
看这篇文章的阅读笔记前,建议先去看一下这篇阅读笔记的前言:前言
0. 评价
我对这篇文章的评价如下:
这篇文章首先反应了当时的时代背景
现在看来,这个已经是上古时期的文章了。而在上古时期(2012-2016),网络如果泛化性能上不去,就会认为是模型overfit了小的训练集,因为模型学习能力太强,所以学到了小数据集的bias。然而其实在今天,我们知道模型的泛化能力差并不一定是overfit了小数据集,完全有可能是因为模型optimization做的不好,也就是进行了optimization,但又没有完全进行。更形象的说,你还没有达到一个比较好的Local Minima,就去和容易optimize的模型的好的Local Minima去比较。
那么,意识到泛化性能差可能不是由于overfit而是由于优化存在问题这件事是在2016年的ResNet中发现的,ResNet文章中提出了做了一个思想实验,
Identical Mapping,从而说明深的模型的性能下界至少是浅的模型的性能(放心吧,ResNet未来一定会写笔记的)。因此在2012-2016年间,大家在做的事情的可以分成三个:- 就是寻找能够使得泛化性能更好的方法,包括引入正则(Batch Norm)、对梯度下降下手……
- 提出新的,准确率更佳的模型,例如:GoogLeNet、VGGNet等等;
- 把深度学习,或者说CNN当成工具去解决不同领域的问题,就类似于CNN是一个Hammer,在不同的领域去找钉子砸
虽然说很多文章的模型得到的了比较好的效果,但是他们并没有意识到它们的方法其实是提升了优化的效果,还是认为他们减轻了overfit小数据集。
其次,这篇文章开启了未来一段时间内的研究
而具体的,这篇文章的贡献有:
使用了
ReLu激活函数,大大加速了模型的训练这篇文章发表前,有很多的模型性能也提不上去,大家就会说是模型的Overfitting问题很严重,但其实根本原因还是模型没有优化好,而先前的模型没有优化好的一个重要原因就是使用tanh、sigmoid这类激活函数激活函数太复杂了,优化太慢、太复杂
文章使用到的数据增强方法,成为后来数据增强的标准化方法
文章把原始输入图像截取出$224\times224$的Patch,这一尺寸和方法成为后来诸多方法沿用的尺寸
文章在测试阶段使用的数据增强成为后来测试方法的标准。
文章把一个测试图像,左上角、右上角、左下角、右下角和中心截取出来5个Patch进行Voting,这一方法成为后来方法测试的标注。
下面就让我们一起来解开这篇论文的庐山真面目。

1. 动机
按照我的习惯,解析一篇论文时一定要弄清楚论文的动机是什么?弄清楚作者为什么要这么做,目的是什么,以及解决了一个什么样的问题?只有了解清楚了这一过程,才有助于引导自己形成类似的思维模式,从而顺着这一思路想出自己的改进点,而不仅仅只是说会实现这个网络了,能跑通代码就完事。技术只是外功,思想与理念才是内功。
动机1:CNN容量更大、学习能力更强
在论文的介绍部分作者提到,目前进行物体识别的方法在根本上都使用了机器学习的方法。而为了提高模型的性能,人们收集了大量的数据集,早期的数据集中标记的数据量只有上千、上万张图像,这个体量的数据集对于一些简单的任务来说已经足够了,例如MNIST手写数字识别问题。但是,现实中的物体却有非常大的多样性(Diversity),因此学习如何识别现实中的物体就需要更大的训练数据。
所以就有了ImageNet这样大的数据集、在有了大的数据量之后,现在问题就是模型有没有能力去学习这么大的数据集。因此,一个真正实用的模型必须要有要拥有很多的容量来学习。而卷积神经网络(CNN)就是一类拥有强大学习能力的模型。CNN的容量能够通过其深度与广度进行控制。
动机2:GPU的硬件支持
文章说了很多CNN的很多很多非常诱人的性质,包括但不限于学习容量大、性能高。但是训练一个神经网络并且把它们放到大规模数据集上进行验证的代价依旧是非常高昂的。因此,文章的第二个动机就是,在2011年前后,Nividia推出的GPU具有高算力,并且支持用户编程调用GPU去进行计算。而在2011年,已经能够在GPU上运行的、高度优化的2D卷积的实现,因此为训练大规模的CNN提供了动力。所以使得在ImageNet上去训练一个大型的CNN成为了可能。
