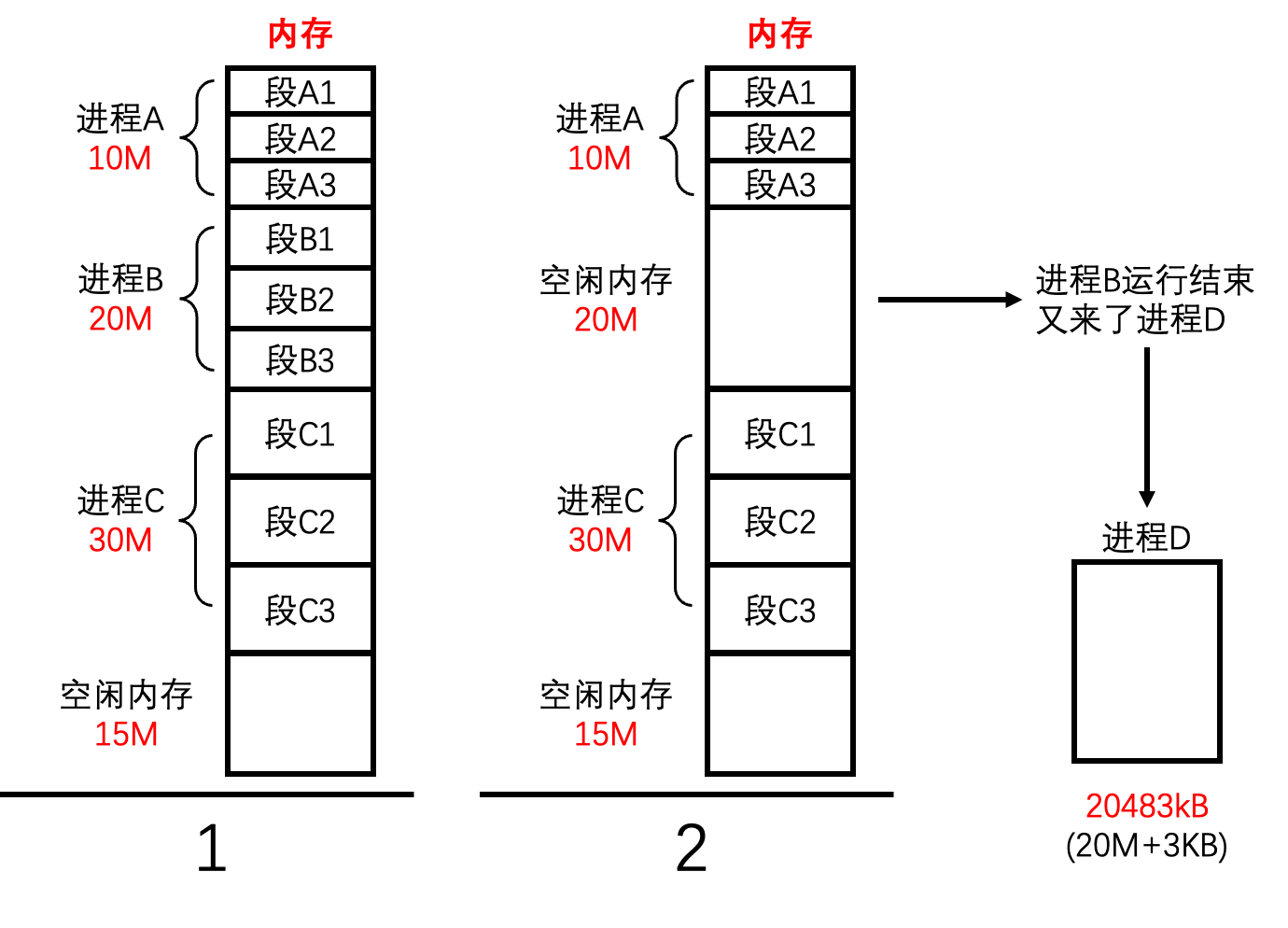
明明空闲的内存是足以容纳新的进程来运行的,但是现实情况就是我们没有足够的连续的内存来运行新的进程。实际上,这就于内存分段机制最大的问题:内存分段机制会造成内存碎片,从而降低了内存的使用率以及降低了并发性。
为了提高并发性(即让上面的进程D运行),我们有很多的方法,第一个方法就是把暂时不用的进程从内存挪出到外存中,这样就有足够的内存空间容纳新的进程(如果换出的进程不好的话还是会没有足够的内存空间),但是这个方法不是我们这里要关注的重点,我们接下来讲从另外一个角度来解决这个问题。
B. 内存分页机制
问题的本质是在目前只分段的情况下, CPU认为线性地址等于物理地址。而线性地址是由编译器编译出来的,它本身是连续的,所以物理地址也必须要连续才行,但在内存分段的机制下,我们可用的物理地址不连续。换句话说,如果线性地址连续,而物理地址可以不连续,不就解决了吗?
