Add System Call for XV6 (Unix Version 6)
This blog introduces system call function call of XV6 (Unix Version 6) and also teachs how to add a function call
1. What we want to do
We need to add my own system call trace(const char *pathname) and the second is getcount()
The function prototypes are
int trace(const char *pathname)
int getcount(void)
In the following blog, I will cover what is system call and then introduce how to add a system call.
2. Understanding the Makefile
To understand the xv6 system, we need to understand the Makefile first.
A. Debug command: make qemu-nox-gdb
The command used to debug the xv6 system is make qemu-nox-gdb, which means we make the target qemu-nox-gdb.
The target qemu-nox-gdb in Makefile is
qemu-nox-gdb: fs.img xv6.img .gdbinit
@echo "*** Now run 'gdb'." 1>&2
$(QEMU) -nographic $(QEMUOPTS) -S $(QEMUGDB)
which means before make target qemu-nox-gdb, we need to make target fs.img, xv6.img and .gdbinit.
And the definitions of macro QEMU, QEMUOPTS and QEMUGDB are
QEMU = $(shell if which qemu > /dev/null; \
then echo qemu; exit; \
elif which qemu-system-i386 > /dev/null; \
then echo qemu-system-i386; exit; \
elif which qemu-system-x86_64 > /dev/null; \
then echo qemu-system-x86_64; exit; \
else \
qemu=/Applications/Q.app/Contents/MacOS/i386-softmmu.app/Contents/MacOS/i386-softmmu; \
if test -x $$qemu; then echo $$qemu; exit; fi; fi; \
echo "***" 1>&2; \
echo "*** Error: Couldn't find a working QEMU executable." 1>&2; \
echo "*** Is the directory containing the qemu binary in your PATH" 1>&2; \
echo "*** or have you tried setting the QEMU variable in Makefile?" 1>&2; \
echo "***" 1>&2; exit 1)
QEMUOPTS = -drive file=fs.img,index=1,media=disk,format=raw -drive file=xv6.img,index=0,media=disk,format=raw -smp $(CPUS) -m 512 $(QEMUEXTRA)
QEMUGDB = $(shell if $(QEMU) -help | grep -q '^-gdb'; \
then echo "-gdb tcp::$(GDBPORT)"; \
else echo "-s -p $(GDBPORT)"; fi)
So, macro QEMU finds available qemu command on the machine and QEMUOPTS are command line options of qemu and QEMUGDB starts debug QEMU with gdb.
Note that in QEMUOPTS, -drive option defines two driver fs.img and vx6.img .
B. xv6.img
Backtracing, the target qemu-nox-gdb depends target xv6.img, so take a look at target xv6.img
xv6.img: bootblock kernel
dd if=/dev/zero of=xv6.img count=10000
dd if=bootblock of=xv6.img conv=notrunc
dd if=kernel of=xv6.img seek=1 conv=notrunc
The command of target xv6.img simply creates disk image xv6.img and then bitwise copy bootblock and kernel into disk image xv6.img.
C. kernel
Again, the target xv6.img depends target kernel, we need to take a look at it.
kernel: $(OBJS) entry.o entryother initcode kernel.ld
$(LD) $(LDFLAGS) -T kernel.ld -o kernel entry.o $(OBJS) -b binary initcode entryother
$(OBJDUMP) -S kernel > kernel.asm
$(OBJDUMP) -t kernel | sed '1,/SYMBOL TABLE/d; s/ .* / /; /^$$/d' > kernel.sym
Here, we can see that target kernel uses ld to link all objective file togeter and generate binary file kernel after -o option.
D. fs.img
Target qemu-nox-gdb also depends on target fs.xv6. Here’s the definition of target fs.vx6 and relevent macro
UPROGS=\
_cat\
_echo\
_forktest\
_grep\
_init\
_kill\
_ln\
_ls\
_mkdir\
_rm\
_sh\
_stressfs\
_usertests\
_wc\
_zombie\
fs.img: mkfs README $(UPROGS)
./mkfs fs.img README $(UPROGS)
Target fs.img write user program UPORGS into fs.img.
