
Parallel Sort
最近在CS537这门课程上学习了Mutex、Conditional Variable (CV)、Semaphore等等用于线程同步与互斥的量。
当然,光说不练假把式。作为练习,写了一个多线程排序的项目出来。
个人觉得,这个项目对多线程编程能力有很大的提升,尤其是死锁的DEBUG,所以特地把这个项目记录一下。

项目说明
本项目要求对一个包含多个记录(record)的二进制文件进行排序。二进制文件中,每一个记录(record)占100个字节。前4个字节作为该记录的键(key),后6个字节作为该记录的值(value)。
项目要求对所有的记录,按照其键的值进行排序,并将排序后的结果写入到新的二进制文件中。
生成待排序二进制文件的代码如下:
#include <fcntl.h>
#include <assert.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
typedef struct rec {
int key;
int value[24]; // 96 bytes
} rec_t;
int main(int argc, char *argv[]) {
if (argc != 3) {
fprintf(stderr, "generate numkeys file\n");
exit(1);
}
int n = atoi(argv[1]);
char *file = argv[2];
int fd = open(file, O_CREAT | O_WRONLY | O_TRUNC, 0666);
if (fd < 0) {
perror("open");
exit(1);
}
int k;
for (k = 0; k < n; k++) {
long u = random();
rec_t r;
r.key = u;
int i;
for (i = 0; i < 24; i++) {
r.value[i] = random();
}
int rc = write(fd, &r, sizeof(rec_t));
assert(rc == sizeof(rec_t));
}
close(fd);
return 0;
}
代码说明
架构决定性能
本项目的模型以sort_job为核心,采用多个排序线程、多个合并线程的方式,本质上是生产者——消费者模型。
具体来说,程序将需要排序的文件分成多个小块,将其抽象为sort_job,而后每个排序线程sort_worker认领一个sort_job,每个sort_worker对认领到的sort_job进行排序。在排序完成后,sort_worker将排序完成的sort_job(称为sorted_job,本质上就是sort_job)放入到由sorted_job组成的的队列sorted_jobs中。
而后排序线程merge_worker从sorted_jobs队列中取出两个sorted_job,将他们合并,得到一个新的,包含记录数量更多的sorted_job,并将该sorted_job插入到sorted_jobs队列中。
merge_worker不断地进行合并,直到sorted_jobs队列最后仅剩余一个sorted_job,且该sorted_job中的记录数量等于总记录数量,则此时排序结束,将排序后的记录写入到文件中。
1. byte_t、byteStream_t、record_t类型
项目中一个记录是100个字节,然而从文件中读取出所有记录之后,如果在比较得时候,直接交换两个记录,那么复制、拷贝100个字节带来的开销就会很大,因此排序的时候针对指向记录的指针进行排序,每次只需要交换两个指针,所以开销就会小很多。
为此,进行如下的定义
typedef unsigned char byte_t;
typedef byte_t *byteStream_t;
typedef byteStream_t *record_t;
其中:
- 1个字节就是8个比特位,且不考虑符号,所以定义
byte_t类型为unsigned char - 字节流则是由字节组成的数组,因此定义
byteStream_t类型为指向byte的指针,或者说是byte数组,即byte*,所以一个记录是100字节,就可以用一个byte数组表示,即用byteStream_t表示 - 为了避免开销,所以排序是针对指向记录的指针进行的,即针对指向
byteStream_t的指针进行的,所以定义一个record_t为byteStream*
2. sort_job_t对象
A. 定义
sort_job_t对象的定义如下
typedef struct _sort_job
{
// Notes: init 必须指定
int sort_func;
int seek;
int num;
bool reverse;
char *filename;
// Notes: done, records和buffer由worker填充
bool done;
record_t *records;
byteStream_t buffer;
} sort_job_t;
其中,在初始化sort_job_t类型的对象的时候,下面几个参数必须指定
// Notes: init 必须指定
int sort_func;
int seek;
int num;
bool reverse;
char *filename;
而剩余的参数
// Notes: done, records和buffer由worker填充
bool done;
record_t *records;
byteStream_t buffer;
则是由以sort_job_t为输入的函数所填充的,稍后会介绍。
B. sort_job相关函数
sort_job对象作为程序的核心,不少函数都和他有关,具体来说,包括以下函数
// sort_job 初始化、释放相关
sort_job_t *sort_job_init(int sort_func, int seek, int num, bool reverse, char *filename);
int sort_job_release(sort_job_t *job);
int read_records(const char *filename, byteStream_t *buffer, int seek, int num);
int parse_records(byteStream_t buffer, record_t *records[], int byte);
// 多线程函数,以sort_job为核心
void *sort_worker(void *arg);
void *append_worker(void *arg);
void *merge_worker(void *arg);
多线程函数放在后面介绍,所以这里就先介绍sort_job初始化和释放的相关函数。
C. sort_job_init与sort_job_release函数
针对sort_job对象,提供了下述两个个相关的函数以进行初始化和释放
// sort_job functions
sort_job *sort_job_init(int sort_func, int seek, int num, bool reverse, char *filename);
int sort_job_release(sort_job *job);
其中:
sort_job_init负责初始化sort_job,而由sort_job_init初始化的sort_job必须由sort_job_release释放sort_job_release负责释放由sort_job_init初始化的sort_job
两个函数具体的定义如下:
/**
* @brief sort_job结构体的初始化函数
*
* @param sort_func 使用的sort function类型
* @param seek 跳过多少个record
* @param num 读取的record数, -1 表示读取全部
* @param reverse 是否降序排列,若为true则降序排序
* @param filename 需要读取的二进制文件文件名
* @return sort_job* 指向结构体的指针
*
* @author Shihong Wang
* @date 2022.11.2
*/
sort_job_t *sort_job_init(int sort_func, int seek, int num, bool reverse, char *filename)
{
sort_job_t *job = (sort_job_t *)malloc(sizeof(sort_job_t));
job->sort_func = sort_func;
job->seek = seek;
job->num = num;
job->reverse = reverse;
job->buffer = NULL;
job->records = NULL;
if (NULL == filename)
{
job->filename = NULL;
}
else
{
job->filename = (char *)malloc(sizeof(char) * strlen(filename));
strcpy(job->filename, filename);
}
return job;
}
/**
* @brief sort_job的析构函数
*
* @param job 指向sort_job的指针
* @return int
*
* @author Shihong Wang
* @date 2022.11.3
*/
int sort_job_release(sort_job_t *job)
{
free(job->filename);
if (job->buffer != NULL)
free(job->buffer);
if (job->records != NULL)
free(job->records);
free(job);
return 0;
}
D. read_record与parse_record函数
sort_job_t中的buffer指向字节流,而records则是record数组。这两个参数由read_records和parse_records这两个函数填充
其中:
read_records(const char *filename, byteStream_t *buffer, int seek, int num)函数接受要读取的文件名,而后将其中的内容读取后复制到buffer中parse_records(byteStream_t buffer, record_t *records[], int byte)函数接受由read_records函数读取得到buffer,而后解析其中的每个record,并将指向所以record得指针存入records数组中
这两个函数具体的内容如下:
/**
* @brief read_records_worker以以二进制方式读取filename中数据并写入到buffer中
*
* @param filename 二进制文件名
* @param buffer *byteStream_t, 指向byteStream的指针,不用提前malloc分配地址
* @param seek 跳过多少个record
* @param num 读取的record数, -1表示从seek读取到结束, -2读取文件中全部的record
* @return int 读取的字节数
*
* @author Shihong Wang
* @date 2022.10.29
*/
int read_records(const char *filename, byteStream_t *buffer, int seek, int num)
{
FILE *bin_file = fopen(filename, "rb");
if (NULL == bin_file)
psort_error("file open error");
int byte = num * BYTE_PER_RECORD;
if (num == -1)
{
fseek(bin_file, 0L, 2);
byte = (int) ftell(bin_file) - (seek * BYTE_PER_RECORD);
} else if (num == -2){
fseek(bin_file, 0L, 2);
byte = (int) ftell(bin_file);
}
if (byte <=0)
psort_error("zero record");
