本文是Machine Learning 2021 Spring 第十节课的笔记,本节课主要讲解了Generative Adversarial Network (GAN)。

李宏毅ML2021-Spring-10: Generative Adversarial Network (GAN)
我们前面讲了Regression、Classification这两类任务,我们接下来要进入一个新的主题,新的主题中我们关注的任务是Generation这个任务。
1. Network as Generator
在前面的课程中,我们讲的网络(模型),他们接受一个输入,然后输出一个输出。我们前面的讲解各种模型,我们的输入可以是一个包含不同feature的input(Regression任务不同的Feature),一张图片(CNN),一个向量组(Seq2Seq),而输出则可以是一个scalar(Regression),一个向量(Classification),或者是一个向量组(Seq2Seq)。

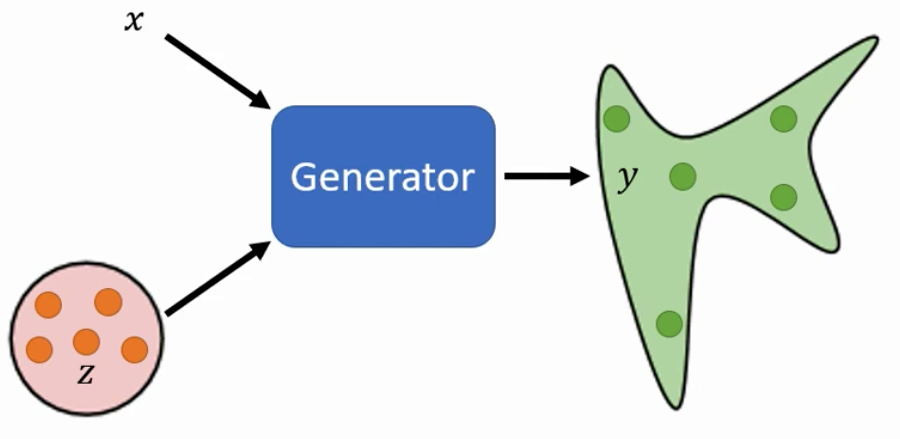
现在我们要讲Generation这件事,而Generation这件事和前面讲的网络不同,它的输入除了x以外,还会有一个random variable。
这个random variable是从某个的Distribution sample得到的,所以现在Network(Generator)是在看了$x$和$z$之后才会输出$y$。

那么我们现在就会问,模型到底要怎么样才能够同时看两个输入$x$和$z$呢?这个其实是取决于我们的网络如何设计的,例如:
- $x$和$z$是两个不同长度的向量,然后用hstack连接起来作为最终的输入
- $x$和$z$是两个长度相同的向量,然后把他们两个加起来作为最终的输入
这两种都是可以的。其实还有更多的设计的方法,都是可以。
此外,我们还有一个限制就是这个分布必须要足够的简单,简单到我们知道这个分布的解析式。例如$z$这个随机变量可以服从一个高斯分布,也可以服从一个均匀分布,乃至于是Zeta分布等等都可以。
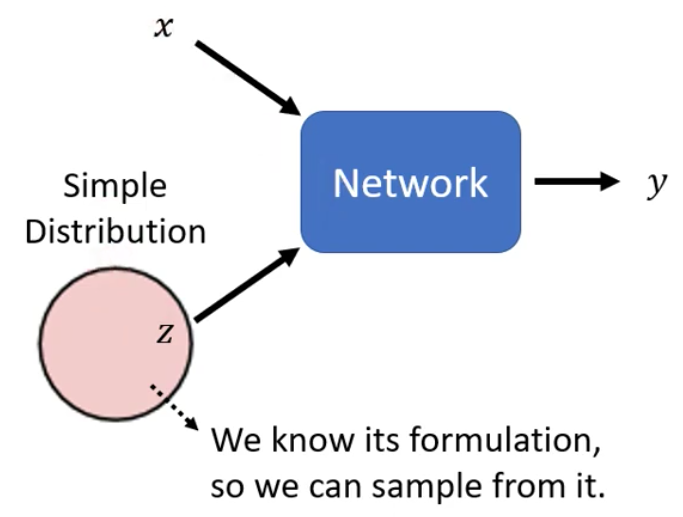
所以,现在有一个新的$x$进来,我们从这个分布中sample得到一个$z$,然后得到一个输出$y$
所以,我们现在有很多不同的输入,我们就会进行很多次sample,然后会得到很多不同的输出
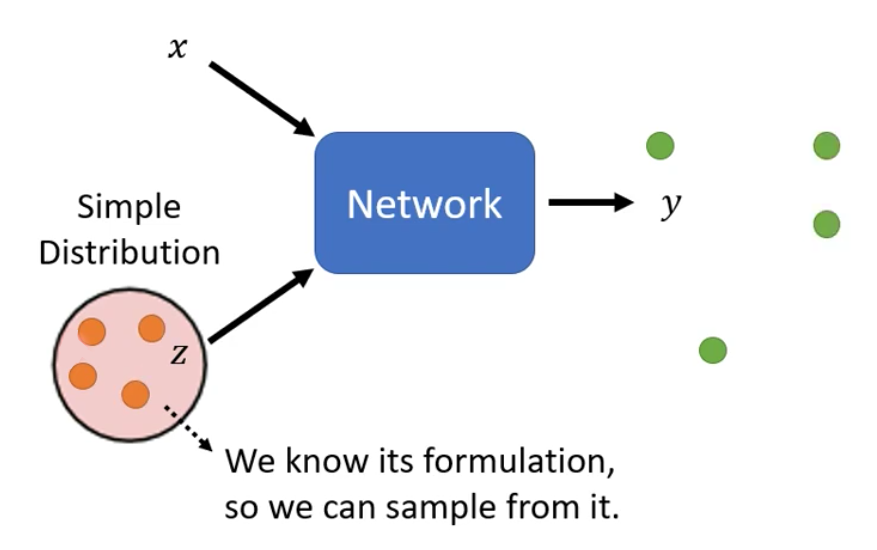
因此,我们网络的输出就已经不再是一个单一的数值了,而是一个分布。