按照这种思路,我们首先要做的是解除线性地址与物理地址一一对应的关系,然后将它们的关系重新建立。通过某种映射关系,可以将线性地址映射到任意物理地址。
所以,我们只需要在段部件计算的基础上,在加一层映射,将段部件输出的连续的线性地址映射为不连续的物理地址。此时段部件的线性地址页称为虚拟地址
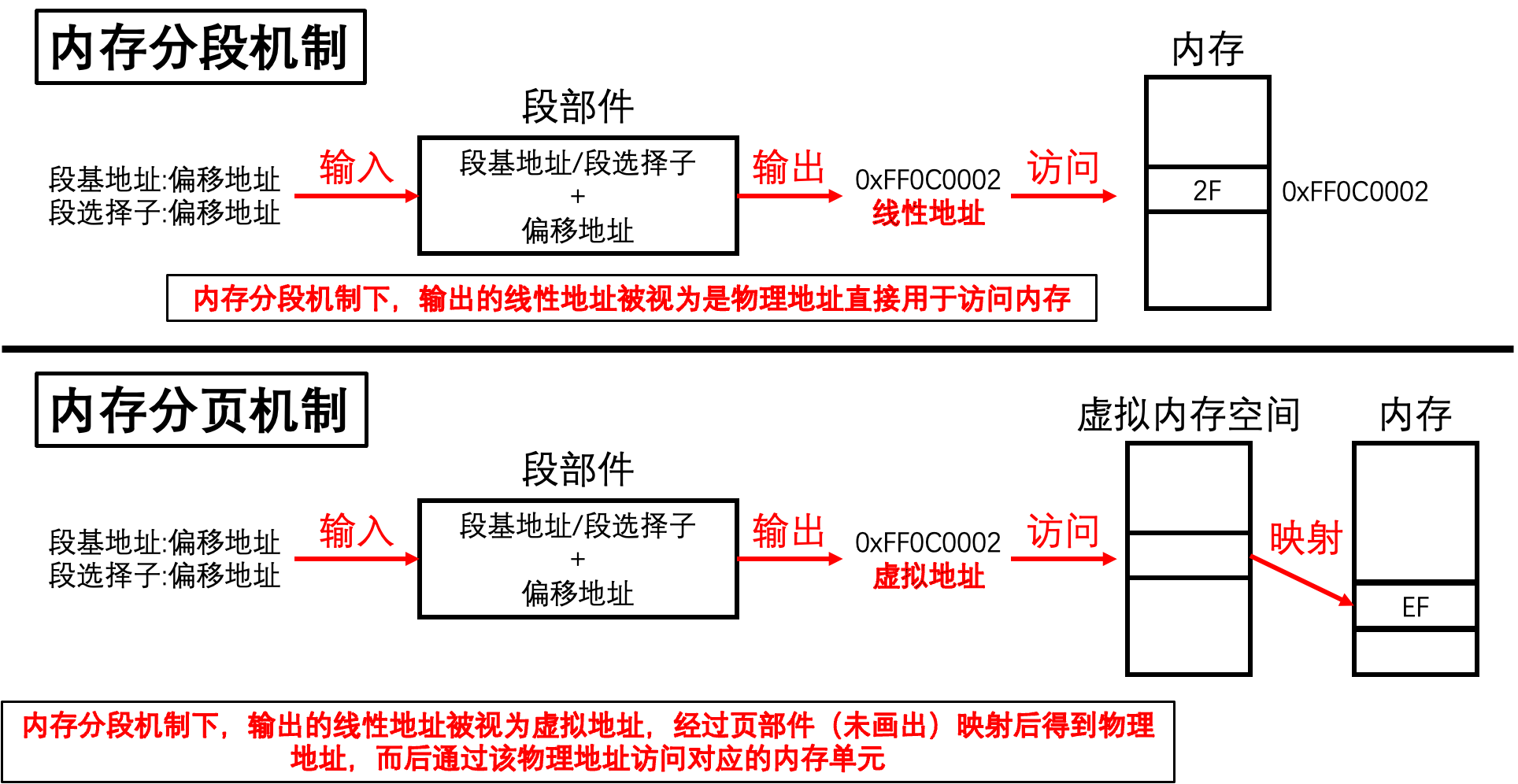
因此,在带上分页机制一起说的话,此时80386访问内存的机制为:
为了讲明白分页机制,我们下面将从两个方面来讲解:
- 分页机制的原理
- 页表的结构
C. 分页机制(一级页表)的原理
想整明白分页机制的原理,就得整明白映射。分页机制中最重要的就是映射。
映射这个概念大家应该比较清楚,对应的英文单词是
map。本质上就是通过函数f将元素A映射为B。即B=f(A),函数f可以是查表,也可以诸如哈希函数线性相乘取余。
逐字节映射
在内存地址中,最简单的映射方法是逐字节映射,即一个线性地址对应一个物理地址。比如线性地址0x0,其对应的物理地址可以是0x0、0x10 或其他你喜欢的数字。若线性地址为0x1,对应的物理地址0xl、0x11 或其他你喜欢的数字。
但是不管怎么说,我们需要找个地方来存储这种映射关系, 这个地方就是页表(Page Table )。页表就是一个N行1列的表格,页表中的每一行(只有一个单元格)称为页表项(Page Table Entry,PTE),其大小是4字节,页表项的作用是存储内存物理地址。当访问一个线性地址时,实际上就是在访问页表项中所记录的物理内存地址。
下图表示了逐字节映射方式下页表和物理内存的关系,即一个页表项指向一个物理内存。