Summary
In summary, what does the command make qemu-nox-gdb do are:
- compile the kernel and write the kernel into
xv6.img - compile user programs and write user programs into
fs.img - start
qemuwith diskxv6.imgandfs.img - start
qemuwithgdbdebugging
After we firgure out the Makefile of the xv6 project, we are now getting into the xv6 project.
3. The Path of System Call
After looking the Makefile of xv6 project, we know that the kernel and user program are mutually independent programs. They are conceptually equal, both of them have main functions.
For example, in main.c, the main function of the program looks like
// Bootstrap processor starts running C code here.
// Allocate a real stack and switch to it, first
// doing some setup required for memory allocator to work.
int
main(void)
{
kinit1(end, P2V(4*1024*1024)); // phys page allocator
kvmalloc(); // kernel page table
mpinit(); // detect other processors
lapicinit(); // interrupt controller
seginit(); // segment descriptors
picinit(); // disable pic
ioapicinit(); // another interrupt controller
consoleinit(); // console hardware
uartinit(); // serial port
pinit(); // process table
tvinit(); // trap vectors // == 中断向量表
binit(); // buffer cache
fileinit(); // file table
ideinit(); // disk
startothers(); // start other processors
kinit2(P2V(4*1024*1024), P2V(PHYSTOP)); // must come after startothers()
userinit(); // first user process // == 开启第一个用户进程
mpmain(); // finish this processor's setup
}
and the main function of user program ls looks like
int
main(int argc, char *argv[])
{
int i;
if(argc < 2){
ls(".");
exit();
}
for(i=1; i<argc; i++)
ls(argv[i]);
exit();
}
So, the user program and kernel are two independent program.
Then, how does system call work?
A. User Program’s (Developer’s) Perspective of System Call
To start, we first look from the user program’s perspectie of system call.
// User program test_trace.c
#include "types.h"
#include "stat.h"
#include "user.h"
#include "fcntl.h"
int main(int argc, char *argv[])
{
int stdout = 1;
printf(stdout, "Start my syscall testing...\n");
trace("ls");
trace("pwd");
trace("test");
trace("666");
printf(stdout, "ls count = %d\n", getcount("ls"));
open("ls", O_RDONLY);
printf(stdout, "ls count = %d\n", getcount("ls"));
open("ls", O_RDONLY);
printf(stdout, "ls count = %d\n", getcount("ls"));
open("ls", O_RDONLY);
printf(stdout, "ls count = %d\n", getcount("ls"));
open("pwd", O_RDONLY);
printf(stdout, "pwd count = %d\n", getcount("pwd"));
open("test", O_RDONLY);
printf(stdout, "test count = %d\n", getcount("test"));
open("pwd", O_RDONLY);
printf(stdout, "pwd count = %d\n", getcount("pwd"));
open("666", O_RDONLY);
printf(stdout, "666 count = %d\n", getcount("666"));
printf(stdout, "test finished\n");
exit();
}
trace and getcount are two system call. So from the perspective of user program, system call are just like function calls.
By using these special function, the user program can leverage functionalities offered by the kernel.
B. Kernel’s (Operating System’s) Perspective of System Call
Let us take a look of what does system call looks like in the perspective of kernel.
kill is a system call, and it’s defined in proc.c.
// proc.c
// Kill the process with the given pid.
// Process won't exit until it returns
// to user space (see trap in trap.c).
int
kill(int pid)
{
struct proc *p;
acquire(&ptable.lock);
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){
if(p->pid == pid){
p->killed = 1;
// Wake process from sleep if necessary.
if(p->state == SLEEPING)
p->state = RUNNABLE;
release(&ptable.lock);
return 0;
}
}
release(&ptable.lock);
return -1;
}
So, from the perspective of kernel, system call are just normal functions defined in kernel.
But here’s the problem, user program and kernel are two program, they are mutually independent. Since they do not link together, how can one program calls functions defined in another program?
C. From User Program to Kernel
To solve the problem listed above, we need to understand the path from user program to kernel.