总结一下,这两个动机,一个是说CNN这个东西好,另外一个是说CNN这个东西用GPU可以训练出来。所以自然而然,这篇文章要用CNN去进行物体识别。
2. 思路
既然前面在动机上说了ImageNet有足够多的样本,支持我们学习出来强大的模型,而CNN又有足够的容量去从ImageNet中学习到表示(Representation),GPU又为CNN的训练提供了支持。因此,自然而然,这篇文章的思路就是用GPU在ImageNet上训练一个CNN。
所以,这篇文章的思路其实非常简单,精彩之处还要看后面方法部分的几个创新。
3. 技术手段(方法)
相比于方法,其实我更愿意称文章的这一部分为技术手段,因为正如我在前面所说的:
按照我的习惯,解析一篇论文时一定要弄清楚论文的动机是什么?弄清楚作者为什么要这么做,目的是什么,以及解决了一个什么样的问题?只有了解清楚了这一过程,才有助于引导自己形成类似的思维模式,从而顺着这一思路想出自己的改进点,而不仅仅只是说会实现这个网络了,能跑通代码就完事。技术只是外功,思想与理念才是内功。
读一篇文章最重要的就是了解其思想,明白其思路,而技术技巧只不过是其思想的承载罢了。所以下面就讲解这篇文章的几个技术的要点。
A. ReLU Nonlinearity
文章在技术上的第一个创新就是使用了Rectified Linear Units (ReLUs)来作为激活层的激活函数。因为之前的文章,往往都是使用Sigmoid、tanh这样的激活函数。而Sigmoid和tanh这样的激活函数会造成梯度消失(Vanishing Gradient)和梯度爆炸(Gradient Explosion)这样的问题。
梯度消失(Vanishing Gradient):反向传播的时候,上一层的梯度不为0,但是经过这一层之后梯度就变成0了。这是因为这一层的参数绝大多数都为0,导致的局部导数为0。这个问题对于Sigmoid和tanh这样在边缘饱和的激活函数来说非常常见。
`梯度爆炸(Gradient Explosion):反向传播的时候,上一层的梯度是一个合理的数(一般模在1左右),但是经过这一层之后梯度就变成几百几千了,很快就会让模型里的参数变成NaN。
这两个激活函数除了会对梯度造成影响外,还会大量的计算$e^x$这样的取指数操作,会消耗大量的计算资源。因此,传统的网络中大量的使用Sigmoid和tanh这样的函数,一个是梯度无法更新,造成难以优化,另一个是计算量太大,假设对梯度没有影响,优化花费时间也要很久。

因此就换成了ReLu激活函数,ReLu的表达式如下

其梯度要么为0,要么为1,计算只需要一个简单的比较运算即可。因此满足了计算量小、梯度维持在合理的区间内的这一个要求。
未来说明ReLu的高效性,作者把用了一个四层的网络,网络中的激活函数分别使用Sigmoid和ReLu进行了两次实验,得到的实验结果如下:

Figure 1: A four-layer convolutional neural network with ReLUs (solid line) reaches a 25% training error rate on CIFAR-10 six times faster than an equivalent network with tanh neurons(dashed line). The learning rates for each network were chosen independently to make training as fast as possible. No regularization of any kind was employed. The magnitude of the effect demonstrated here varies with network architecture, but networks with ReLUs consistently learn several times faster than equivalents with saturating neurons.