fseek(bin_file, (long)(seek * BYTE_PER_RECORD), 0);
if (byte % 100 != 0)
psort_error("record mismatch");
*buffer = (byteStream_t)malloc(sizeof(char) * byte);
if (NULL == *buffer)
psort_error("malloc fail");
if (fread(*buffer, 1, byte, bin_file) != byte)
psort_error("record read fail");
fclose(bin_file);
return byte;
}
/**
* @brief parse_records接受二进制文件buffer,将解析后的record存入records数组中
*
* @param buffer 二进制文件内存地址
* @param records record数组的地址
* @param byte 二进制文件的字节数
* @return int 解析得到的record数
*
* @author Shihong Wang
* @date 2022.10.30
*/
int parse_records(byteStream_t buffer, record_t *records[], int byte)
{
int num = byte / 100;
*records = (record_t *)malloc(sizeof(record_t) * byte);
if (NULL == *records)
psort_error("malloc fail");
for (int i = 0; i < num; i++)
{
(*records)[i] = (byteStream_t *)malloc(sizeof(byteStream_t));
*(*records)[i] = (buffer + 100 * i);
}
return num;
}
3. sorted_jobs队列
程序的多线程模型是生产者——消费者模型。核心就是生产者(sort_worker)、消费者(merge_worker)共同维护的产品队列。
因此,sorted_jobs队列作为多个线程共享的数据,对其进行修改的代码都属于临界区代码,需要使用互斥锁(Mutual Exclusion, Mutex)来进行保护。
同时,因为当sorted_jobs队列满了之后,生产者线程不能再继续向其中填充sorted_job,而当sprted_job空的时候,消费者线程不能继续向其中拿去sorted_job。所以还需要一个条件变量(Conditional Variable,CV)来满足生产者、消费者操作sorted_jobs队列的条件。
A. 定义
sorted_jobs队列相关的变量如下
// 数组形式的循环队列
int num_fill = 0;
int front = 0;
int rear = 0;
sort_job_t **sorted_jobs;
// 互斥锁与信号量
pthread_cond_t sorted_jobs_cond;
pthread_mutex_t sorted_jobs_mutex;
B. do_get与do_fill函数
do_get函数与do_fill函数是操作sorted_jobs的函数。
具体来说,do_get负责从sorted_jobs队列中获取一个sorted_job;而do_fill负责向sorted_jobs中填充一个sorted_job。
理论上来说,可以将临界区访问的获得锁的代码放入其中,但是为了灵活性,所以选择像获得锁的代码放在do_get与do_fill函数外,即先获得锁才能调用这两个函数。
do_get与do_fill函数的定义如下
/**
* @brief do_fill用于把sorted之后的job放入sorted_jobs队列中
*
* @param sorted_job 指向sorted_job的指针
*
* @author Shihong Wang
* @date 2022.11.3
*/
void do_fill(sort_job_t *sorted_job)
{
sorted_jobs[rear] = sorted_job;
rear = (rear + 1) % MAX_SORTED_JOBS;
num_fill++;
}
/**
* @brief do_get用于从sorted_jobs队列中取出sorted_job
*
* @return sort_job* 指向sorted_job的指针
*
* @author Shihong Wang
* @date 2022.11.3
*/
sort_job_t *do_get()
{
sort_job_t *temp = sorted_jobs[front];
front = (front + 1) % MAX_SORTED_JOBS;
num_fill--;
return temp;
}
C. if_full、if_empty与get_num函数
if_full、if_empty和get_num函数负责获取sorted_jobs队列的状态。
因为这三个函数只读取共享变量的值,而不会修改共享变量,因此这三个函数不是临界区代码,直接访问代码即可。
此外,由于在程序中汇多次调用这三个函数,因此将其声明为内联函数以加速程序运行。注意,C/C++要求将内联函数定义书写在头文件中。
// libpsort.h
// 函数头
static inline bool is_full();
static inline bool is_empty();
static inline bool get_num();
// Inline methods are supposed to be implemented in the header file. The compiler needs to know the code to actually inline it.
static inline bool is_empty(){
return front == rear;
}
static inline bool is_full(){
return (rear + 1) % MAX_SORTED_JOBS == front;
}
static inline bool get_num(){
return num_fill;
}
4. 排序算法
因为项目的架构是每个sort_worker负责对文件的一块内容进行排序,而后由merge_worker进行合并,因此程序中还需要实现排序算法。
A. sort_func、func_name与XXX_SORT宏
由于有多种排序算法,因此为了程序实现最高性能,需要选择尽可能快的排序算法。因此程序中实现了三种排序算法,分别是:
冒泡排序(Bubble Sort)快速排序(Quick Sort)归并排序(Merge Sort)
程序中为了方便测试三种排序算法的速度以及调试时输出信息,进行了如下规定:
规定:排序函数的函数签名统一为:
sort_funct(record_t *records, int record_num, bool reverse)
其中:
record_t *records是待排序的record数组int record_num是record数组中record的数量bool reverse表示是否降序排列,若为true则降序排列,否则默认升序排列
因此,上述三个排序函数的函数头为
int bubble_sort(record_t records[], int num, bool reverse);
int quick_sort(record_t records[], int num, bool reverse);
int merge_sort(record_t records[], int num, bool reverse);
而为了方便调试时切换函数、输出信息,定义了sort_func函数数组以及func_name字符串数组,同时为每个排序算法定义了一个宏
#define BUBBLE_SORT 0
#define QUICK_SORT 1
#define MERGE_SORT 2
char *func_name[] = {
[BUBBLE_SORT] = "bubble_sort",
[QUICK_SORT] = "quick_sort",
[MERGE_SORT] = "merge_sort",
};
int (*sort_func[])(record_t *, int, bool) = {
[BUBBLE_SORT] = bubble_sort,
[QUICK_SORT] = quick_sort,
[MERGE_SORT] = merge_sort,
};
这样,在调试的时候只需要通过下述方式,即可便捷的切换排序算法以及输出调试信息
// 调试
int func = BUBBLE_SORT; // 选择使用冒泡排序
// int func = MERGE_SORT; // 选择使用归并排序
printf("function used: %d, sort algorithm: %s\n", func, func_name[func]);
sort_func[func](records, num, false);
B. get_key、less_than和swap函数
无论任何的函数,在排序的过程中都涉及到比大小(Compare)和交换(Swap)两个操作。因此可以将这两个常用函数单独实现。
此外,由于我们再比大小的时候是针对每一个record的key进行的比较,还需要一个get_key函数,接受record返回其key值。
由于这三个函数都非常常用,因此统一声明为内联函数。
注意,C语言中的static关键字用于声明某个变量的链接属性,因此在这里声明了static之后,链接的时候所有的get_key变量名都会链接到这里定义的get_key函数中。
// libpsort.h
/**
* @brief get_key 从给定的record中读取key(前四个字节拼接得到的signed int)
*
* @param record 需要读取key的record
* @return int record的key
*
* @author Shihong Wang
* @date 2022.10.30
*/
static inline int get_key(record_t record)
{
if (NULL == record)
psort_error("record == NULL, didn't initialize?");
return *(int *)(*record);
}
/**
* @brief less_than比较两个record的key,若左边小于右边,返回1,相等返回0,大于返回-1
*
* @param left 左侧的Record
* @param right 右侧的Record
* @return int 比较的结果
*
* @author Shihong Wang
* @date 2022.10.30
*/
static inline int less_than(record_t left, record_t right)
{
int left_key = get_key(left);
int right_key = get_key(right);
if (left_key < right_key)
return 1;
else if (left_key == right_key)
return 0;
else
return -1;
}
/**
* @brief swap用于交换record数组中指令的两个元素
*
* @param records record数组
* @param i 第一个元素的index
* @param j 第二个元素的index
*
* @author Shihong Wang
* @date 2022.10.30
*/
static inline void swap(record_t *records, int i, int j)
{
record_t temp = records[i];
records[i] = records[j];
records[j] = temp;
}
C. 冒泡排序算法实现
冒泡排序算法实现如下,没啥好说的,写就对了。
/**
* @brief 冒泡排序,大保底
*
* @param records record数组
* @param num record的数量
* @param reverse 若为true,则按照降序排列,否则按照升序排列