1) usys.S
The first step of system call is usys.S. It’s a AT&T format assembly, where it defines a macro function SYSCALL
#include "syscall.h"
#include "traps.h"
#define SYSCALL(name) \
.globl name; \
name: \
movl $SYS_ ## name, %eax; \
int $T_SYSCALL; \
ret
SYSCALL(fork)
SYSCALL(exit)
SYSCALL(wait)
SYSCALL(pipe)
SYSCALL(read)
SYSCALL(write)
SYSCALL(close)
SYSCALL(kill)
SYSCALL(exec)
SYSCALL(open)
SYSCALL(mknod)
SYSCALL(unlink)
SYSCALL(fstat)
SYSCALL(link)
SYSCALL(mkdir)
SYSCALL(chdir)
SYSCALL(dup)
SYSCALL(getpid)
SYSCALL(sbrk)
SYSCALL(sleep)
SYSCALL(uptime)
## is concate operator in assembly, so after passing fork as parameter of SYSCALL, the function looks like
; SYSCALL(fork) will expand as
#define SYSCALL(fork) \
.globl fork; \
fork: \
movl $SYS_fork, %eax; \
int $T_SYSCALL; \
ret
Variable SYS_fork is defined in syscall.h
// syscall.h
// System call numbers
#define SYS_fork 1
#define SYS_exit 2
#define SYS_wait 3
#define SYS_pipe 4
#define SYS_read 5
#define SYS_kill 6
#define SYS_exec 7
#define SYS_fstat 8
#define SYS_chdir 9
#define SYS_dup 10
#define SYS_getpid 11
#define SYS_sbrk 12
#define SYS_sleep 13
#define SYS_uptime 14
#define SYS_open 15
#define SYS_write 16
#define SYS_mknod 17
#define SYS_unlink 18
#define SYS_link 19
#define SYS_mkdir 20
#define SYS_close 21
Also, the value of variable T_SYSCALL is 64, defined in traps.h
// These are arbitrarily chosen, but with care not to overlap
// processor defined exceptions or interrupt vectors.
#define T_SYSCALL 64 // system call
#define T_DEFAULT 500 // catchall
In summary, the macro function SYSCALL defines a assembly function that store the system call number into eax register and then call #64 interrput.
And usys.S simply defines assembly functions for all system call.
2) vector.S
The next stop system call is vector.S, #64 is defined here.
.globl vector64
vector64:
pushl $0
pushl $64
jmp alltraps
vector.S simply push immediate number 0 and 64 into stack and then jump to function alltraps.
3) trapasm.S
alltraps is also an assembly function that defined in trapasm.S
.globl alltraps
alltraps:
# Build trap frame.
pushl %ds
pushl %es
pushl %fs
pushl %gs
pushal
# Set up data segments.
movw $(SEG_KDATA<<3), %ax
movw %ax, %ds
movw %ax, %es
# Call trap(tf), where tf=%esp
pushl %esp
call trap
addl $4, %esp
Before jump to function trap, function alltraps.S push register into stack and them call function trap.
4) trap.c
Function trap is defined in trap.c and trap is a C function.
The source code of trap doesn’t matter, the only thing we need to know is that on line #9, it calls syscall function to deal different system call.
What matters is:
traptakes an argumentstruct trapframe *tf. Calling a function and passing argument is easy withinC, we can calltrapliketrap(mytf)inmy_trap_call_test.c. But how to pass argument when we callCfunctions in assembly codes liketrapasm.S?
//PAGEBREAK: 41
void
trap(struct trapframe *tf)
{
if(tf->trapno == T_SYSCALL){
if(myproc()->killed)
exit();
myproc()->tf = tf;
syscall();
if(myproc()->killed)
exit();
return;
}
switch(tf->trapno){
case T_IRQ0 + IRQ_TIMER:
if(cpuid() == 0){
acquire(&tickslock);
ticks++;
wakeup(&ticks);
release(&tickslock);
}
lapiceoi();
break;
case T_IRQ0 + IRQ_IDE:
ideintr();
lapiceoi();
break;
case T_IRQ0 + IRQ_IDE+1:
// Bochs generates spurious IDE1 interrupts.