即同样是达到25%的错误率,使用ReLu的模型比使用Sigmoid的模型速度快了6倍。而且不管怎么为Sigmoid的模型调学习率,总是使用ReLu的模型速度更快。
因此这就说明了使用ReLu可以大大简化模型的训练。
B. Training on Multiple GPUs
这个手段其实没啥好说的,主要就是写代码实现以下,原文这段主要就是介绍了一下实现的细节:
A single GTX 580 GPU has only 3GB of memory, which limits the maximum size of the networks that can be trained on it. It turns out that 1.2 million training examples are enough to train networks which are too big to fifit on one GPU. Therefore we spread the net across two GPUs. Current GPUs are particularly well-suited to cross-GPU parallelization, as they are able to read from and write to one another’s memory directly, without going through host machine memory. The parallelization scheme that we employ essentially puts half of the kernels (or neurons) on each GPU, with one additional trick: the GPUs communicate only in certain layers. This means that, for example, the kernels of layer 3 take input from all kernel maps in layer 2. However, kernels in layer 4 take input only from those kernel maps in layer 3 which reside on the same GPU. Choosing the pattern of connectivity is a problem for cross-validation, but this allows us to precisely tune the amount of communication until it is an acceptable fraction of the amount of computation.
现在Pytorch中已经有多卡训练的框架,我们直接调用即可。
C. Local Response Normalization
这篇文章的第三个创新点就是提出了一个新的网络层,称为Local Response Normalization(LRN)。这个层的原理就是观察到人类的大脑皮层中有这样一个现象:一个活跃的神经元会抑制周围的几个神经元。那么对于神经网络来说,神经元之间的连接是依靠参数矩阵实现的,所以就是就是大的经过激活函数激活后的激活会抑制局部其他的值。
所以操作起来就是在每一个神经元局部,比如3*3的小范围内,根据这个神经元的激活值去调整这九个激活值。调整的公式如下:
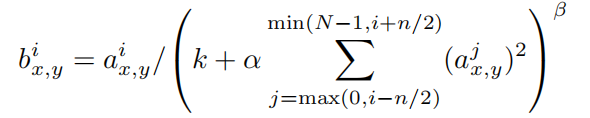
Denoting by $a^i{x,y}$, the activity of a neuron computed by applying kernel $i$ at position $(x, y)$ and then applying the ReLU nonlinearity, the response-normalized activity $b^i{x,y}$ is given by the expression, where the sum runs over $n$ “adjacent” kernel maps at the same spatial position, and $N$ is the total number of kernels in the layer.
不过其实现在看,LRN这个东西其实没啥用,这篇文章的几个技术里用处最大的就是ReLU和模型结构。
D. Overlapping Pooling