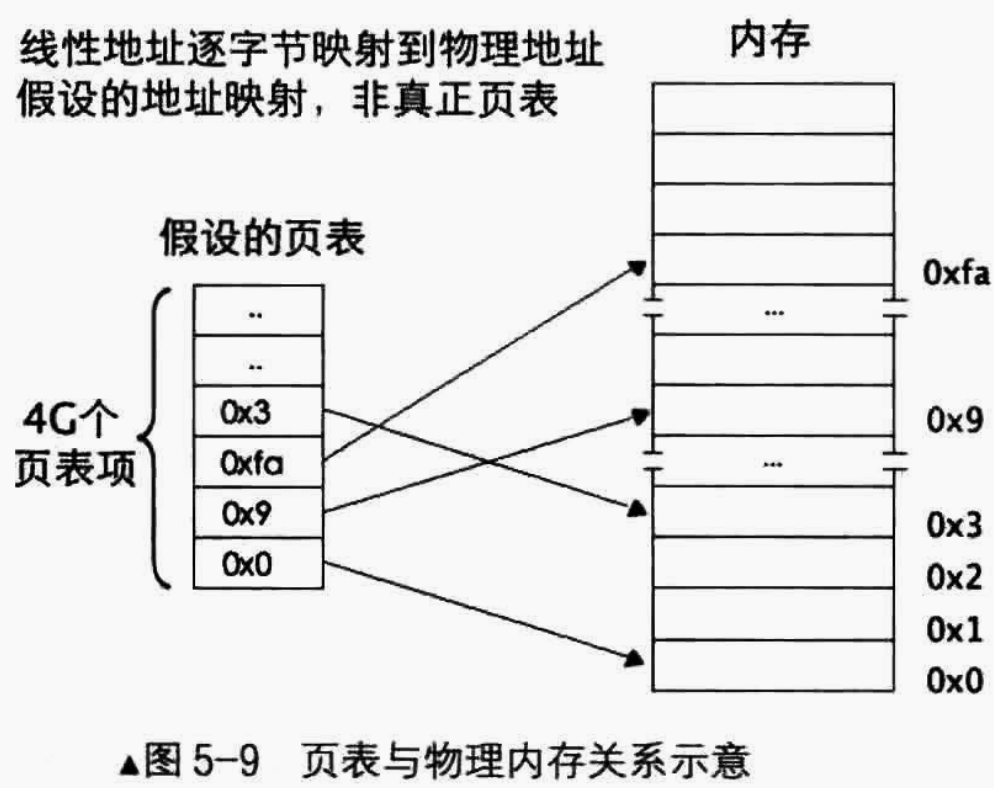
但是,逐字节映射这样的方式有很大的问题:
- 因为有4G个物理内存单元,因此页表中就应该有 4G 个页表项
- 32位的物理地址要用4个字节的页表项来存储,那么页表总共大小是$4Byte * 4G=16GB$
分页机制本质上是将大小不同的大内存段拆分成大小相等的小内存块。以上方案其实就是将4GB间划分成4G个内存块,每个内存块大小是1字节。但页表也是存储在内存中的,若按此逐字节映射的方案,光是页表就要占16GB内存,得不偿失,显然方案不合理。
逐块映射
任意进制的数字都可以分成高位部分和低位部分,若将低位部分理解为单位内存块大小,高位部分则是这种内存块的数量。例如六万的十进制可表示为60000 ,也可以表示为60千,也就是将60000分成高位60和低1000两部分。
类似的,32位地址表示4GB空间,我们也可以可以将32位地址分成高低两部分,低地址部分是内存块大小,高地址部分是内存块数量。它们是这样一种关系:内存块数*内存块大小=4GB 。
形象的理解为:有一个滑块在32位地址上左右滑动。滑块右边是内存块尺寸,滑块左边是内存块数量。
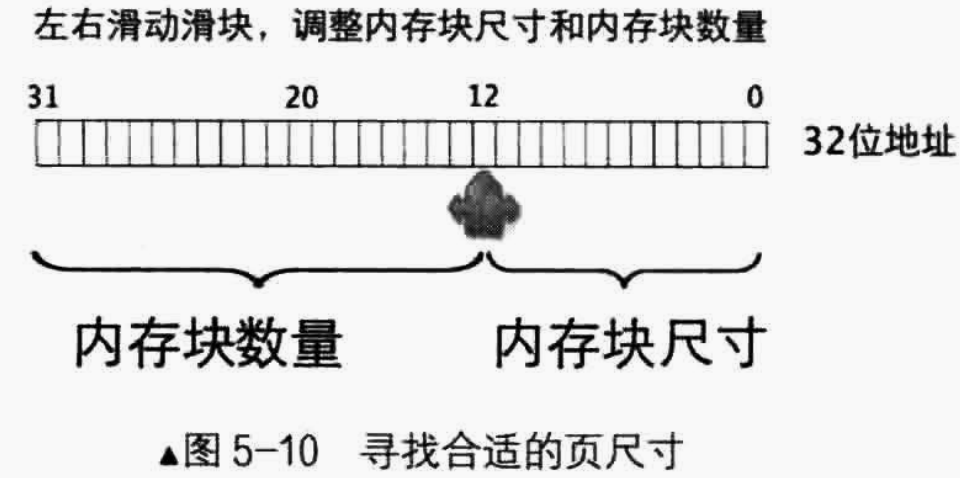
而页表的大小则是:4 Byte * 内存块数量,因此,为了降低页表的大小,我们就需要左右移动滑块找到合适的内存块尺寸。
如果滑块指向第20位,内存块大小为$2^{20}$次方,即1MB,内存块数量为$2^{12}$个,即4K个。若滑块指向第12位,内存块大小则为$2^{12}$次方,即4KB,内存块数量则为$2^{20}$个,1M个 ,即1048576 个。