* @return int 状态码
*
* @author Shihong Wang
* @date 2022.10.30
*/
int bubble_sort(record_t records[], int num, bool reverse)
{
int sign = reverse == true ? 1 : -1;
for (int i = 0; i < num; i++)
{
for (int j = 0; j < num - 1 - i; j++)
{
if (less_than(records[j], records[j + 1]) * sign >= 0)
swap(records, j, j + 1);
}
}
return SORT_SUCCESS;
}
D. 快速排序算法实现
快速排序有好几种实现方式,最简单的就是递归实现。递归实现的首先根据当前枢轴的值,将数组中小于枢轴值的record放到左侧,大于枢轴值的record放到右侧。而后分别对左侧和右侧进行递归排序
因此对其递归函数进行封装,提供统一的排序函数调用接口:
// 函数头
int _partition(record_t records[], int low, int high, bool reverse);
int _quick_sort(record_t records[], int low, int high, bool reverse);
int quick_sort(record_t records[], int num, bool reverse);
函数具体实现为:
/**
* @brief 快速排序的partition函数
*
* @param records record数组
* @param low 左侧index
* @param high 右侧index
* @param reverse 若为true,则按照降序排列,否则按照生序排列
* @return int 新的pivot的index
*
* @author Shihong Wang
* @date 2022.10.31
*/
int _partition(record_t records[], int low, int high, bool reverse)
{
int pivot = low;
record_t pivot_value = records[pivot];
int sign = reverse == true ? -1 : 1;
while (low < high)
{
while (low < high && less_than(pivot_value, records[high]) * sign >= 0)
high--;
records[low] = records[high];
while (low < high && less_than(records[low], pivot_value) * sign >= 0)
low++;
records[high] = records[low];
}
records[low] = pivot_value;
return low;
}
/**
* @brief 快速排序母函数
*
* @param records record数组
* @param low 左侧index
* @param high 右侧index
* @param reverse 若为true则降序排列,否则升序排列
* @return int 程序状态码
*
* @author Shihong Wang
* @date 2022.10.31
*/
int _quick_sort(record_t records[], int low, int high, bool reverse)
{
if (low < high)
{
int pivot = _partition(records, low, high, reverse);
_quick_sort(records, low, pivot - 1, reverse);
_quick_sort(records, pivot + 1, high, reverse);
}
return SORT_SUCCESS;
}
/**
* @brief 快速排序 wrapper,为了benchmark
*
* @param records record数组
* @param num record的数量
* @param reverse 若为true,则按照降序排列,否则按照升序排列
* @return int 状态码
*
* @author Shihong Wang
* @date 2022.10.31
*/
int quick_sort(record_t records[], int num, bool reverse)
{
return _quick_sort(records, 0, num - 1, reverse);
}
E. 归并排序算法实现
归并排序中的归并这一步由于在merge_worker中也有所使用,因此将其单独封装为一个函数。
归并排序的函数头为:
int order_merge(record_t old_records[], record_t new_records[], int num, int low, int mid, int high, bool reverse);
int _merge_sort(record_t records[], int num, bool reverse, int seg_start);
int merge_sort(record_t records[], int num, bool reverse);
其中order_merge为将old_records中low~mid已经排序好的record和mid+1~high中已经排序好的record进行合并
三个函数的实现分别如下
/**
* @brief order_merge 给定未排序的原数组和空的新数组,而后将low ~ mid 和 mid ~ high中的值按顺序排列到新数组中
*
* @param old_records 原数组
* @param new_records 新数组
* @param num 原数组中record数
* @param low low的值
* @param mid mid的值
* @param high high的值
* @param reverse 若为true,则为降序排列,否则为升序排列
* @return int 状态码
*
* @author Shihong Wang
* @date 2022.11.3
*/
int order_merge(record_t old_records[], record_t new_records[], int num, int low, int mid, int high, bool reverse)
{
int k = low;
int start1 = low, end1 = mid;
int start2 = mid, end2 = high;
while (start1 < end1 && start2 < end2)
{
if (!reverse)
new_records[k++] = less_than(old_records[start1], old_records[start2]) >= 0 ? old_records[start1++] : old_records[start2++];
else
new_records[k++] = less_than(old_records[start1], old_records[start2]) >= 0 ? old_records[start2++] : old_records[start1++];
}
while (start1 < end1)
new_records[k++] = old_records[start1++];
while (start2 < end2)
new_records[k++] = old_records[start2++];
return 0;
}
/**
* @brief 归并排序母函数
*
* @param records record数组
* @param num record的数量
* @param reverse 若为true,则按照降序排列,否则按照升序排列
* @param seg_start 归并排序开始时每组中的记录数
* @return int 状态码
*
* @author Shihong Wang
* @date 2022.11.3
*/
int _merge_sort(record_t records[], int num, bool reverse, int seg_start)
{
int sign = reverse == true ? -1 : 1;
record_t *old_records = records;
record_t *new_records = (record_t *)malloc(sizeof(record_t) * num);
int seg, start;
for (seg = seg_start; seg < num; seg += seg)
{
for (start = 0; start < num; start += seg * 2)
{
int low = start, mid = min(start + seg, num), high = min(start + seg * 2, num);
order_merge(old_records, new_records, num, low, mid, high, reverse);
}
// swap for next sort
record_t *temp = new_records;
new_records = old_records;
old_records = temp;
}
if (old_records != records)
{
for (int i = 0; i < num; i++)
new_records[i] = old_records[i];
new_records = old_records;
}
free(new_records);
return SORT_SUCCESS;
}
/**
* @brief 归并排序 wrapper, 为了benchmark
*
* @param records
* @param num
* @param reverse
* @return int
*
* @author Shihong Wang
* @date 2022.11.3
*/
int merge_sort(record_t records[], int num, bool reverse)
{
return _merge_sort(records, num, reverse, 1);
}
5. 多线程排序
多线程排序的核心算法就是两类线程:生产者和消费者。其中sort_worker由于对sort_job排序后将其放入sorted_jobs队列中,因此sort_worker是生产者,而merge_worker由于从sorted_jobs中获取sorted_job,因此是消费者。
A. 生产者:sort_worker
生产者sort_worker的函数头如下:
void *sort_worker(void *arg);
由于pthread库要求传入的参数是一个指针,因此在调用的时候需要将原始的参数转换为指向void的指针,而后在函数中再将其转换为原先的指针。即:
// 按照如下方式创建线程
int func = MERGE_SORT; // 使用归并排序
int seek = 0; // 从头开始读取文件
int num = -2; // 读取文件中全部record
bool reverse = false;
char *filename = "test.bin";
// 初始化sort_job
job = sort_job_init(MERGE_SORT, seek, num, reverse, filename);
pthread_create(&sort_thread_pool[j], NULL, sort_worker, (void *)jobs[j]);
// sort_worker按照如下方式接受参数
void *sort_worker(void *arg)
{
// sort_worker认领sort_job,而后开始排序
sort_job_t *job = (sort_job_t *)arg;
// 开始排序
...