这段是说,CNN中的池化层可以帮助网络来总结(Summarize)同一个卷积核计算得到的activation map中相邻的几个激活值。传统上的池化,池化窗口之间是没有重叠的。更加准确的说,假设一个池化层是$z\times z$大小的,每次水平或者竖直移动$s$个像素。如果$s=z$的话那么就是传统的池化,但是如果$s<z$的话就是这里说的重叠池化(Overlapping Pooling)。这篇文章里取$s=2,z=3$。
在今天来说,所谓Overlapping Pooling其实都是调API的时候指定一下stride就行。
E. Overall Architecture
接下来就是模型整体的结构了。网络包含八个含有可训练参数的层,前五层是卷积层,后三个是全连接层。最后一个全连接层的输出是1000维的向量。这个向量而后被softmax吃进去,计算得到在1000个类别标签上的分布。最后预测输入图像属于哪个类就是取最后经过逻辑回归后得到的最大的那个值属于的类。
因为这篇文章的网络拆分到了两个GPU上,所以文章还对怎么拆分的进行了一下说明:
- 第三四五层的卷积层都只连接到了相同GPU上的前一层的输出,而第三层卷积层除了接受自己这个GPU上的输出以外,还连接了另外一块GPU上的输出。
- LRN只在第一和第二层后面接着,第三四五层中间没有池化或者LRN
- 池化层在所有层后都接着
网络中间每一层具体的参数为:
- 第一个卷积层对224*224*3的输入图像进行卷积,一共有96个11*11*3的卷积核,以4为步长进行滑动。他这里是把96个activation map放到两个GPU上去了,一个GPU上有48个激活层。
- 第二个卷积层输入第一个卷积层池化和LRN之后activation map,第二层一共有256个5*5*48大小的卷积核
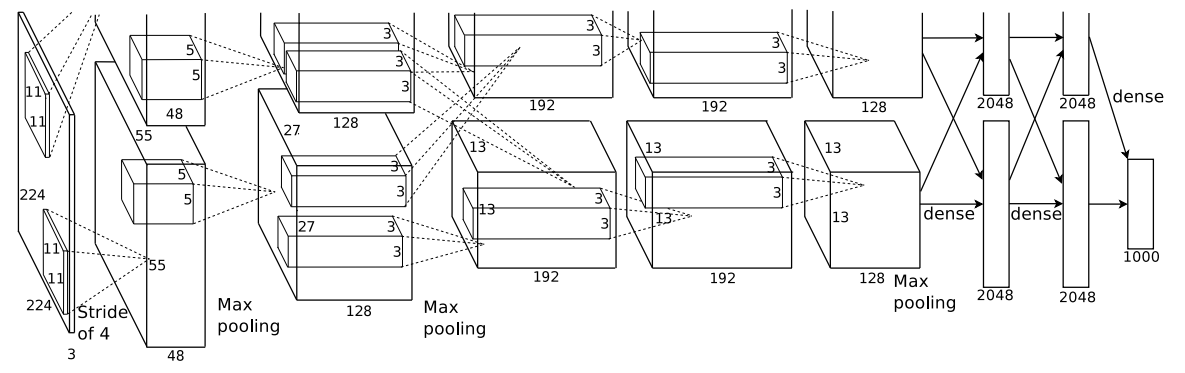
Figure 2: An illustration of the architecture of our CNN, explicitly showing the delineation of responsibilities between the two GPUs. One GPU runs the layer-parts at the top of the figure while the other runs the layer-parts at the bottom. The GPUs communicate only at certain layers. The network’s input is 150,528-dimensional, and the number of neurons in the network’s remaining layers is given by 253,440–186,624–64,896–64,896–43,264–4096–4096–1000.
4. 训练细节
其实从我自己训练模型的经验来说,想要训练出来一个有用的模型,训练的过程中是需要很多技巧的。所以作为深度学习开山鼻祖性质的第一篇文章,其中的训练细节还是需要讲讲的。
A. 数据增强
数据增强已经被认为是非常有效的增强模型性能的方法,目前有不同的观点解释,一种观点认为我们对数据进行增强的时候人为引入了噪声,因此经过学习之后模型就可以分辨出噪声,因而提升了性能;另外一种观点认为数据增强了之后,图像会蕴含更多的模式,采样得到的图像的分布越接近真实的分布会模型能够学习到更多的特征,因此性能更加鲁棒。
但是,前面提到过本文提出的时代下,模型性能不好就认为是模型过于强大,过拟合了数据集,但我们现在其实知道是因为优化做的不好。所以本文的作者认为即便是ImageNet这么大的数据集,还是会被AlexNet给过拟合,所以需要进行数据增强。所以原文中才会把数据增强这一节放到减缓过拟合这一章下。

平移和翻转(Translation & Flipping)
AlexNet使用的第一种数据增强方式是对图像进行平移和水平翻转。
在训练阶段,首先把原始输入的$256\times256$的图像随机截取成$224\times224$大小的Patch。然后对截取到了Patch进行随机翻转。原文中说这样干能够让可用的数据扩充到2048倍,但我真没搞懂这个2048怎么算的。