break;
case T_IRQ0 + IRQ_KBD:
kbdintr();
lapiceoi();
break;
case T_IRQ0 + IRQ_COM1:
uartintr();
lapiceoi();
break;
case T_IRQ0 + 7:
case T_IRQ0 + IRQ_SPURIOUS:
cprintf("cpu%d: spurious interrupt at %x:%x\n",
cpuid(), tf->cs, tf->eip);
lapiceoi();
break;
//PAGEBREAK: 13
default:
if(myproc() == 0 || (tf->cs&3) == 0){
// In kernel, it must be our mistake.
cprintf("unexpected trap %d from cpu %d eip %x (cr2=0x%x)\n",
tf->trapno, cpuid(), tf->eip, rcr2());
panic("trap");
}
// In user space, assume process misbehaved.
cprintf("pid %d %s: trap %d err %d on cpu %d "
"eip 0x%x addr 0x%x--kill proc\n",
myproc()->pid, myproc()->name, tf->trapno,
tf->err, cpuid(), tf->eip, rcr2());
myproc()->killed = 1;
}
The answer to problem 1 is that C passes function argument via stack. When we call functions between C, it is the compiler who autmatically push the argument into stack and hide all details.
So, when we call C functions in assembly, we need to push the argument into stack by ourselves. That’s the reason why assembly function alltraps pushes register into stack. The order of push is exactly reverse to the definition of trapframe:
// definition of trapframe in x86.h
//PAGEBREAK: 36
// Layout of the trap frame built on the stack by the
// hardware and by trapasm.S, and passed to trap().
struct trapframe {
// registers as pushed by pusha
uint edi;
uint esi;
uint ebp;
uint oesp; // useless & ignored
uint ebx;
uint edx;
uint ecx;
uint eax;
// rest of trap frame
ushort gs;
ushort padding1;
ushort fs;
ushort padding2;
ushort es;
ushort padding3;
ushort ds;
ushort padding4;
uint trapno;
// below here defined by x86 hardware
uint err;
uint eip;
ushort cs;
ushort padding5;
uint eflags;
// below here only when crossing rings, such as from user to kernel
uint esp;
ushort ss;
ushort padding6;
};
// push in alltraps
.globl alltraps
alltraps:
# Build trap frame.
pushl %ds
pushl %es
pushl %fs
pushl %gs
pushal
# Set up data segments.
movw $(SEG_KDATA<<3), %ax
movw %ax, %ds
movw %ax, %es
# Call trap(tf), where tf=%esp
pushl %esp
call trap
addl $4, %esp
Nonetheless, the most important thing here in trap.c is that we are already executing kernel codes, which means:
- we are already in kernel mode
- we jump from user program to kernel.
So, in summary, the os uses three assembly functions to jump from User Program to Kernel.
D. Interior Mechanism of Syscall
Continue, the function syscall is defined in syscall.c.
// syscall.c
extern int sys_chdir(void);
extern int sys_close(void);
extern int sys_dup(void);
extern int sys_exec(void);
extern int sys_exit(void);
extern int sys_fork(void);
extern int sys_fstat(void);
extern int sys_getpid(void);
extern int sys_kill(void);
extern int sys_link(void);
extern int sys_mkdir(void);
extern int sys_mknod(void);
extern int sys_open(void);
extern int sys_pipe(void);
extern int sys_read(void);
extern int sys_sbrk(void);
extern int sys_sleep(void);
extern int sys_unlink(void);
extern int sys_wait(void);
extern int sys_write(void);
extern int sys_uptime(void);
static int (*syscalls[])(void) = {
[SYS_fork] sys_fork,
[SYS_exit] sys_exit,
[SYS_wait] sys_wait,
[SYS_pipe] sys_pipe,
[SYS_read] sys_read,
[SYS_kill] sys_kill,
[SYS_exec] sys_exec,
[SYS_fstat] sys_fstat,
[SYS_chdir] sys_chdir,
[SYS_dup] sys_dup,
[SYS_getpid] sys_getpid,
[SYS_sbrk] sys_sbrk,
[SYS_sleep] sys_sleep,
[SYS_uptime] sys_uptime,
[SYS_open] sys_open,
[SYS_write] sys_write,
[SYS_mknod] sys_mknod,
[SYS_unlink] sys_unlink,
[SYS_link] sys_link,
[SYS_mkdir] sys_mkdir,
[SYS_close] sys_close,
};
void
syscall(void)
{
int num;
struct proc *curproc = myproc();
num = curproc->tf->eax;
if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {
curproc->tf->eax = syscalls[num]();
} else {
cprintf("%d %s: unknown sys call %d\n",
curproc->pid, curproc->name, num);
curproc->tf->eax = -1;
}
}
Variable syscall is a function array, and SYS_xxx are macros defined in syscall.h (refer syscall.h)
Rember, system call number is store in eax (refer usys.S).