而这种输出是一个Distribution的Network称为一个Generator。

2. Why do we need distributions as output
我们上面说道,输出是分布的网络称为Generator。那么我们就想问为什么我们需要一个网络的输出是分布呢?或者说为什么我们需要Generator?
1. Video Prediction
我们首先以Video Prediction任务为例进行讲解。Video Prediction指的是让机器看一段视频,然后让机器预测接下来会发生什么事情。
我们这里的视频用的小精灵这个游戏的视频。小精灵这个游戏就是让玩家控制的精灵尽量避免恶魔明确吃到所有的奖励,如下图

所以,我们网络的输入是过去一段时间(过去几个frame)图片,然后让网络输出未来的几个frame的图片

有人可能会问,输入图片用CNN就行了,可是该怎么样输出一个图片呢?那么我们其实可以直接让网络输出一个向量,然后把这个向量reshape得到一张图片即可。不过原始论文中的输入是分块进行的,而不是一次输入一张图片
如果我们用Supervised Learning的方法,最终得到的结果是下面这样的。

我们仔细看右上角的小精灵的话,就会发现,一开始小精灵还是黄色的,可是走着走着就成了黄色的。这个还不是最大的问题,最大的问题就是走着走着小精灵就分裂了。
那么为什么会发生这样的现象呢?这是因为现在在我们的训练的输入中,同样的小精灵,在同样的转角,有的向右走,也有的向左走。这两种训练的数据同时存在于我们的训练数据中,并且这两个事情都是真实世界中可能发生的。
而我们的网络在遇到这个转角的时候,如果输出向左的话,那么向右的Example的Loss就会很大,反过来也是一样的。因此,网络最终是在进行两面讨好,即输出同时向左向右。

可是有一个问题就是,单独输出向左转是对的,或者说是合理的,单独输出向右转也是合理的。输出同时向左也向右转却是绝对错误的。
那么这种情况下该怎么样来处理呢?我们其实让模型不要输出一个单一的值,让模型输出一个概率的分布就行了,即让模型输出小精灵未来某一帧在某个位置的概率。
因此,我们现在其实就需要让模型输出一个分布,因此我们其实就需要一个Generator来完成这个任务。