这里所说的内存块,其官方名称是页(Page), CPU 中采用的页大小恰恰就是4KB,也就是上图中滑块的落点处。
页是地址空间的计量单位,并不是专属物理地址或线性地址,只要是4KB的地址空间都可以称为一页,所以线性地址的一页也要对应物理地址的一页。一页大小为 4KB ,这样一来,4GB地址空间被划分4GB/4KB=1M个页,也就是4GB空间中可以容纳1048576个页,页表中自然也要有1048576个页表项,这就是一级页表模型。
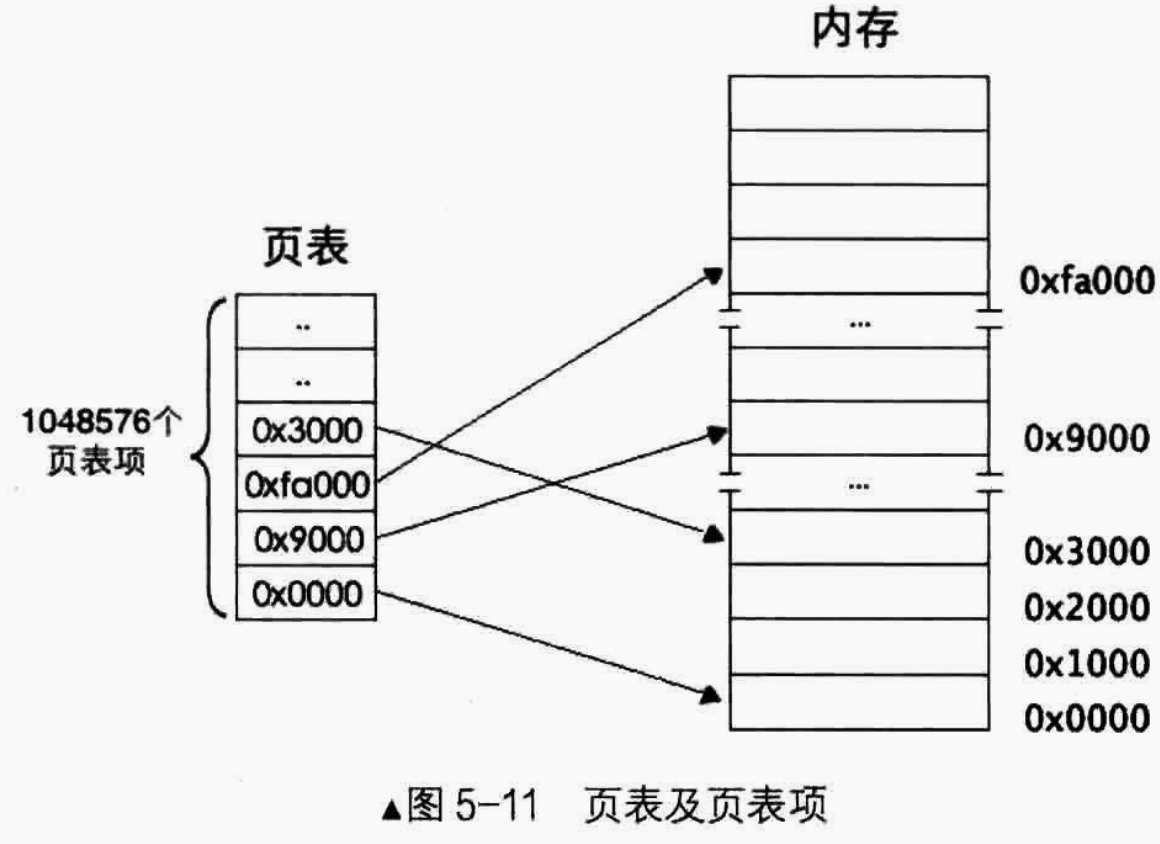
一级页表模型
下图所示是一级页表模型,由于页大小是4KB,所以页表项中的物理地址都是4K的整数倍,故用十六进制表示的地址,低3位都是0。就拿第3个页表项来说,其值为0x3000 ,表示该页对应的物理地址是0x3000
地址转换
我们上面介绍了一级页表模型,其中每4K个内存单元组成一个页,每个内存单元是1个字节,所以一个页就是4KB,而一共有1M个页。
可是,我们有个问题,就是:页表如何使用?或者说如何通过页表将线性地址转换成物理地址?这个还是得用上面的图来帮助我们理解。
滑块正落到在32位地址的第12位。右边第11~0位用来表示页的大小,也就是这12位可以作为页内寻址,因此称为页内偏移。左边第31~12位用来表示页的数量,同样这20位也可以用来索引一个页(索引范围0x00000~0xfffff),表示第几个页,因此称为页索引。
经以上分析,虚拟地址的高20位可用来定位一个物理页,低12位可用来在该物理页内寻址。所以现在问题就变成了:给定虚拟地址,如何获取这个虚拟地址对应的物理页的地址?