}
sort_worker整体实现为:
/**
* @brief sort_worker是排序线程执行的函数,每个sort_worker都是一个producer(产品放在sorted_queue中)
*
* @param arg 指向sort_job*的指针,传入前和使用前都需要进行类型强制转换
* @return void*
*
* @author Shihong Wang
* @date 2022.11.3
*/
void *sort_worker(void *arg)
{
// 领取sort_job(接受参数)
sort_job_t *job = (sort_job_t *)arg;
// 读取record
int byte = read_records(job->filename, &job->buffer, job->seek, job->num);
job->num = byte / 100;
if (parse_records(job->buffer, &job->records, byte) != job->num)
{
char str[MAX_CHAR];
sprintf(str, "thd -> %ld: parse_records mismatch!", (long)pthread_self());
psort_error(str);
}
// 排序
int result = sort_func[job->sort_func](job->records, job->num, job->reverse);
if (result != SORT_SUCCESS)
{
char str[MAX_CHAR];
sprintf(str, "thd -> %ld: sort fail!", (long)pthread_self());
psort_error(str);
}
job->done = true;
// 将排序完的任务(sorted_job)放入sorted_jobs队列中
// 下面因为要访问共享资源sorted_jobs,所以都是临界区
pthread_mutex_lock(&sorted_jobs_mutex);
// 等待consumer
while (is_full())
pthread_cond_wait(&sorted_jobs_cond, &sorted_jobs_mutex);
// 排序完当前job后,把job放入sorted_jobs_queue中,等待merger_worker处理,所以sort_worker就是producer
do_fill(job);
// 唤醒consumer
pthread_cond_signal(&sorted_jobs_cond);
pthread_mutex_unlock(&sorted_jobs_mutex);
return (void *)0;
}
B. 生产者:append_worker
merge_worker在合并开始前从sorted_jobs中获取两个sorted_job,因此merge_worker是消费者。而当merge_worker在归并完成后,需要将新的、合并后record数量更多的sorted_job插入到sorted_jobs队列中,因此merge_worker也是消费者。
换而言之,merge_worker既是消费者,也是生产者。可是由于sort_worker是生产者,因此下述情况下可能会发生死锁:
- 条件一:
sorted_jobs队列已满 - 条件二:
merge_worker开始运行 - 条件三:
merge_worker在从sorted_jobs中取出两个sorted_job后,由于线程调度被中断运行。 - 条件四:此时其他
sorted_worker完成排序,将sorted_jobs填充满 - 条件五:继续运行
merge_worker
由于在获得两个sorted_jobs后,merge_worker就从消费者变成了生产者。则此时sorted_jobs已经完全填充满,并且系统中不存在其他消费者,只有生产者,则此时发生死锁,系统卡死。
导致该问题发生的关键就是merge_worker既是消费者,也是生产者。因此解决方案就是将merge_worker修改为纯粹的消费者,而向sorted_jobs中插入新的sorted_job的工作则交给新的线程append_worker即可。这样merge_worker就可以继续进行合并。
即:
void *append_worker(void *arg){
sort_job_t *job = (sort_job_t*) arg;
// 插入操作
...
return (void*)0;
}
void *merge_worker(void *arg)
{
...
while (true && !last_job)
{
get_two_jobs();
merge_to_job();
...
// 将新的job插入到循环队列尾
pthread_t append_thd;
pthread_create(&append_thd, NULL, append_worker, (void *)job);
}
}
如此,即可避免该死锁问题。
append_worker具体实现为
/**
* @brief append_worker是append线程执行的函数,每个append_worker都是producer
*
* @param arg (sort_job*)指向sort_job的结构体
* @return void* 程序状态码
*
* @author Shihong Wang
* @date 2022.11.3
*/
void *append_worker(void *arg){
sort_job_t *job = (sort_job_t*) arg;
// 下面因为要访问共享资源sorted_jobs,所以都是临界区
pthread_mutex_lock(&sorted_jobs_mutex);
// Attention: 如果sorted_jobs已满(其他sort_worker/merge_worker线程填充),且只有一个consumer,则此时会有卡住,所以要保证sorted_job有足够的容量,即sorted_job < sort_thread + merge_thread
// 等待consumer
while (is_full())
pthread_cond_wait(&sorted_jobs_cond, &sorted_jobs_mutex);
// 排序完当前job后,把job放入sorted_jobs_queue中,等待merger_worker处理,所以sort_worker就是producer
do_fill(job);
// 唤醒consumer
pthread_cond_signal(&sorted_jobs_cond);
pthread_mutex_unlock(&sorted_jobs_mutex);
return (void*)0;
}
C. 消费者:merge_worker
merge_worker的基本结构为:
void *merge_worker(void *arg)
{
bool last_job = false;
// 不是最后一个merge_job,继续合并
while(not last_job){
// 获取两个sorted_job
sorted_job1 = get_sorted_job();
sorted_job2 = get_sorted_job();
// 合并两个sorted_job
new_sorted_job = merge_two_job(sorted_job1, sorted_job2);
// 插入新的sorted_job
append_sorted_job(new_sorted_job);
// 检查是否为最后一个job
last_job = update();
}
return (void*)0;
}
但是此架构在下述情况下存在死锁:
- 条件一:所有
sort_worker已经完成排序,即无新的sorted_job产生 - 条件二:只有两个
sorted_job等待合并 - 条件三:有两个
merge_worker,每个merge_worker都只有一个sorted_job
此时,系统中已经没有新的生产者,只有消费者,并且两个消费者互相等待对方手中的资源,即merge_worker互相等待对方的sorted_job
则此时系统发生死锁。
该死锁最简单的处理方式就是要求消费者主动归还资源,即在等待一段时间得不到新的sorted_job后,默认存在另外一个merge_worker,则此时放弃已经拿到的sorted_job,并且结束此merge_worker。
形象的理解,孔融需要吃到两个梨子,如果只有一个梨子,并且等待了一段时间后得不到新的梨子,就让出梨子,让别人来吃梨子。
则此时,merge_worker的结构如下
void *merge_worker(void *arg)
{
bool last_job = false;
// 不是最后一个merge_job,继续合并
while(not last_job){
// 获取两个sorted_job
sort_job jobs[2] = {NULL, NULL};
for (int i = 0; i < 2; i++){
// 等待500毫秒,若成功返回1,否则返回0
bool success = get_sorted_job_timeout(job[i], 500);
if (not success){
giveup(jobs);
return (void*) 0;
}
}
// 合并两个sorted_job
new_sorted_job = merge_two_job(jobs[0], jobs[1]);
// 插入新的sorted_job
append_sorted_job(new_sorted_job);
// 检查是否为最后一个job
last_job = update();
}
return (void*)0;
}
然而,孔融让梨接法在大多数情况下可以正确运行,然后在部分时候将会导致新的问题:两个孔融互相让梨,即两个线程同时发现拿不到新的sort_job,于是都主动选择让出sorted_job并结束自己的声明,则此时在sorted_jobs队列中遗留两个未合并的sorted_job。
为了解决该问题,可以指定一个不会让梨的孔融,其余的孔融全部为让梨的孔融,这样就会保证永远会存在一个孔融来吃完最后的两个梨子。
因此,在启动merge_worker线程的时候,可以按照如下的方式进行启动:
// main函数
int main(){
...
// 启动merge线程
for (int j = 0; j < run_config.merge_thread_num; j++)
if (j == 0)
pthread_create(&merge_thread_pool[j], NULL, merge_worker, (void *)&不让梨);
else
pthread_create(&merge_thread_pool[j], NULL, merge_worker, (void *)&让梨);
...