举例来说,我们现在让$z$服从一个Binary Distribution之后,针对同一个input,如果$z$ Sample得到1之后那么输出就是模型向左转,sample得到0就输出向右转。这样我们就解决了相同的过去有不同的未来这个问题。
2. Creativity
在什么样的任务下我们需要使用Generator来作为我们的模型呢?其实就是在我们的模型需要一些创造力的时候。什么是创造力呢?其实就是相同的输入有不同的输出
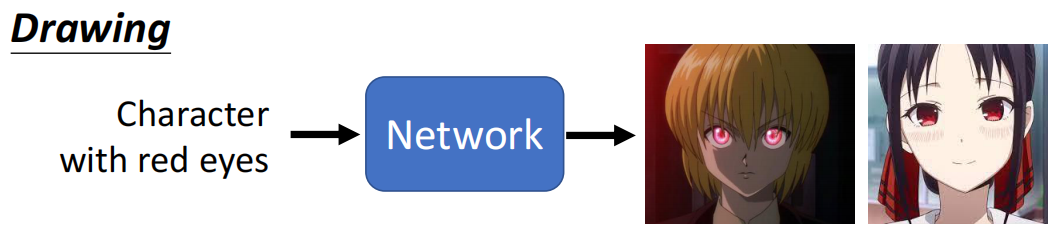
例如对于绘画任务来说,我们现在说要让网络画出来一个红眼镜的任务,那么不同人画出来的角色是不同的。有的人可能画出来酷拉皮卡,有的人可能画出来辉夜大小姐
除了绘画以外,聊天机器人也是需要一些创造力的,例如我们问辉夜是谁,那么有的人可能会说辉夜大小姐,有的人会说是大同木辉夜
因此,上面的任务都会存在相同的输入有不同的输出,因此我们的模型就需要使用Generative的Model。
此外,我们还需要理解一个问题,就是我们这里说的Creativity,指的其实就是difference。具体来说就是相同输入有不同的输出。
3. Generative Adversarial Network (GAN)
在所有的Generative的Model中,GAN就是最有名的一个。我们接下来就来讲解GAN这个模型
1. Introduction of GAN
1. How to pronounce GAN?
在正式开始讲之前,有一个问题就是GAN怎么读,Google给出的发音是干😂

2. GAN ZOO
我们首先需要说的就是GAN其实是有很多的变体的,GIthub上有一个仓库,里面收集了各种各样的GAN,因此这个仓库称为GAN ZOO,里面收集了超过500种GAN。而当有人提出了新的GAN之后,就会给GAN前面加上一个字母,所以所有的英文字母很快就用完了。
例如S这个单词,即SGAN就有六个,以至于有的文章剔除来的GAN中用了Variational Auto-Encoder GAN,所以缩写应该是AEGAN。可是因为AEGAN已经被别人用了,而且别的字母也都被用了,所以就叫做$\alpha$-GAN

2. Context of Lecture
我们接下来,结合Anime Face Generation的任务来讲Unconditional的GAN
1. Unconditional GAN
所谓的Unconditional GAN就是没有input的$x$,只有random variable $z$的GAN

我们下面假设$z$是从一个Normal Distribution中Sample得到的,而且Sample得到的$z$是一个Low Dimensional的向量,维度只有50、100(具体的维度由我们自己决定)。
2. Anime Face Generation
而输出的分布中的每一个数据点都是一张图片。那么我们就会问,该如何让模型输出一张图片呢?这个其实很简单,我们让模型输出一个高维向量即可。例如我们图片的分辨率是64*64,那么我们让模型输出一个长度3600左右的向量即可。然后我们把这个向量reshape一下,就得到了一张图片。

对于Unconditional GAN来说,我们从$z$中Sample的到不同的向量就可能会生成得到不同的动漫人物的脸

3. Why Normal Distribution
我们可能会问为什么我们要使用Normal Distribution呢?能不能用别的Distribution?答案是其实Distribution完全可以是别的Distribution,我们甚至也可以是Uniform Distribution。
因为我们的模型会想办法把一个简单的Distribution转换到一个Complex的Distribution。
虽然老师自己训练下来的体验就是不同的Distribution并没有很大的差别,不过的确是有文章在研究这个$z$服从的Distribution。
3. Discriminator
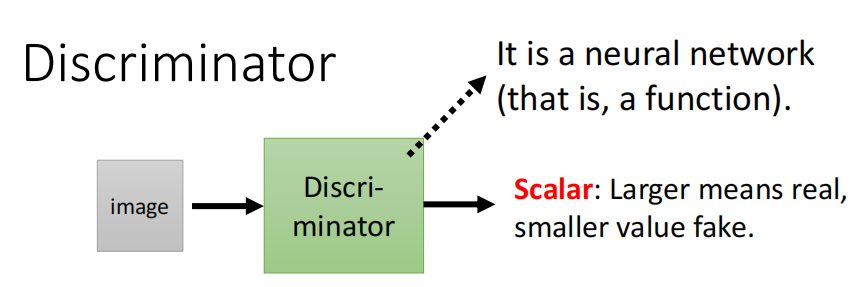
GAN中,除了Generator以外,还需要训练的一个东西就是Discriminator。
Discriminator其实说白了就是一个神经网络,或者说函数。他的作用就是输入一张图片,输出这张图片是真实的二次元头像的概率。
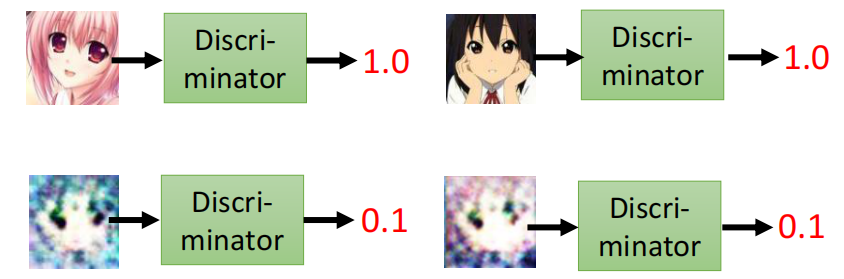
例如下面,第一行的两个头像是真实的动漫头像,所以得分会很高,而下面的两个头像比较不像是一个动漫头像,因此得分比较低。
而Discriminator这个网络的结构完全是又我们的自己决定的。我们只需要满足该网络能够分辨输入是否是真实的图像即可。而对于我们的这个任务来说,输入是一个图像,所以我们理所当然的就会想用CNN来作为我们的Discriminator。
4. Basic idea of GAN
1. Story of Butterfly
在将GAN的设计思想的时候,我们先讲一个故事。
下面这这张图片并不是一个树叶,而是一个枯叶蝶