其实这也很简单:
- 页表项中保存了物理页的地址,而页表项位于内存中,所以只要提供页表项的物理地址便能够访问到页表项。
- 页表项保存在页表中。页表本身是线性表这种数据结构,相当于页表项数组,访问其中任意页表项成员,只要知道该表页项的索引(下标)就够了
因此,为了获得虚拟地址对应的物理页的地址,我们只需要得知指向该物理页的页表项在页表中的索引即可。
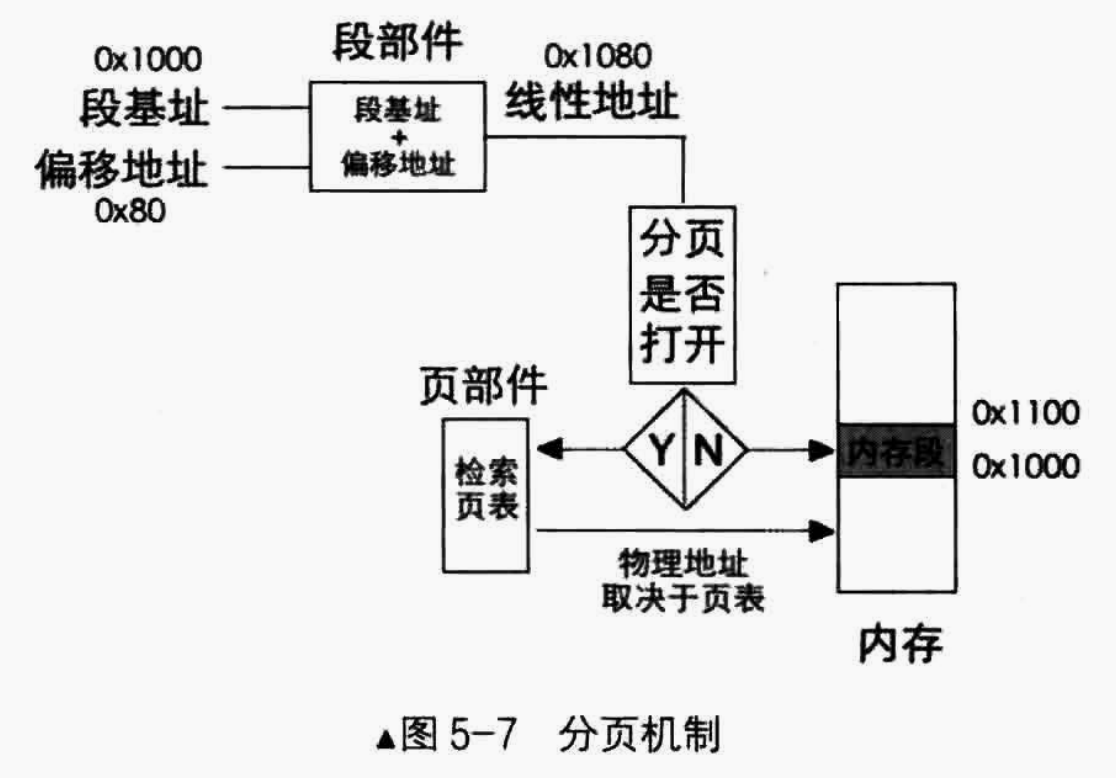
而类似于CPU上电后要手动打开保护模式,我们在进入到保护模式后也要手动打开分页机制。手动打开分页机制的时候要将页表地址加载到控制寄存器cr3中。
所以,在打开分页机制后,页表的物理地址实际上就在寄存器cr3中,我们只需要按照页表物理地址 + 索引 * 4(一个页表项4个字节),就能够获得页表项的物理地址了。
获得页表项的物理地址之后,再加上页内便宜,我们就得到了将要访问的物理地址。