}
因此,merge_worker最终的实现为
/**
* @brief merge_worker是merge线程执行的函数,每个merge_worker是消费者
*
* @param arg 指向int的指针,用于判断是否已经排序完毕,调用前和使用前必须要进行强制类型转换
* @return void*
*
* @bug #1 多个sort_worker,一个merge_worker,下述情况会发生死锁:
* merge_worker正在merge,而sorted_jobs已经全部运行完,并且填充满sorted_jobs,
* 则此时由于sorted_jobs已经被填充满,故此时merge_worker等待consumer消耗sorted_jobs
* 由于只有一个merge_worker,故此时就会卡在这里
* 该bug修复方式是满足:sort_worker_thd + merge_worker_thd < max_sorted_jobs
*
* @bug #2 多个sort_worker,一个merge_worker,下述情况会发生死锁:
* merge_worker在取完了sorted_job后,就从消费者变成了生产者,若此时有别的sort_worker填满了sorted_jobs
* 后仍有sort_worker尝试do_fill,就会造成只有生产者而没有消费者的情况,此时merge_worker和sort_worker都会因为cv卡住
* 该bug的修复方式就是将merge_worker拆分为sort_worker,重新插入的工作交给append_worker处理(子线程),以保证merge_worker不会等待
*
* @bug #3 多个sort_worker,多个merge_worker,会发生死锁:
* 已经没有了sort_worker,而所有的merge_worker都只有一个job,则此时发生死锁
* 此bug类似于哲学家进餐问题,可以使用一个服务生(管理员)来管理、启动merge_worker
* 该bug的修复方法就是等待一段时间后放弃merge,将job放回队列中,同时必须要有一个不会timeout的merge_thread
*
* @author Shihong Wang
* @date 2022.11.4
*/
void *merge_worker(void *arg)
{
// 是否让梨?
bool wait = *(bool *)arg;
// 变量声明
bool last_job = false;
// Notes: 不知道为什么,先malloc在free就不会报错,真的不理解为什么,难道是Copy-on-Write机制?真搞不明白
sort_job_t *job = (sort_job_t *)malloc(sizeof(sort_job_t) * 1);
free(job);
job = NULL;
// 合并主循环,循环每运行一次,就合并两个sorted_job并插入新的sorter_job到sorted_jobs队列中
while (true && !last_job)
{
// 变量声明
last_job = false;
bool giveup = false, merge = true;
int fill_ptr = 0;
sort_job_t *jobs[2] = {NULL, NULL};
// 先获取两个梨子
while (fill_ptr < 2 && !last_job && !giveup)
{
int state;
struct timeval now;
struct timespec expire;
gettimeofday(&now, NULL);
// Attention: 等待一会,否则放弃
expire.tv_sec = now.tv_sec;
expire.tv_nsec = now.tv_usec + 500000000;
// 下面因为要访问共享资源sorted_jobs,所以都是临界区
pthread_mutex_lock(&sorted_jobs_mutex);
// 等待看看有没有新的梨子
while (is_empty()){
if (wait)
state = pthread_cond_wait(&sorted_jobs_cond, &sorted_jobs_mutex);
else
state = pthread_cond_timedwait(&sorted_jobs_cond, &sorted_jobs_mutex, &expire);
// 等待不到新的梨子,则返还已经拿到的梨子,并且结束线程
if (state != 0){
giveup = true;
for (int i = 0; i < 2; i++){
if (jobs[i] != NULL){
do_fill(jobs[i]);
jobs[i] = NULL;
}
}
fill_ptr = 0;
break;
}
}
// 如果有新的梨子,则拿走新的梨子
if (state == 0){
jobs[fill_ptr++] = do_get();
}
// 唤醒consumer
pthread_cond_signal(&sorted_jobs_cond);
// 退出临界区
pthread_mutex_unlock(&sorted_jobs_mutex);
// check if last job
for (int i = 0; i < 2; i++){
if (jobs[i] != NULL && jobs[i]->num >= run_config.record_num){
job = jobs[i];
merge = false, last_job = true;;
break;
}
}
}
// 结束线程
if (giveup)
break;
if (merge)
{
// 归并排序
int sum = jobs[0]->num + jobs[1]->num;
job = sort_job_init(MERGE_SORT, 0, sum, false, (char *)NULL);
record_t *temp_records = (record_t *)malloc(sizeof(record_t) * job->num);
job->records = (record_t *)malloc(sizeof(record_t) * job->num);
for (int i = 0, ptr = 0; i < 2; i++)
for (int j = 0; j < jobs[i]->num; j++)
temp_records[ptr++] = jobs[i]->records[j];
if (order_merge(temp_records, job->records, job->num, 0, jobs[0]->num, job->num, jobs[0]->reverse))
psort_error("merge error!");
// release job if job is merged by merge_worker
for (int i = 0; i < 2; i++)
if (jobs[i]->filename == NULL)
sort_job_release(jobs[i]);
free(temp_records);
}
// 将新的job插入到循环队列尾
pthread_t append_thd;
pthread_create(&append_thd, NULL, append_worker, (void *)job);
}
return (void *)0;
}
D. 主程序:启动消费者与生产者
最终,主程序内容如下:
- 首先根据要排序的文件的字节数,推断需要的排序、合并线程数量(
init_config完成),并写入到run_config中 - 初始化访问临界区需要的互斥锁
sorted_jobs_mutex,信号量sorted_jobs_cond - 初始化
sorted_jobs队列 - 启动
sort_worker线程 - 启动
merge_worker线程 - 等待
sort_worker和merge_worker结束 - 从
sorted_jobs中获取最后一个完成排序的done_job - 将