可是我们就会想,枯叶蝶最早可能并不是像枯叶的,枯叶蝶最早也是五彩斑斓的

那为什么枯叶蝶会变成枯叶呢?其实是因为有物竞天择的压力。例如说现在神奇宝贝里的波波是专门吃彩色的蝴蝶的。那么有了波波的压力,枯叶蝶祖先中彩色的都被吃掉了,之后棕色的留下来了。
所以在波波的压力下,枯叶蝶的祖先就进化了,成为了棕色的蝴蝶
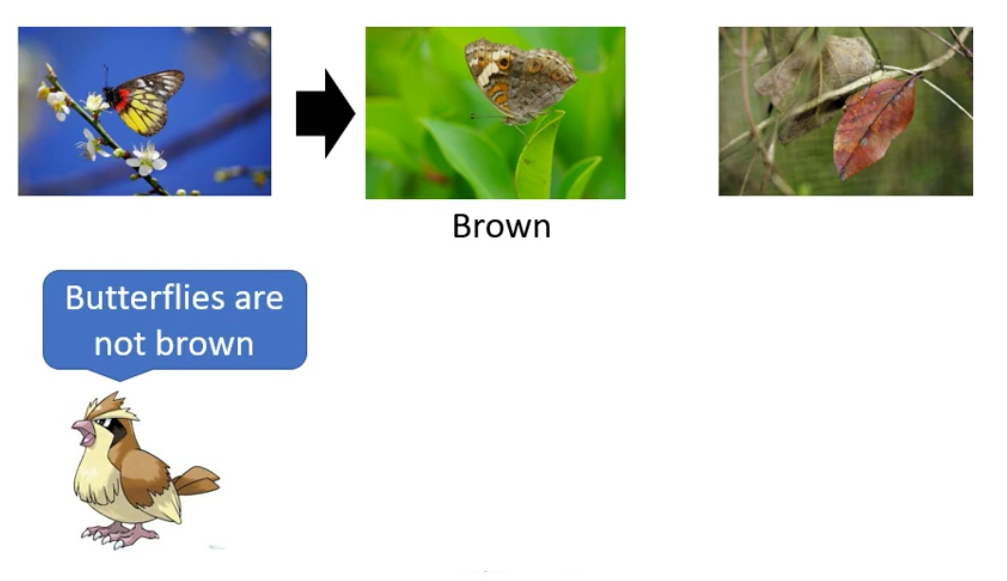
然后棕色的蝴蝶又给了波波生存压力,只有吃到蝴蝶的波波才可以生存,于是渐渐地,波波慢慢就具有了分辨棕色的蝴蝶和树叶之间区别的能力。从而逼着棕色的蝴蝶进化成了枯叶蝶