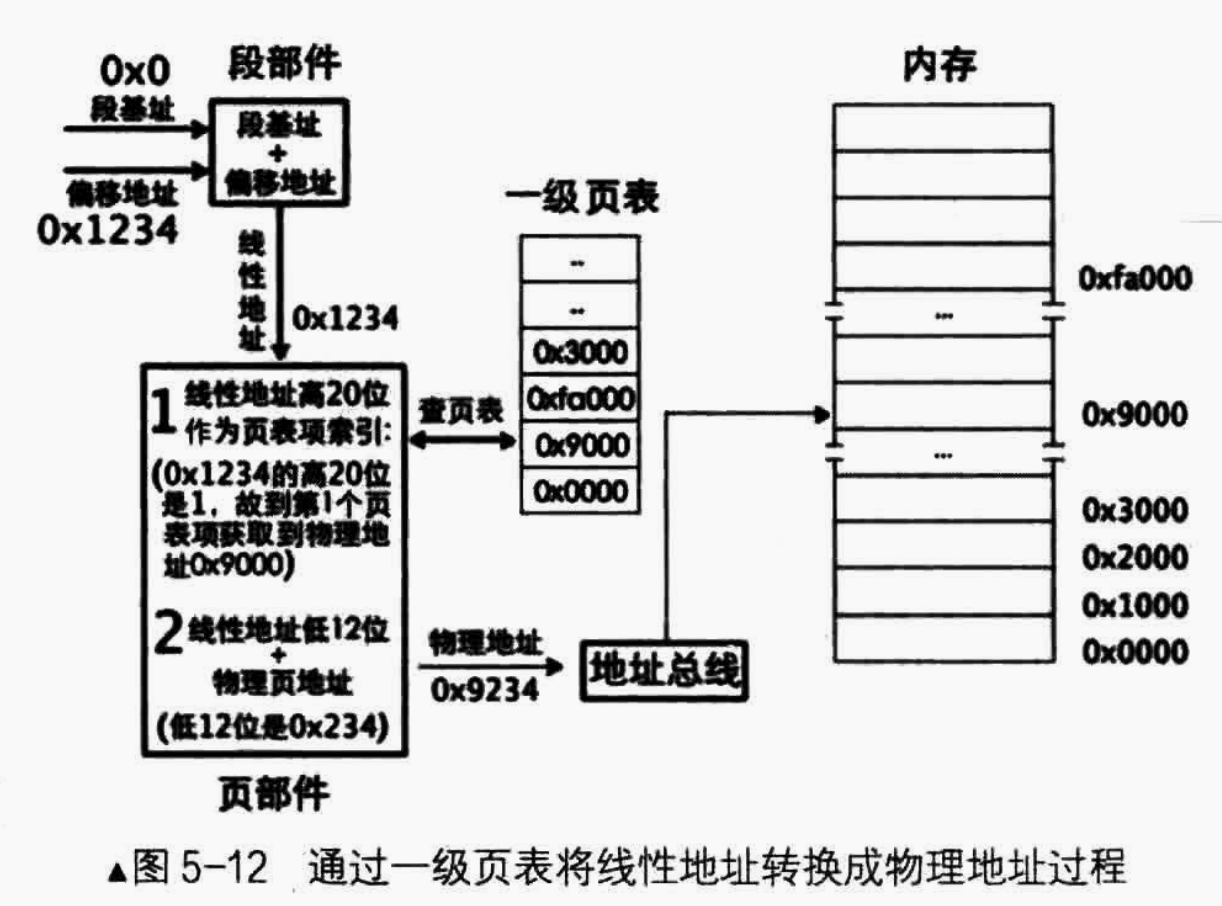
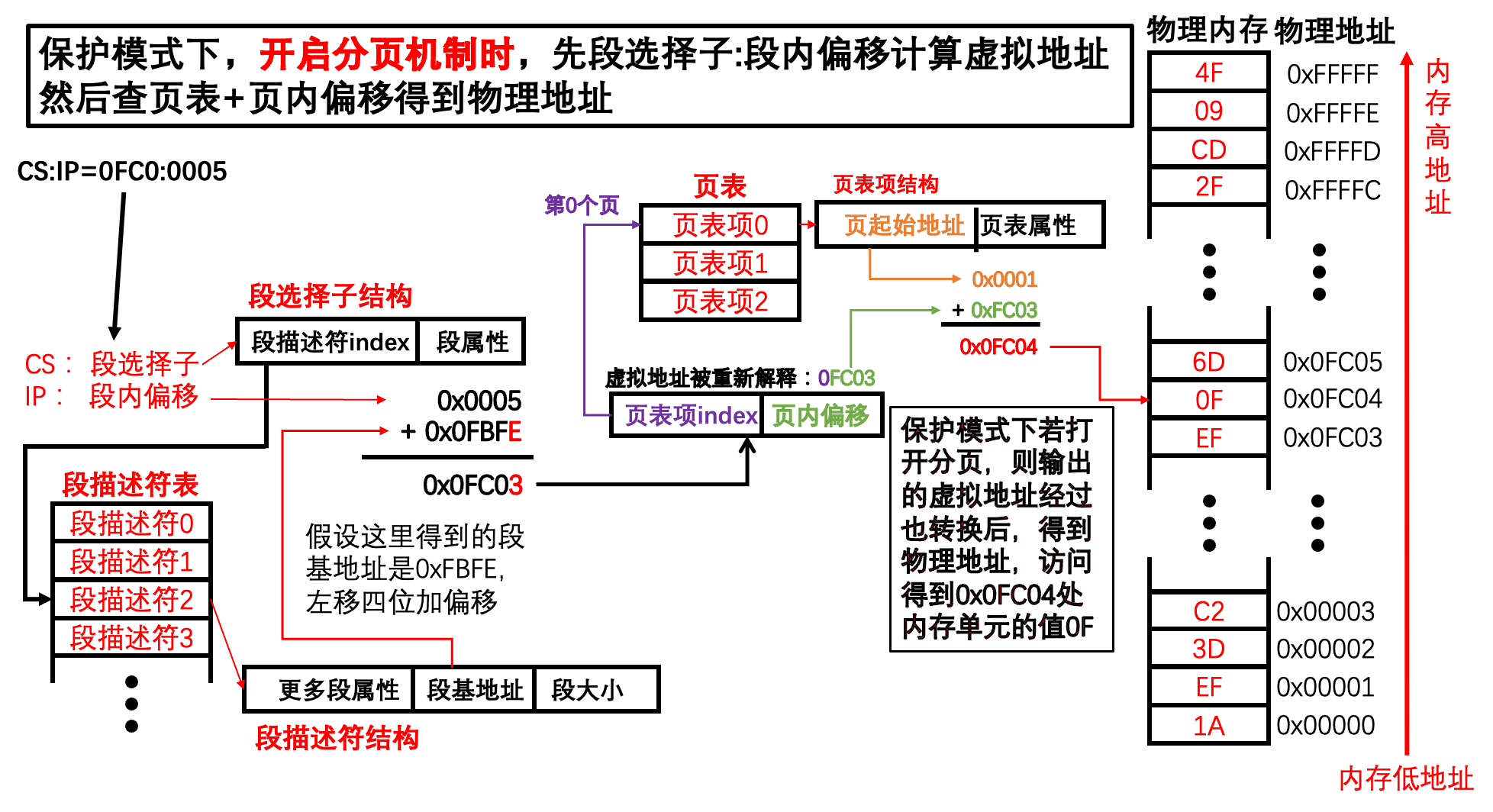
举一个保护模式 + 内存分页机制下访问内存的例子:
假设我们采用
平坦内存模型,即不管段选择子值是多少,其所指向的段基址都是0x0000,现在求指令mov ax,[0xl234]将访问的内存单元的物理地址。首先进行段式访问内存地址处理:
- 在指令
mox ax, [0x1234]中,0x1234是段基址/段选择子:段内偏移地址中的段内偏移地址。- 由于我们采用平坦内存模型,因此选择子最终在
GDT中获得的段基址是0x0000_0000- 因为段内偏移地址为
0x1234,所以经过段部件处理后,输出的线性地址/虚拟地址是0x0000_l234。然后进行页式访问内存地址处理(由于咱们是演示分页机制,所以系统已经打开了分页机制,线性地址
0x0000_1234被送入了页部件进行转换以获得物理地址):