done_job中的内容写入到输出文件中。
int main(int argc, char *argv[])
{
if (argc != 3)
psort_error("Empty input file");
byteStream_t buffer;
// Code for parallel sort
struct timezone tz;
struct timeval start, end;
gettimeofday(&start, &tz);
// init all
int byte = read_records(argv[1], &buffer, 0, -1);
init_config(byte);
pthread_mutex_init(&sorted_jobs_mutex, NULL);
pthread_cond_init(&sorted_jobs_cond, NULL);
sorted_jobs = (sort_job_t**)malloc(sizeof(sort_job_t*) * (run_config.sorted_job_num));
pthread_t *sort_thread_pool = (pthread_t *)malloc(sizeof(pthread_t) * run_config.sort_thread_num);
// start sort threads
int seek = 0;
int record_left = run_config.record_num;
int all = 0;
sort_job_t **jobs = (sort_job_t **)malloc(sizeof(sort_job_t *) * run_config.sort_thread_num);
for (int j = 0; j < run_config.sort_thread_num; j++)
{
int num = run_config.record_per_thread;
if (j == run_config.sort_thread_num - 1){
num = -1;
all += record_left;
} else
all += num;
jobs[j] = sort_job_init(MERGE_SORT, seek, num, false, argv[1]);
pthread_create(&sort_thread_pool[j], NULL, sort_worker, (void *)jobs[j]);
seek += num;
record_left -= num;
}
// start merge threads
bool wait_arg = true;
bool timeout_arg = false;
pthread_t *merge_thread_pool = (pthread_t *)malloc(sizeof(pthread_t) * run_config.merge_thread_num);
for (int j = 0; j < run_config.merge_thread_num; j++)
if (j == 0)
pthread_create(&merge_thread_pool[j], NULL, merge_worker, (void *)&wait_arg);
else
pthread_create(&merge_thread_pool[j], NULL, merge_worker, (void *)&timeout_arg);
for (int j = 0; j < run_config.sort_thread_num; j++)
pthread_join(sort_thread_pool[j], NULL);
for (int j = 0; j < run_config.merge_thread_num; j++)
pthread_join(merge_thread_pool[j], NULL);
// get done_job
pthread_mutex_lock(&sorted_jobs_mutex);
// 等待producer
while (is_empty())
pthread_cond_wait(&sorted_jobs_cond, &sorted_jobs_mutex);
sort_job_t* done_job = do_get();
// 唤醒consumer
pthread_cond_signal(&sorted_jobs_cond);
pthread_mutex_unlock(&sorted_jobs_mutex);
if (write_records(argv[2], done_job) != byte)
psort_error("read record and write record mismatch");
for (int j = 0; j < run_config.sort_thread_num; j++)
{
if (PRINTKEY == 1)
{
printf("Main, Thd -> %d: %s\n", j, func_name[jobs[j]->sort_func]);
printf("After Sorts:\n");
printKeys(jobs[j]->records, jobs[j]->num);
delim;
}
}
if (PRINTKEY == 1){
printf("Main, After Merge:\n");
// 下面因为要访问共享资源sorted_jobs,所以都是临界区
printKeys(done_job->records, done_job->num);
delim;
}
gettimeofday(&end, &tz);
int sec = end.tv_sec - start.tv_sec;
int usec = end.tv_usec - start.tv_usec;
if (usec < 0){
sec -= 1;
usec += 1000000;
}
float used = sec + usec / 1000000.0;
printf("Main, sort %d records, using %.6f seconds\n", run_config.record_num, used);
return 0;
}
E. 总结
总的来说,该多线程模型并不要求必须要先等所有的sort_worker排序完再合并,也不要求只能有一个merge_worker进行合并,支持并行的排序以及合并,因此理论上性能比较高。
Debug难度较大,两个死锁改了一整天。
6. 拾遗
最后就是一些小工具
A. write_record函数
在经过merge_worker合并得到最后一个sorted_job后,需要将排序后的内容写回到文件中,因此提供了write_record函数
/**
* @brief 将job中的record写入到filename中
*
* @param filename 要写入的文件的文件名
* @param job 要写入的job的名称
* @return int
*/
int write_records(const char* filename, sort_job_t*job){
FILE *bin_file = fopen(filename, "wb");
if (bin_file == NULL)
psort_error("file open error");
int writte_byte = 0;
for (int i = 0; i < job->num; i++){
if (fwrite(*(job->records[i]), BYTE_PER_RECORD, 1, bin_file) != 1)
psort_error("record write error");
writte_byte += BYTE_PER_RECORD;
}
return writte_byte;
}
B. psort_error函数
在开发阶段,为了能够输出错误信息,因此使用psort_error函数。相比于单纯的使用fprintf(stderr, "Error")来说,psort_error可以根据是否为调试阶段有不同的表现:
DEBUG阶段:输出出错的行数,以及错误信息- 非