那么同样的事情再发生一次,最终比比就进化成了大比鸟
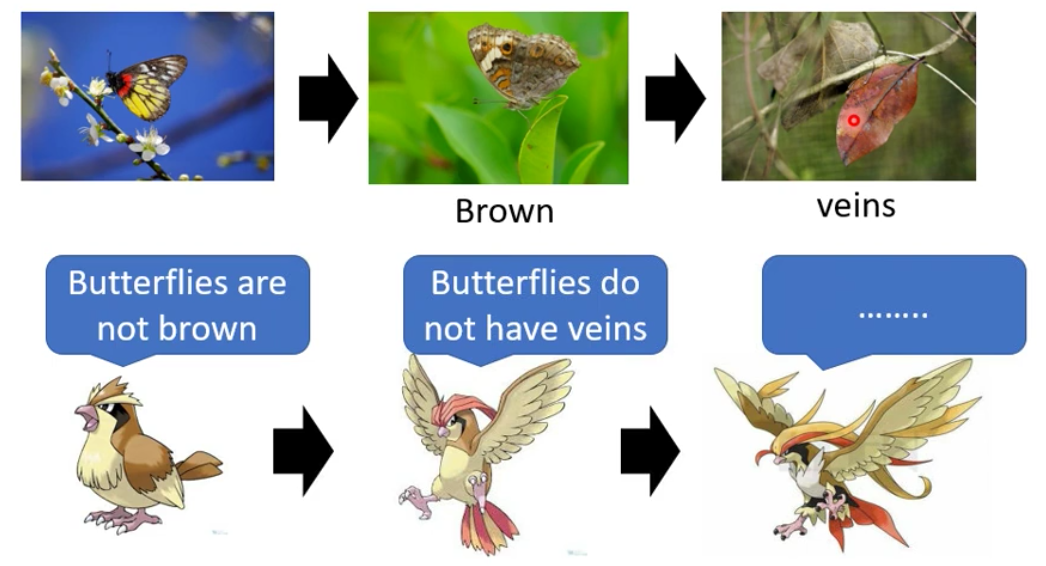
所以这个事情其实就是双方在进行对抗(Adversarial)的过程。
所以类似的事情发生在GAN中,枯叶蝶就是Generator,而大比鸟就是Discriminator
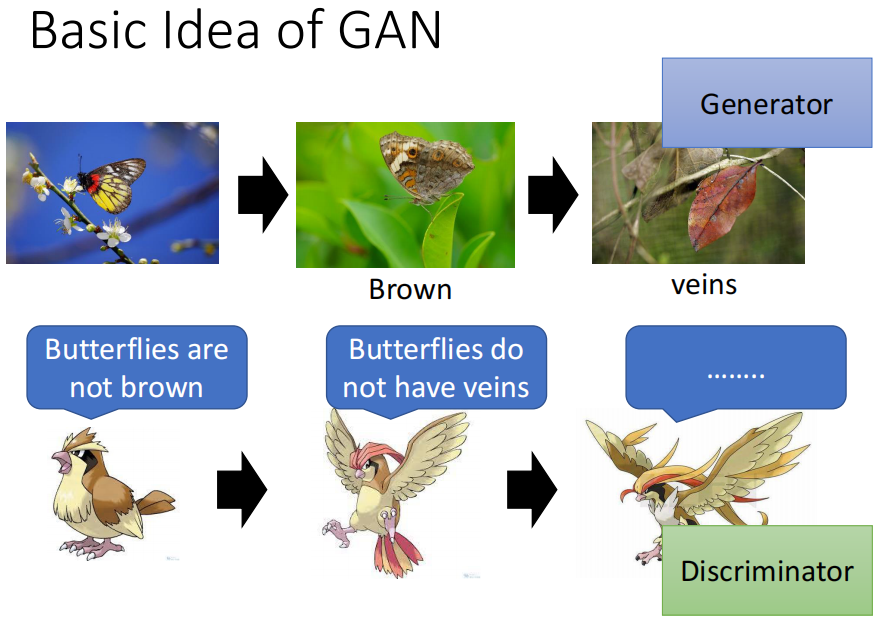
2. GAN
上面的枯叶蝶进化的故事发生在GAN的Generator和Discriminator就是下面这样的。
第一代的Generator可能产生的图片只是杂讯,而在学习了二次元头像的Discriminator给予的压力下,Generator就得到了进化,它进化的目标就是要骗过Discriminator
而第二代的Generator的输出可能会更加真实,相比第一代是有了很大的提升

同理,因为无法分辨出来第二代Generator输出,第一代的Discriminator在压力(loss)下也得到了提升,从而能够分辨出第二代Discriminator的输出。