- 页部件分析
0x0000_1234的高20位,用十六进制表示高20位是0x0000_1。所以将此项作为页表项索引,再将该索引乘以4后加上cr3寄存器中页表的物理地址,这样便得到索引所指代的页表项的物理地址,从该物理地址处(页表项中〉读取所映射的物理页地址为0x9000。- 叶部件分析
0x0000_1234的底12位,线性地址的低12位是0x234,它作为物理页的页内偏移地址与物理页地址。- 计算最终的物理地址。物理页地址
0x9000与页内偏移0x234相加,和为0x9234,这就是虚拟地址0xl234最终转换成的物理地址
D. 分页机制的作用
分页机制的作用有两方面:
- 将
线性地址/虚拟地址转换成物理地址 - 用大小相等的页代替大小不等的段
这两方面的作用如下图所示:
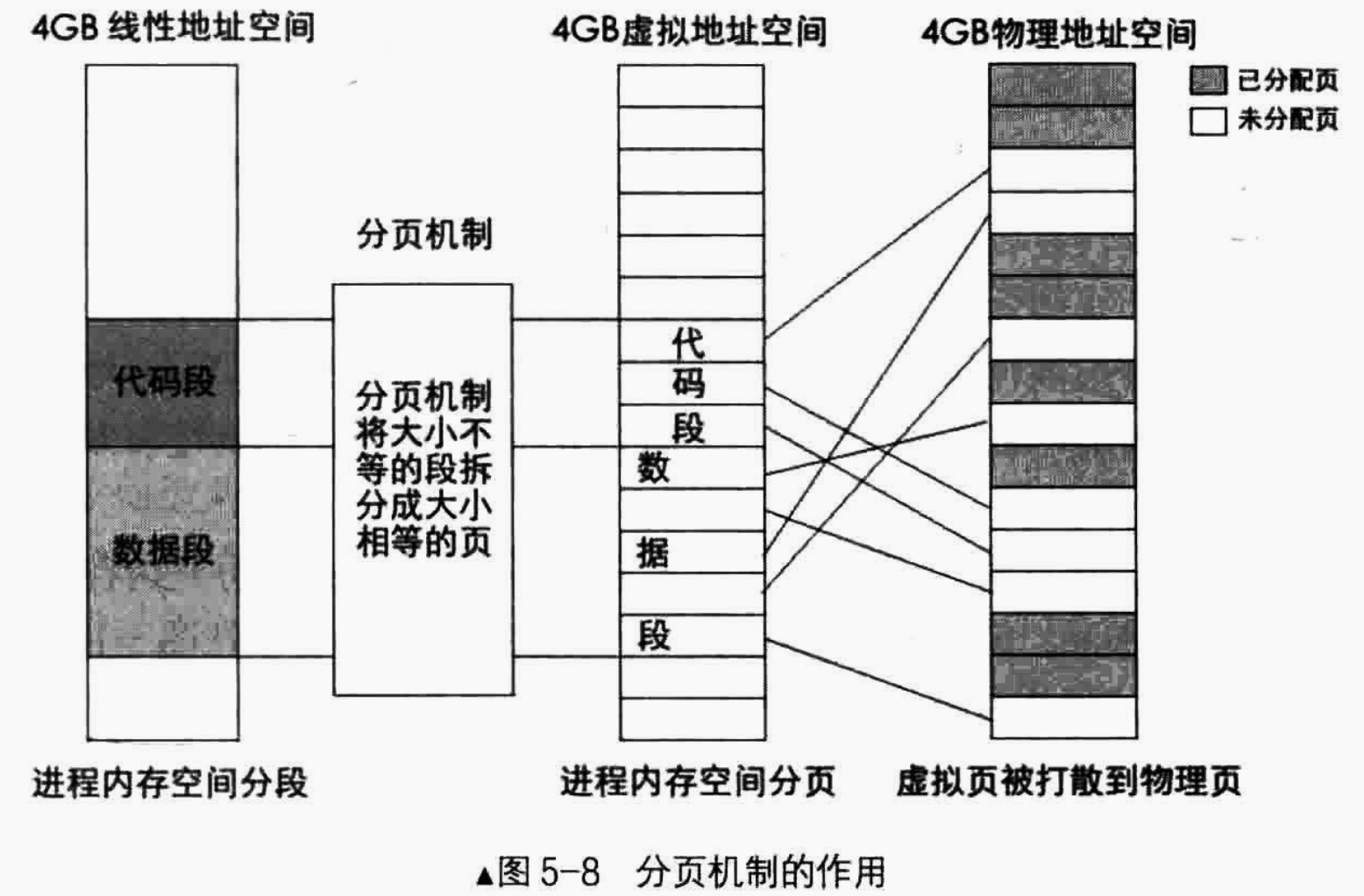
由于有了线性地址到真实物理地址的这层映射,经过段部件输出的线性地址便有了另外一个名字:虚拟地址。