DEBUG阶段:输出An error has occurred!
输出行号的实现则是通过宏函数以及编译器内置的__LINE__变量实现。
具体实现如下
#define psort_error(s) _psort_error(s, __LINE__)
/**
* @brief _psort_error用于输出错误信息,若定义DEBUG宏则输出错误行号, 和posort_error宏函数搭配使用
*
* @param str 错误信息
* @param lineno 错误发生的行号
*
* @author Shihong Wang
* @date 2022.10.29
*/
void _psort_error(char *str, int lineno)
{
char *str_c;
#ifdef DEBUG
// int to alphabetic-number
char line[20];
sprintf(line, "line: %d, ", lineno);
// construct str
str_c = (char *)malloc(sizeof(char) * (strlen(str) + strlen(line)));
sprintf(str_c, "%s", line);
sprintf(str_c + strlen(line), "%s", str);
printf("%s\n", str_c);
exit(EXIT_FAILURE);
#else
fprintf(stderr, "An error has occurred\n");
exit(0);
#endif
}
C. printKeys函数
开发的时候方便调试,输出record数组中所有record的key
/**
*
* @param records record数组
* @param num record数组中的record数量
*
* @author Shihong Wang
* @date 2022.10.30
*/
void printKeys(record_t records[], int num)
{
if (NULL == records)
psort_error("record is NULL, did not malloc records? Or worker thread didn't run first?");
for (int i = 0; i < num; i++)
printf("%4d -> %11d\n", i, get_key(records[i]));
}
C. benchmark
为了通过比较选择速度最快的排序算法,因此主程序中通过定义BENCHMARK宏来测试不同排序算法的性能
int main(int argc, char *argv[])
{
if (argc != 3)
psort_error("Empty input file");
byteStream_t buffer;
#ifdef BENCHMARK
// Code for benchmark
clock_t start, end;
int byte = read_records(argv[i], &buffer, 0, -1);
printf("Test file: %s\n", argv[i]);
printf("%s -> %d bytes\n", argv[i], byte);
delim;
record_t *records;
int num = parse_records(buffer, &records, byte);
for (int j = 0; j < sizeof(sort_func) / sizeof(sort_func[0]); j++)
{
printf("Benchmark: %s\n", func_name[j]);
start = clock();
sort_func[j](records, num, false);
end = clock();
if (PRINTKEY == 1)
{
printf("After Sorts:\n");
printKeys(records, num);
}
printf("Sort time used: %4f seconds\n", (double)(end - start) / CLOCKS_PER_SEC);
delim;
}
#endif
return 0;
}
因此,最终主程序为
// #define BENCHMARK
#define MAIN
#define PRINTKEY 0
int main(int argc, char *argv[])
{
if (argc != 3)
psort_error("Empty input file");
byteStream_t buffer;
#ifdef BENCHMARK
// Code for benchmark
clock_t start, end;
int byte = read_records(argv[i], &buffer, 0, -1);
printf("Test file: %s\n", argv[i]);
printf("%s -> %d bytes\n", argv[i], byte);
delim;
record_t *records;
int num = parse_records(buffer, &records, byte);
for (int j = 0; j < sizeof(sort_func) / sizeof(sort_func[0]); j++)
{
printf("Benchmark: %s\n", func_name[j]);
start = clock();
sort_func[j](records, num, false);
end = clock();
if (PRINTKEY == 1)
{
printf("After Sorts:\n");
printKeys(records, num);
}
printf("Sort time used: %4f seconds\n", (double)(end - start) / CLOCKS_PER_SEC);
delim;
}
#endif
#ifdef MAIN
// Code for parallel sort
struct timezone tz;
struct timeval start, end;
gettimeofday(&start, &tz);
// init all
int byte = read_records(argv[1], &buffer, 0, -1);
init_config(byte);
pthread_mutex_init(&sorted_jobs_mutex, NULL);
pthread_cond_init(&sorted_jobs_cond, NULL);
sorted_jobs = (sort_job_t**)malloc(sizeof(sort_job_t*) * (run_config.sorted_job_num));
pthread_t *sort_thread_pool = (pthread_t *)malloc(sizeof(pthread_t) * run_config.sort_thread_num);
#ifdef DEBUG
printf("Test file: %s\n", argv[1]);
printf("%s -> %d bytes, %d records\n", argv[1], byte, run_config.record_num);
delim;
printf("Sort thread: %d, %d records per thread\n", run_config.sort_thread_num, run_config.record_per_thread);
printf("Merge thread: %d\n", run_config.merge_thread_num);
printf("Sorted job: %d\n", run_config.sort_thread_num);
delim;
#endif
// start sort threads
int seek = 0;
int record_left = run_config.record_num;