The first form of data augmentation consists of generating image translations and horizontal reflections. We do this by extracting random 224 × 224 patches (and their horizontal reflections) from the 256×256 images and training our network on these extracted patches. This increases the size of our training set by a factor of 2048, though the resulting training examples are, of course, highly interdependent
而在测试阶段,也会进行数据增强,不过此时的意义可能更多的在于集成方法。测试时,一张图像会选取四个角落和中心的五个Patch,再进行水平翻转之后得到10张图像。最后这十张图像经过softmax得到十个概率向量,最终分类的结果是这是个概率向量平均之后取argmax的结果。
颜色调整(Color Jitting)
第二种数据增强的方式就是调整训练图像的RGB三个通道的强度,具体来说就是先对ImageNet中的平均图像进行PCA,得到几个主成分$\lambda_i$和对应的向量$p_i$。接下来从高斯分布中抽样得到几个参数$\alpha_i$,按照下式组合起来之后,加到训练图像上去

B. Dropout
文章中训练时候使用的第二个技术就是Dropout。dropout主要用在测试阶段,在前向传播的时候,会随机选择$p$的神经元(注意$p<1$),让他们的值变成0。这样的话这些神经元不会参与到运算,并且也不会进行梯度的反向传播。
这样做的好处就是会打断神经元的联合适宜性,使得每一个神经元都会学习到独立的、更加强大的特征。不过也有的人解释dropout之后每次都是不同的网络,所有dropout其实是暗中进行了模型集成。
此外,作者认为在测试阶段,由于这个时候我们是使用了所有的神经元,所以每一层的输出都要乘以$0.5$,因为这样这样做是对所有可能的子网进行一个平均。
C. 超参数设置
文章用的SGD优化器,动量(momentum)取$0.9$,动量衰减(weight_decay)取$0.0005,5e-4$
所有层的学习率都是相同的,并且在训练的过程中会调整。如果模型在当前学习阶段停止了学习,即错误率不在下降,那么学习率就会除以$10$。初始学习率设为$0.01$。在停止训练前学习率会减少三次。文章中使用ImageNet训练,用120万张图像训练了大概90个epoch。
此外,网络的网络参数的初始化是从一个$0$为均值,$0.01$为方差的标准正态分布中采样得到的。
我自己的经验就是,对于大型的网络,学习率一开始一定要设置的大一些,不然优化速度慢不说,优化最终达到的性能还差,可能是陷在了local minima)。
5. 实验结果
是骡子是马,拉出来溜溜
A. 主实验
主实验其实就是ImageNet 2012挑战赛,因此,主实验的报告就是AlexNet在ImageNet 2012挑战赛上的结果。
可以看到,AlexNet基本上把SIFT特征+Fisher Vectors、Spares coding这类传统方法按在地上摩擦。

B. 消融实验
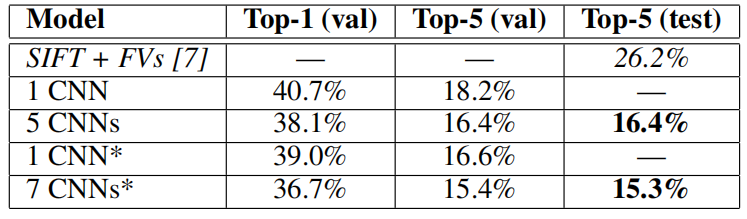
因为ILSVRC 2012的测试集不公开,因此文章除了主实验以外的性能,都是利用验证集合测试出来的。
文章的消融实验只有一个,就是研究了网络层数对性能的影响,如下表。带*的是使用了ImageNet 2011秋季的数据与训练得到的性能
最终得出的结论就是:
- 随着网络层数的增加,模型的性能会有所提升
- 预训练能够帮助模型得到更好的性能
C. 定性分析
最后,文章对模型进行了一些可视化,进行了定性分析。
卷积核定性分析
文章对两个GPU中第一层的$11\times11\times3$的卷积核进行了可视化,前三行是第一个GPU上的卷积核,后三行是第二个GPU上的性能。
可以看到,模型学习到了很多种不同频率(frequency)选择性、方向选择性(orientation-selective)的卷积核。方向选择性还能理解,但是文章为啥会说频率选择性,其实是因为卷积神经网络中的卷积核除了特征提取的理解以外,还有一种滤波器的理解。这个就涉及到图像的频域分析了。
需要注意的是,第一个GPU上的卷积核总是会学习到和颜色无关的方向信息,而第二个GPU 上的卷积核总是会学习到了和颜色相关的特征。

文章中还报告,这个现象是通用(general)的,即多次训练每次都能够观察到这个现象。
推断结果定性分析
文章接下来做的定性分析,就是选取了一些图片,让模型去推断,然后对模型的推断结果进行了定性分析。

这个图分为左右两个部分,分别表示两种不同的分析。
- 首先对于左边的图