分页机制有一个重要的功能,就是将每个程序眼中的地址隔离开。在内存分段访问的情况下,如果有两个程序通过段基地址:段内偏移或者段选择子:段内偏移的方式计算出来的地址是一样的,那么两个程序的地址就会有冲突。
然而,在分页机制下,因为两个程序将虚拟地址映射为物理地址的方式不一样,因此即便是两个程序计算出来的地址是一样的,但两个程序映射方式不一样,因此最终计算得到的物理地址也不一样。因此,内存分页机制实现了程序之间的相互隔离,每个程序都有自己虚拟地址空间。
E. 总结
在保护模式下,开始分页机制时,先通过段选择子:段内偏移这一段式访问内存先计算出虚拟地址,而后根据页式地址转换最终获得物理地址的流程我们上面就全部讲解完了。
总结如下:
7. 80386访问内存总结
最后,我们总结一下80386的保护模式以及内存分页机制访问内存。
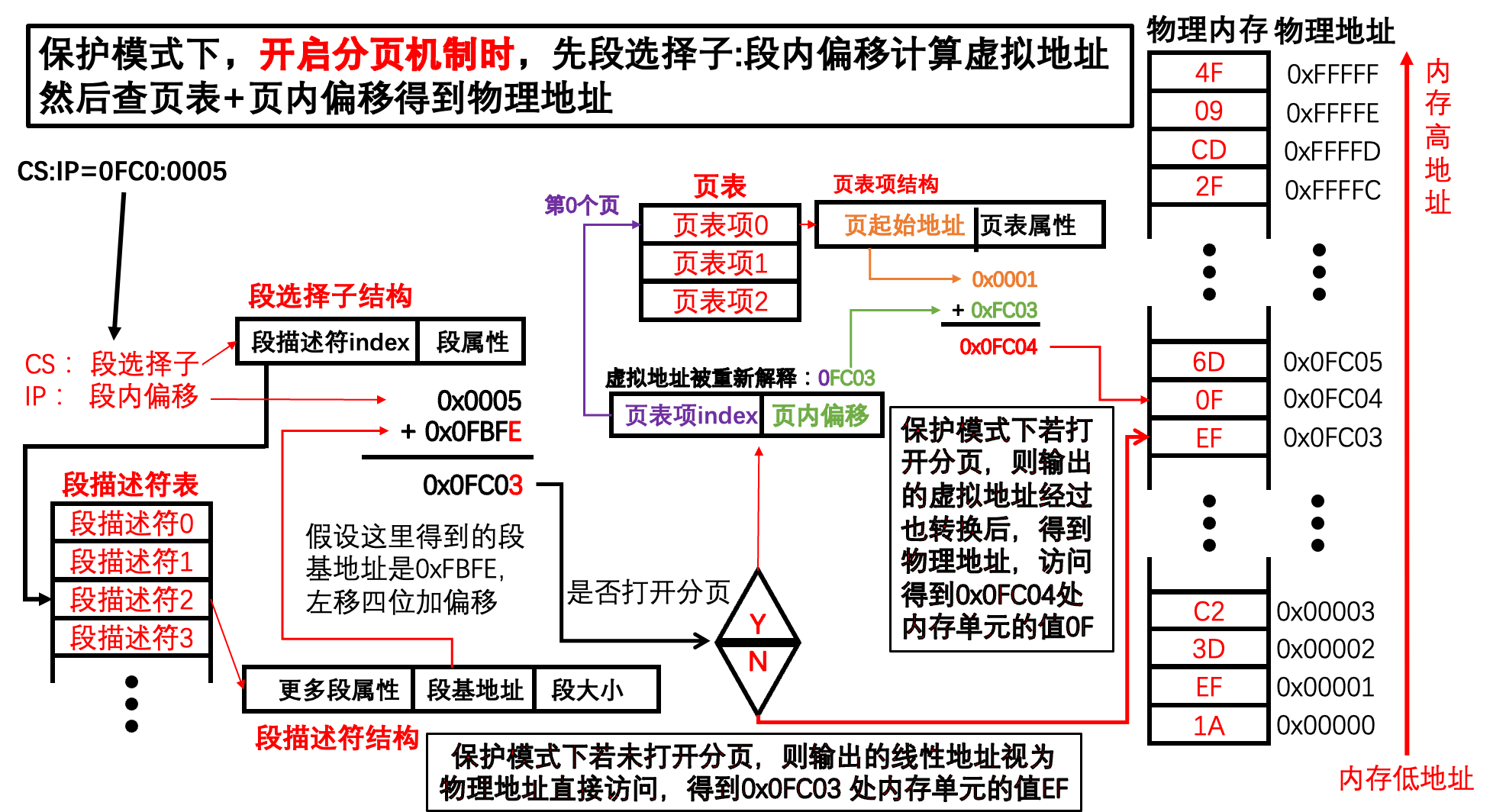
四、总结