同样的过程就会继续发生,直到Generator的输出已经非常好看了,这个过程中,Generator和Discriminator是作为对手相互对抗的,因此就有了Adverarial这个词。
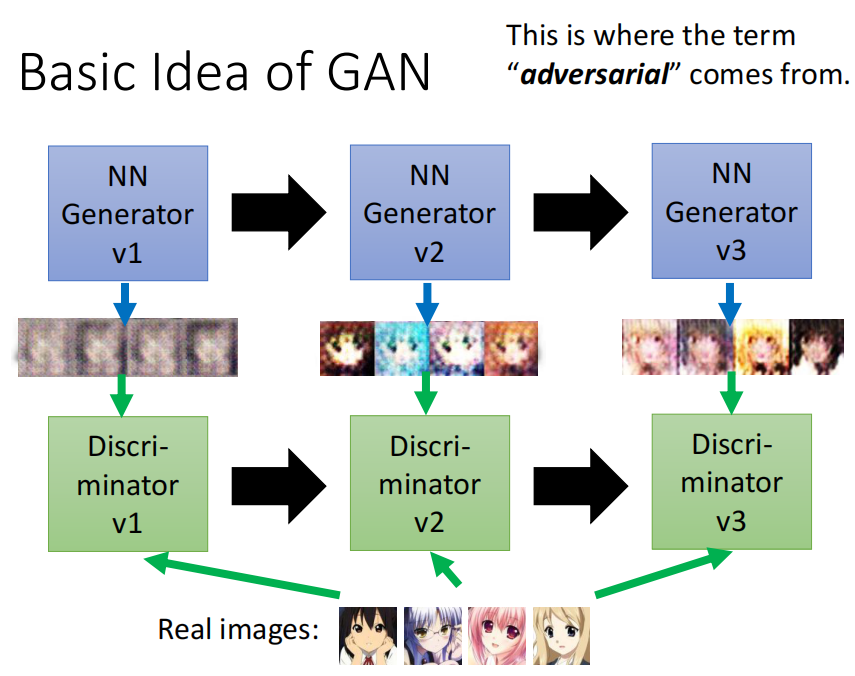
因此,Generator和Discriminator的关系就是:写作敌人,念作朋友
5. Algorithm of GAN
我们接下来再讲讲训练过程中GAN的算法
1. initialize
算法的第一步就是初始化Generator和Discriminator,这里直接随机初始化即可,也可以用Kaiming初始化。

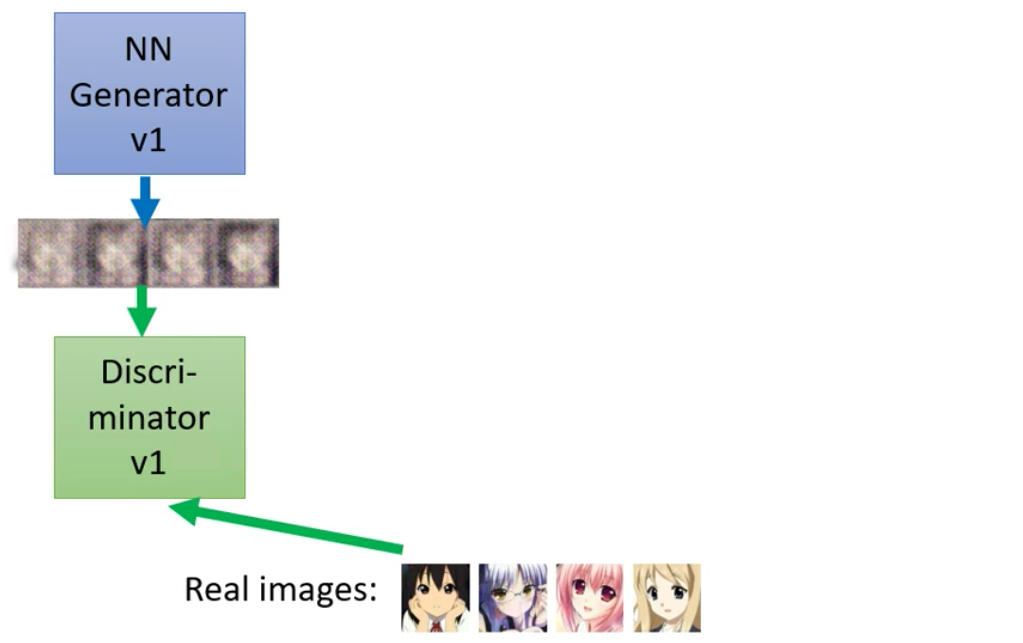
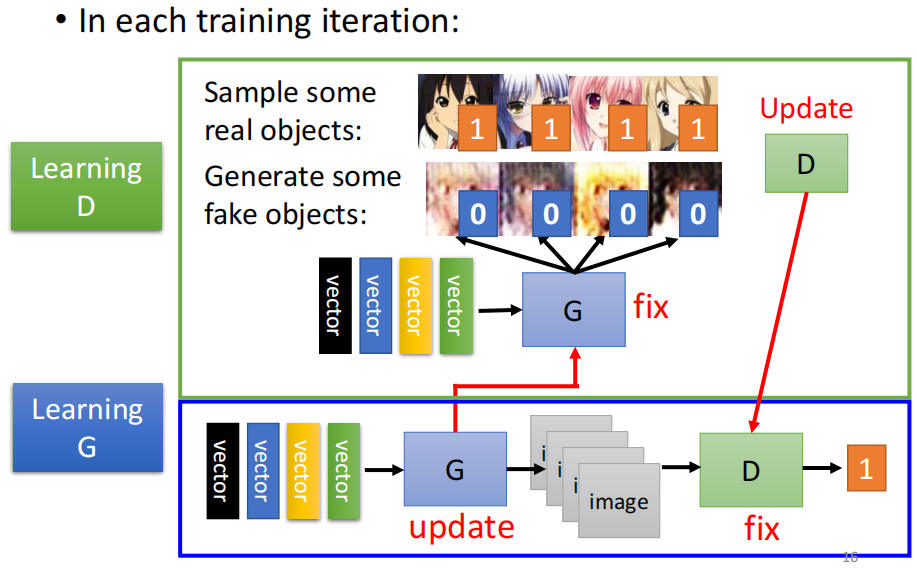
2. Train Discriminator
接下来,算法的第一步就是固定Generator然后训练Discriminator。这个时候因为Generator是随机的,所以我们从Gaussian Distribution random sample一堆vector然后丢到Generator里面去之后生成得到的图片是完全混乱的
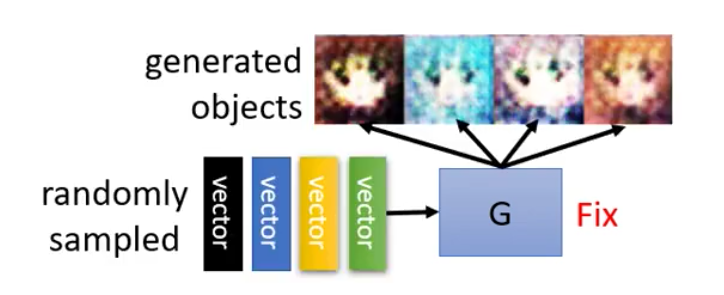
不过这里的人脸其实已经是train了几个epoch之后的结果,还是看得出来有一些人脸的样子了,已经有了两个黑黑的眼睛。一开始Update得到的结果是很混乱的,和电视没有信号得到的雪花图是一样的。
然后我们从数据集(这里因为是动漫人物人脸生成的任务,所以自然是动漫人物头像的图片作为数据集)中sample得到一些数据,然后结合Generator生成的输入交给Discriminator,让Discriminator来分辨哪些是真实的图片,哪些是Generator生成得到的图片,因此对于Discriminator来说,这个就类似与一个二分类的任务