int all = 0;
sort_job_t **jobs = (sort_job_t **)malloc(sizeof(sort_job_t *) * run_config.sort_thread_num);
for (int j = 0; j < run_config.sort_thread_num; j++)
{
int num = run_config.record_per_thread;
if (j == run_config.sort_thread_num - 1){
num = -1;
all += record_left;
} else
all += num;
jobs[j] = sort_job_init(MERGE_SORT, seek, num, false, argv[1]);
pthread_create(&sort_thread_pool[j], NULL, sort_worker, (void *)jobs[j]);
seek += num;
record_left -= num;
#ifdef DEBUG
printf("Sort thread %d:\n", j);
printf("sort func %d -> %s\n", jobs[j]->sort_func, func_name[jobs[j]->sort_func]);
printf("seek -> %d, num -> %d\n", jobs[j]->seek, jobs[j]->num);
delim;
#endif
}
#ifdef DEBUG
printf("All allocated records: %d\n", all);
delim;
#endif
// start merge threads
bool wait_arg = true;
bool timeout_arg = false;
pthread_t *merge_thread_pool = (pthread_t *)malloc(sizeof(pthread_t) * run_config.merge_thread_num);
for (int j = 0; j < run_config.merge_thread_num; j++)
if (j == 0)
pthread_create(&merge_thread_pool[j], NULL, merge_worker, (void *)&wait_arg);
else
pthread_create(&merge_thread_pool[j], NULL, merge_worker, (void *)&timeout_arg);
for (int j = 0; j < run_config.sort_thread_num; j++)
pthread_join(sort_thread_pool[j], NULL);
for (int j = 0; j < run_config.merge_thread_num; j++)
pthread_join(merge_thread_pool[j], NULL);
// get done_job
pthread_mutex_lock(&sorted_jobs_mutex);
// 等待producer
while (is_empty())
pthread_cond_wait(&sorted_jobs_cond, &sorted_jobs_mutex);
sort_job_t* done_job = do_get();
// 唤醒consumer
pthread_cond_signal(&sorted_jobs_cond);
pthread_mutex_unlock(&sorted_jobs_mutex);
#ifdef DEBUG
printf("Finished, %d records sorted!\n", all);
printf("Writing...\n");
#endif
if (write_records(argv[2], done_job) != byte)
psort_error("read record and write record mismatch");
for (int j = 0; j < run_config.sort_thread_num; j++)
{
if (PRINTKEY == 1)
{
printf("Main, Thd -> %d: %s\n", j, func_name[jobs[j]->sort_func]);
printf("After Sorts:\n");
printKeys(jobs[j]->records, jobs[j]->num);
delim;
}
}
if (PRINTKEY == 1){
printf("Main, After Merge:\n");
// 下面因为要访问共享资源sorted_jobs,所以都是临界区
printKeys(done_job->records, done_job->num);
delim;
}
gettimeofday(&end, &tz);
int sec = end.tv_sec - start.tv_sec;
int usec = end.tv_usec - start.tv_usec;
if (usec < 0){
sec -= 1;
usec += 1000000;
}
float used = sec + usec / 1000000.0;
// printf("Main, sort %d records, using %.6f seconds\n", run_config.record_num, used);
#endif
return 0;
}
项目代码
代码已开源:https://github.com/jackwang0108/CS537-Project3.git
1. 项目结构
项目结构如下
tree -C ./
其中:
CMakeLists.txt组织项目tools文件中存放了工具脚本,包括生成用于测试的包含record二进制文件的gentest.sh,自动构建项目的autobuild.sh,自动测试的autotest.sh,以及按顺序输出二进制文件所有record的key的printkey.sh- 程序源码为
libpsort.h、libpsort.c、main.c,gentest.c和printkey.c为工具程序
2. 使用说明
A. 初始化项目
使用在项目根目录下的init.sh初始化项目
cd <path-to-project>
source init.sh
B. 编译
可以手动编译
cd <path-to-project>
mkdir build
cd build
cmake ..
make
或者在source init.sh后使用提供的自动编译工具
source init.sh
autobuild.sh

编译后将得到libppsort.a库和可执行文件,分别位于lib文件夹和bin文件夹下
tree -C -I build

C. 测试
使用gentest.sh生成测试文件。这里指定生成100个record
source init.sh
gentest.sh 10
测试文件将写入<path-toprojec>/test.bin文件中

而后使用printkey程序查看其中每个record的键值
./bin/printkey test.bin

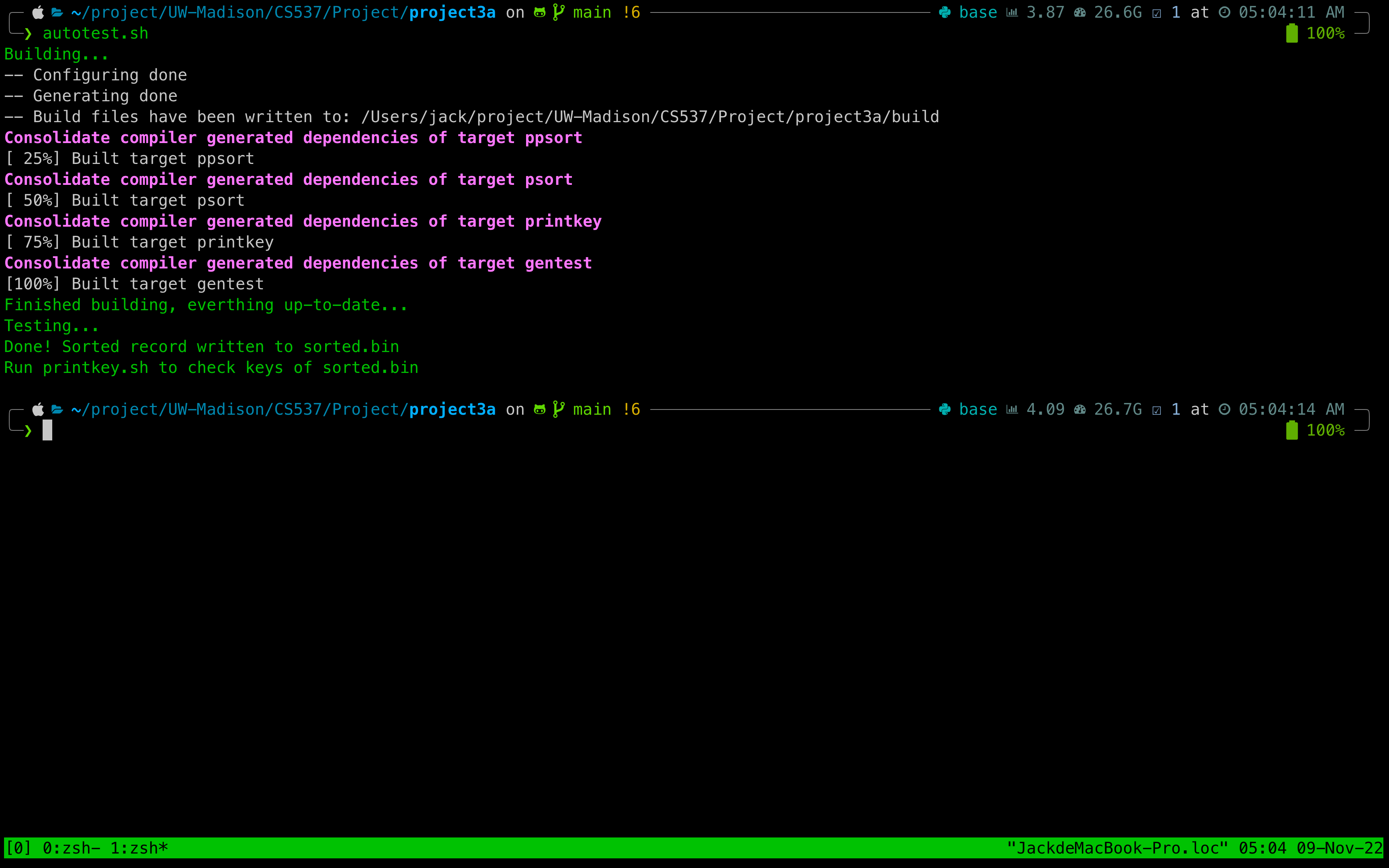
使用测试脚本autotest.sh进行测试,测试后的结果将写入sorted.bin中
autotest.sh
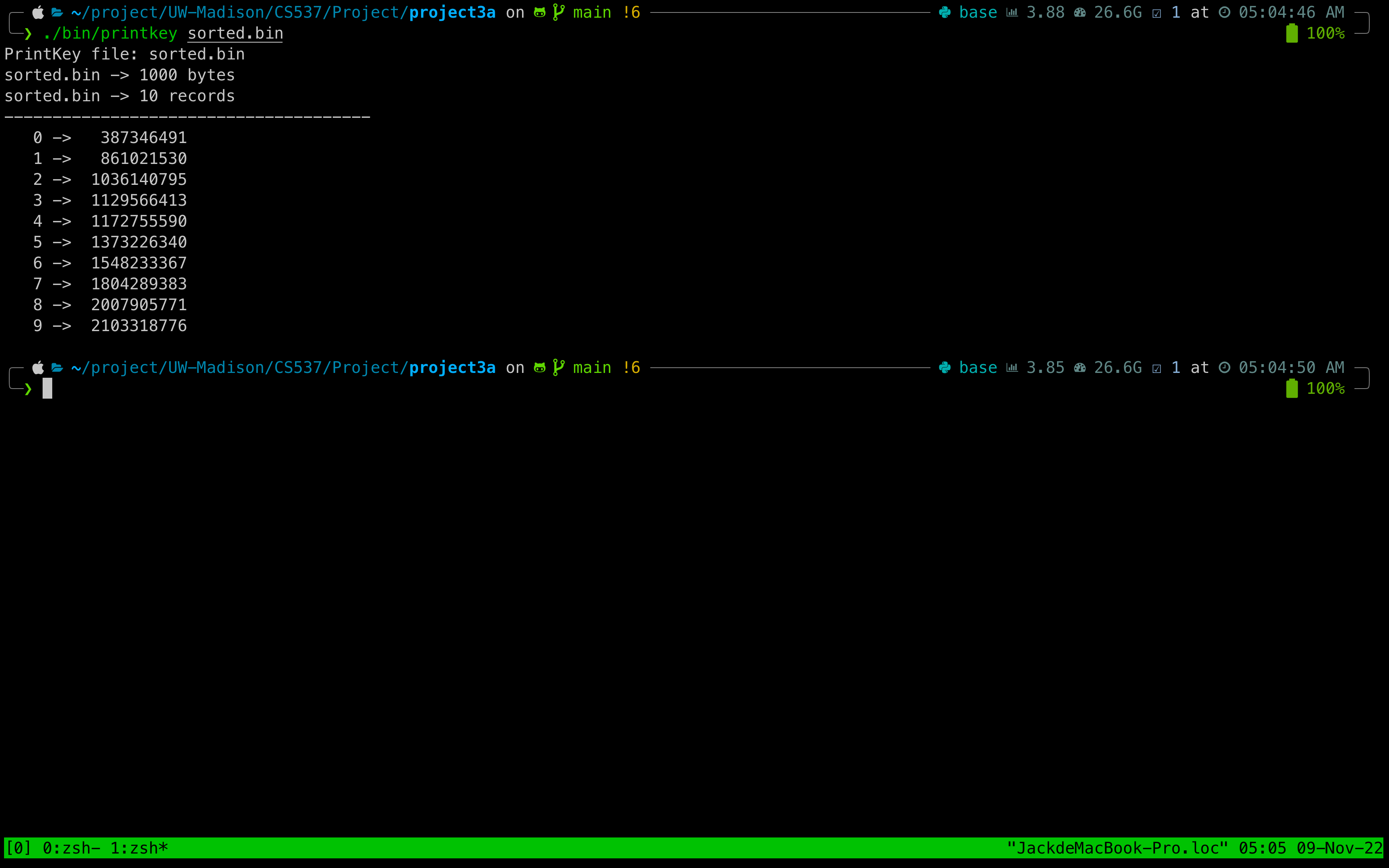
最后,查看排序后的结果
./bin/printkey sorted.bin
3. 性能测试
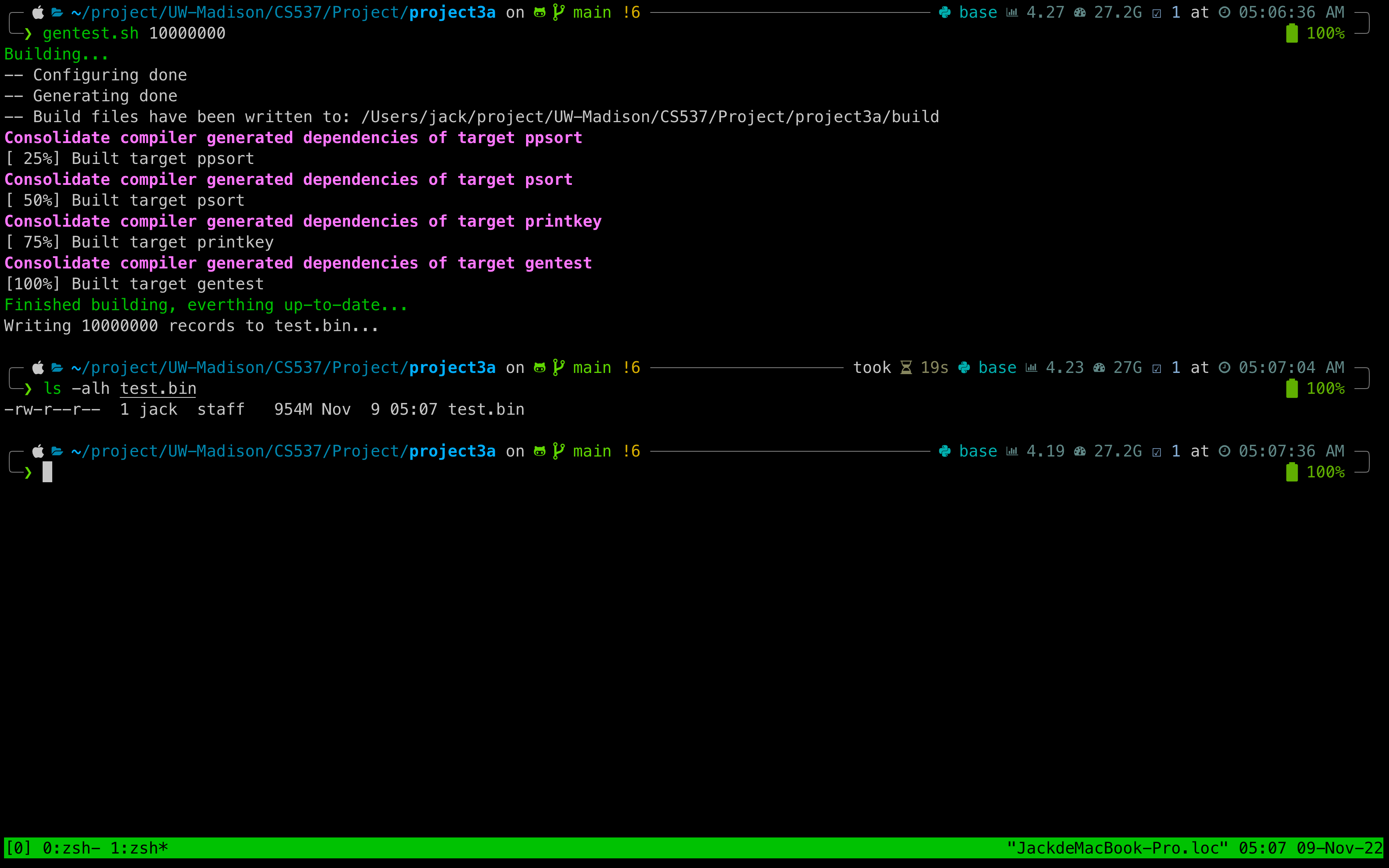
使用gentest.sh生成10,000,000(一百万个record),文件大小954M。对其进行排序
使用time进行计时
time ./bin/psort test.bin sorted.bin
包含将排序后文件写入到sorted.bin中,一共用时8.574秒,平均每秒处理十万个record