- 左边的图像选取自
ILSVRC 2010的测试图像,因为这一年的测试集是公开了的。Ground Truth被写在了下面。如果模型的Top5预测中存在Ground Truth,那么就会用红色的柱子表示,否则用蓝色柱子表示 - 通过队对左侧的图像的分析,能够观察到:
- 模型对平移具有鲁棒性,即便是偏离图像中心的物体依然能够被网络识别出来
- 绝大多数
top5的预测label都是合理的,例如猎豹的前五个预测都是猫科动物 - 一些推断错误的图像则是由于图像本身具有很大的模糊性,例如最后两张的狗和樱桃、马达加斯加狐猴
- 左边的图像选取自
- 其次,对于右边的图
- 右侧第一列图像也是从
ILSVRC 2010测试集中获得的,因为模型对一张图像会推断得到一个概率向量。而经过softmax之前的、最后一个隐藏层输出的向量称为logits。因此文章用左侧第一列的图像的logit作为key,从ILSVRC 2010测试集中检索得到的。具体的检索方式就是,KNN选取和左侧第一列的图像的logit的欧式距离最接近的向量所对应的图片。 - 结果表明:
- 模型的确从数据中学习到了有用的特征,可以把类似的图像映射为同一类上去
- 右侧第一列图像也是从
6. 总结与讨论(Discussion)
文章的最后一部分,自然就是总结了一下文章的贡献,然后挑选了一些不太重要的问题说了一下。
Our results show that a large, deep convolutional neural network is capable of achieving record-breaking results on a highly challenging dataset using purely supervised learning. It is notable that our network’s performance degrades if a single convolutional layer is removed. For example,removing any of the middle layers results in a loss of about 2% for the top-1 performance of the network. So the depth really is important for achieving our results.
To simplify our experiments, we did not use any unsupervised pre-training even though we expect that it will help, especially if we obtain enough computational power to significantly increase the size of the network without obtaining a corresponding increase in the amount of labeled data. Thus far, our results have improved as we have made our network larger and trained it longer but we still have many orders of magnitude to go in order to match the infero-temporal pathway of the human visual system. Ultimately we would like to use very large and deep convolutional nets on video sequences where the temporal structure provides very helpful information that is missing or far less obvious in static images.
主要意思就是说:
- 没有使用任何无监督的预训练,尽管这样做绝对会提升我们的性能。尤其是现在有了更大的算力和数据集。甚至只要我们愿意等的更久一些,模型的性能都会继续有所提升
- 本文通过使用更大,更深的网络实现了很强的性能。但是如果继续引入人类视觉系统的中的时间信息的话,那么模型性能可能会有更强的提升。因此,作者最后提出来,接下来有希望的方向就是把更深的卷积网络运用到视频领域中去,因为对于视频来说,视频可以提供很多静态图像中无法提供的时间信息,未来的模型中需要对时间进行建模。