So, syscall first get the system call number from eax register (line #55), and then pick out corresponding system call function to run (line #57).
extern is used to mark up system call function like sys_exit, sys_close, and sys_mkdir are defined in other files,
Finally, take a look at the real definition of sys_kill in sysproc.c
// sysproc.c
int
sys_kill(void)
{
int pid;
if(argint(0, &pid) < 0)
return -1;
return kill(pid);
}
and kill in proc.c
// proc.c
// Kill the process with the given pid.
// Process won't exit until it returns
// to user space (see trap in trap.c).
int
kill(int pid)
{
struct proc *p;
acquire(&ptable.lock);
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){
if(p->pid == pid){
p->killed = 1;
// Wake process from sleep if necessary.
if(p->state == SLEEPING)
p->state = RUNNABLE;
release(&ptable.lock);
return 0;
}
}
release(&ptable.lock);
return -1;
}
F. One More Thing: Passing Argument
User program can include user.h, where prototypes of system call are provided.
// user.h
// system calls
int fork(void);
int exit(void) __attribute__((noreturn));
int wait(void);
int pipe(int*);
int write(int, const void*, int);
int read(int, void*, int);
int close(int);
int kill(int);
int exec(char*, char**);
int open(const char*, int);
int mknod(const char*, short, short);
int unlink(const char*);
int fstat(int fd, struct stat*);
int link(const char*, const char*);
int mkdir(const char*);
int chdir(const char*);
int dup(int);
int getpid(void);
char* sbrk(int);
int sleep(int);
int uptime(void);
However, the function prototype defined in syscall.c has not argument (refer syscall.c).
extern int sys_chdir(void);
extern int sys_close(void);
extern int sys_dup(void);
extern int sys_exec(void);
extern int sys_exit(void);
extern int sys_fork(void);
extern int sys_fstat(void);
extern int sys_getpid(void);
extern int sys_kill(void);
extern int sys_link(void);
extern int sys_mkdir(void);
extern int sys_mknod(void);
extern int sys_open(void);
extern int sys_pipe(void);
extern int sys_read(void);
extern int sys_sbrk(void);
extern int sys_sleep(void);
extern int sys_unlink(void);
extern int sys_wait(void);
extern int sys_write(void);
extern int sys_uptime(void);
As explained ahead, C uses stack to pass the argument when calling function. So, we can actually get argument via calling program’s stack.
Here, we remain the pototype argument void is because the function array syscall that forces us keeping the prototype same argument.
To get the argument from calling program’s stack, we can use function argstr and argint defined in syscall.c
// Fetch the int at addr from the current process.
int
fetchint(uint addr, int *ip)
{
struct proc *curproc = myproc();
if(addr >= curproc->sz || addr+4 > curproc->sz)
return -1;
*ip = *(int*)(addr);
return 0;
}
// Fetch the nul-terminated string at addr from the current process.
// Doesn't actually copy the string - just sets *pp to point at it.
// Returns length of string, not including nul.
int
fetchstr(uint addr, char **pp)
{
char *s, *ep;
struct proc *curproc = myproc();
if(addr >= curproc->sz)
return -1;
*pp = (char*)addr;
ep = (char*)curproc->sz;
for(s = *pp; s < ep; s++){
if(*s == 0)
return s - *pp;
}
return -1;
}
// Fetch the nth 32-bit system call argument.
int
argint(int n, int *ip)
{
return fetchint((myproc()->tf->esp) + 4 + 4*n, ip);
}
// Fetch the nth word-sized system call argument as a string pointer.