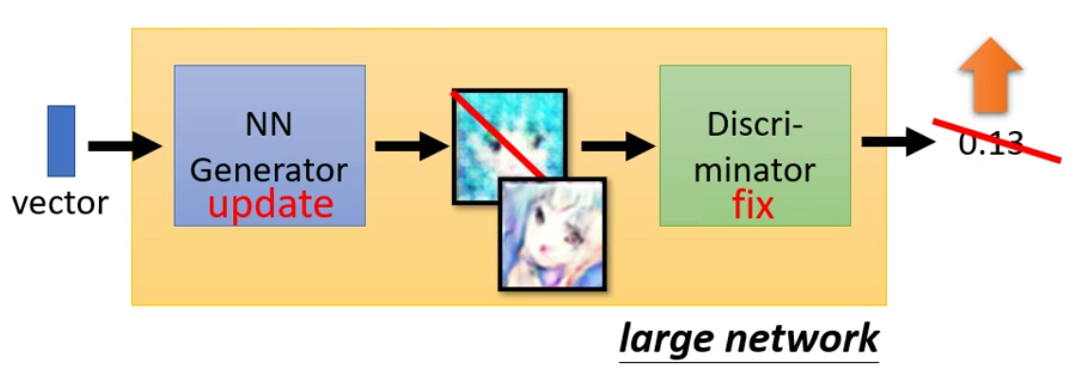
3. Train Generator
在第二步,我们训练Generator,这个时候要固定Discriminator。这个步骤比较拟人化的想法就是方Generator学着骗过Discriminator。
那么欺骗这件事是什么意思呢?因为我们上面二分类是真实的图片的label是1,Generator生成的图片label是0。因此,在训练Generator的时候,我们的目标就是让Generator生成的图片经过Discriminator之后得分越高越好

而在实际的操作中,我们是把Generator和Discriminator接起来当做一个大的网络。假如说Generator是一个5层的网络。Discriminator是一个5层的网络,那么这个大的网络就是有10层。这个大网络中中间某层的输出是非常宽的,和图片的像素的数量是相同的。
所以我们Update这个大网络的时候,Discriminator的参数是要freeze起来的,而update Generator的方法就是Gradient Descent
4. One Iteration
最后在我们不断重复上面的步骤,训练一段时间的Discriminator,然后再训练一段时间的Generator,最终期待两者在对抗的过程中都变得越来越好
6. Anime Face Generation
我们的任务是Anime Face Generation的任务,所以我们来看看GAN最后达到的效果
2017年李宏毅老师自己Train下来的结果如下:
首先是update 100次的结果,注意update 1次是指Generator和Discriminator都各自训练一遍,即一个Iteration。得到的结果如下