// Check that the pointer is valid and the string is nul-terminated.
// (There is no shared writable memory, so the string can't change
// between this check and being used by the kernel.)
int
argstr(int n, char **pp)
{
int addr;
if(argint(n, &addr) < 0)
return -1;
return fetchstr(addr, pp);
}
4. Add trace and getcount
After figuring out how the system call works in xv6 system, we start to add trace and getcount systemcall.
1. Add system call number
First, we need to add system call number in syscall.h
// my syscall
#define SYS_trace 22
#define SYS_getcount 23

2. Add SYSCALL Macro
The second step is to add SYSCALL macro in usys.S
SYSCALL(trace)
SYSCALL(getcount)

3. Add prototype in syscall.c
Add my system call function prototype in syscall.c
// my syscall
extern int sys_trace(void);
extern int sys_getcount(void);
static int (*syscalls[])(void) = {
[SYS_fork] sys_fork,
[SYS_exit] sys_exit,
[SYS_wait] sys_wait,
[SYS_pipe] sys_pipe,
[SYS_read] sys_read,
[SYS_kill] sys_kill,
[SYS_exec] sys_exec,
[SYS_fstat] sys_fstat,
[SYS_chdir] sys_chdir,
[SYS_dup] sys_dup,
[SYS_getpid] sys_getpid,
[SYS_sbrk] sys_sbrk,
[SYS_sleep] sys_sleep,
[SYS_uptime] sys_uptime,
[SYS_open] sys_open,
[SYS_write] sys_write,
[SYS_mknod] sys_mknod,
[SYS_unlink] sys_unlink,
[SYS_link] sys_link,
[SYS_mkdir] sys_mkdir,
[SYS_close] sys_close,
[SYS_trace] sys_trace,
[SYS_getcount] sys_getcount
};
4. Realize trace and getcount
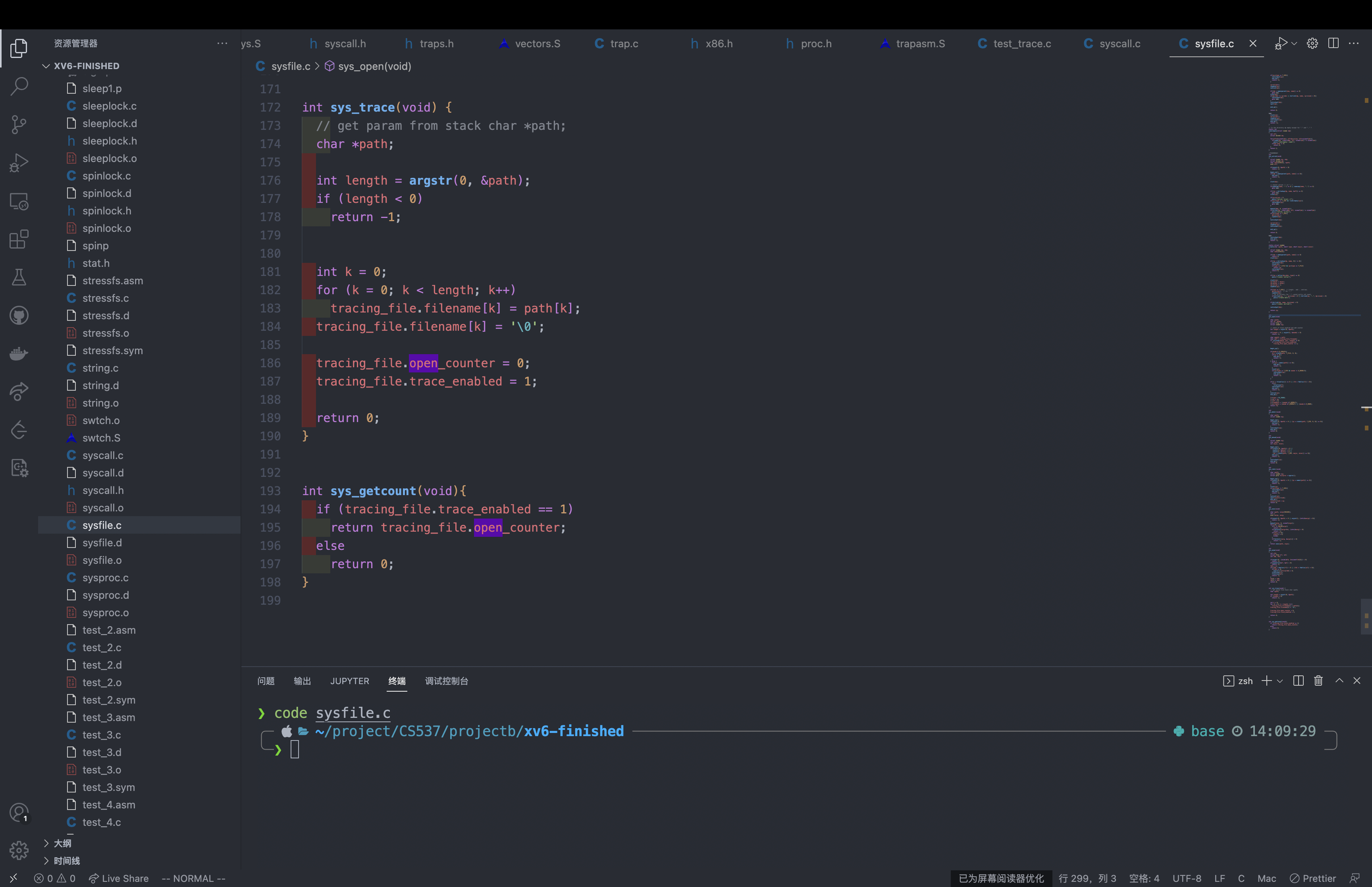
Finally, realize trace and getcount in sysfile.c
// sysfile.c
// my syscall data structure
typedef struct trace_file
{
char filename[256];
int open_counter;
int trace_enabled;
} trace_file;
int num_traced;
trace_file tracing_file;
int sys_trace(void) {
// get param from stack char *path;
char *path;
int length = argstr(0, &path);
if (length < 0)
return -1;
int k = 0;
for (k = 0; k < length; k++)
tracing_file.filename[k] = path[k];
tracing_file.filename[k] = '\0';
tracing_file.open_counter = 0;
tracing_file.trace_enabled = 1;
return 0;
}
int sys_getcount(void){
if (tracing_file.trace_enabled == 1)
return tracing_file.open_counter;
else
return 0;
}
as well as modify sysopen
int
sys_open(void)
{
char *path;
int fd, omode;
struct file *f;
struct inode *ip;
// check if trace enabled and add counter
int length = argstr(0, &path);
if(length < 0 || argint(1, &omode) < 0)
return -1;
char *ppath = path;
char *ptf = tracing_file.filename;
if (strncmp(ppath, ptf, length) == 0)
if (tracing_file.trace_enabled)
tracing_file.open_counter += 1;
begin_op();
if(omode & O_CREATE){
ip = create(path, T_FILE, 0, 0);
if(ip == 0){
end_op();
return -1;
}
} else {
if((ip = namei(path)) == 0){
end_op();
return -1;
}
ilock(ip);
if(ip->type == T_DIR && omode != O_RDONLY){
iunlockput(ip);
end_op();
return -1;
}
}
if((f = filealloc()) == 0 || (fd = fdalloc(f)) < 0){
if(f)
fileclose(f);
iunlockput(ip);
end_op();
return -1;
}
iunlock(ip);
end_op();
f->type = FD_INODE;
f->ip = ip;
f->off = 0;
f->readable = !(omode & O_WRONLY);
f->writable = (omode & O_WRONLY) || (omode & O_RDWR);
return fd;
}

5. Result
Since this blog is actually a project of CS537: Operating System of UW-Madison, so the course do offer a test script to test the system call you developed.
PS: The courses material is open source, and serves as material of the book Operating System: Three Easy Piece by Remzi, the lecture of this course. He create a repository called OS Steps, and pull all course materials like project introduction, project testing tools in that material. So maybe you can find the testing script in Remzi’s github.
To strat test, simply
~cs537-1/test/p1b/runtest.sh -c