会发现机器逐渐开始学习到了动漫头像有人脸和头发的区别了,所以在图象周围会有一圈的深色区域和中间的白色区域。
然后是update 1000次之后的结果,会发现机器已经学习到了动漫头像会有两个人眼

Update 2000次以后,会发现人脸逐渐清晰起来,也开始有了眼镜、鼻子和嘴等特征

然后在5000个update之后,我们会发现模型给出的眼镜、鼻子和嘴越来越清晰,而且也已经知道动漫角色需要有一双水汪汪的大眼睛。

最后在10000次update之后,生成的头像已经非常清晰了,虽然经常会有一些崩坏

最后在Update到20000次之后,不少的头像在人看来都已经很不错了,只是有有一些会崩坏掉

最后李宏毅老师在50000个Update之后就停下来了

当然,在GAN的作业里我们当然可以做的比老师做的更好

因为我们的Discriminator是根据Generator的输出和数据集来进行判断的,因此如果我们的如果有更好的数据,并且模型更加强大的话,我们其实是完全有可能训练得到更好的结果的,例如StyleGan。
我们仔细观察的话,其实还会发现有的时候生成的动漫头像是有异色瞳的

7. Face Generation
当然,除了动漫头像以外,GAN当然可以用于生成人脸,例如:Progressive GAN:https://arxiv.org/abs/1710.10196
例如下面的两排人脸,哪一个排是Progressive GAN生成的?哪一排是真实的?答案是其实上下两排都是GAN生成的。

除了生成单独的人脸以外,GAN还有一个比较神奇的地方,就是可以做到人脸的转变。
我们现在知道,从Distribution中sample得到两个向量,可以通过这两个向量就可以让Generator生成得到一个人脸。
例如我们现在输入两个向量,就得到了两个人脸。

然后我们对这两个向量进行内插,得到一系列的向量,然后我们把这些向量输入到Generator之后生成一系列新的人脸,最终我们会发现,这些人脸连在一起完成了人脸的变换

除了完成从男到女以外,还可以完成向左看到向右看的过度

8. The first GAN
现在在网络上流传着一个故事,就是说GAN的发明者,Ian Goodfellow有一次在酒吧喝酒,看到两个人在吵架,然后就产生了灵感,于是回去Train了一发,一次就成功了,得到了这篇Paper。
但是那个时候所谓的成功,其实是下面这样的

但是在14年的时候,这个已经是非常震惊的效果了,李宏毅老师第一次看到就是:WOW,竟然真的可以产生图片。
但是在今天我们在看这个效果,就不会感觉非常惊艳,因为现在BigGAN、StyleGAN等很多GAN已经实现了非常惊艳的消息。
9. BigGAN
BigGAN合成的图片的效果其实已经非常惊艳了,完全能够达到以假乱真的程度。其实我们仔细看,还是可以看出来破绽的,例如左上角的狐狸是有五条腿的,而右上角的茶杯也是歪歪扭扭的。

可是,机器有的时候也会生成幻想中的生物,例如网球狗

4. Theory behind GAN
我们上面用了一堆比喻,给大家讲了GAN是如何运用的,此外我们还讲解了GAN是如何运行的。我们接下来来讲讲一些理论的部分,即GAN背后的原理。告诉大家为什么Generator和Discriminator这样的互动就可以产生人脸这样的图片。

1. Define Objective
要讲清楚GAN的原理,我们第一步先搞清楚我们的目标。
我们前面在最前面说过,Generative的Model的输入是Sample来自与一个Distribution的Variable以及一个input,其output是一个分布。我们现在讲的是Unconditional的GAN,因此输入只有Sample来自于一个Distribution(假设是Gaussian Distribution)的random variable。
而我们把真实的图片当做是高维空间中的一个点的话,真实的图片必然服从一个分布,只不过这个分布可能我们并不知道,而且无法写出来解析式,我们不妨称这个潜在的、数据真实服从的分布为$P_{data}$
而现在我们又直到模型的输出是一个分布,记为$P_G$,因此我们要做的事情其实就是让模型输出的分布和真实的数据的分布越相近越好。

我们以一维的情况来进行理解。所谓分布其实指的就是在随机变量在取某个值的概率。或者说就是变量出现在数轴上某个位置的概率。而概率则可以以频率来进行估计。所以从这个角度来理解,分布其实指的就是对于数轴上的每一个可能的取值,所有的example中,有多少个example是这个值。
所以用一维的情况来理解的话,那么就是Generator的输入是一个simple的Gaussian Distribution,经过Generator进行变换之后,每个example的位置都发生了变化,因此数轴上每个位置出现的example的数量就发生了改变,因此数据的Distribution其实就发生了改变。
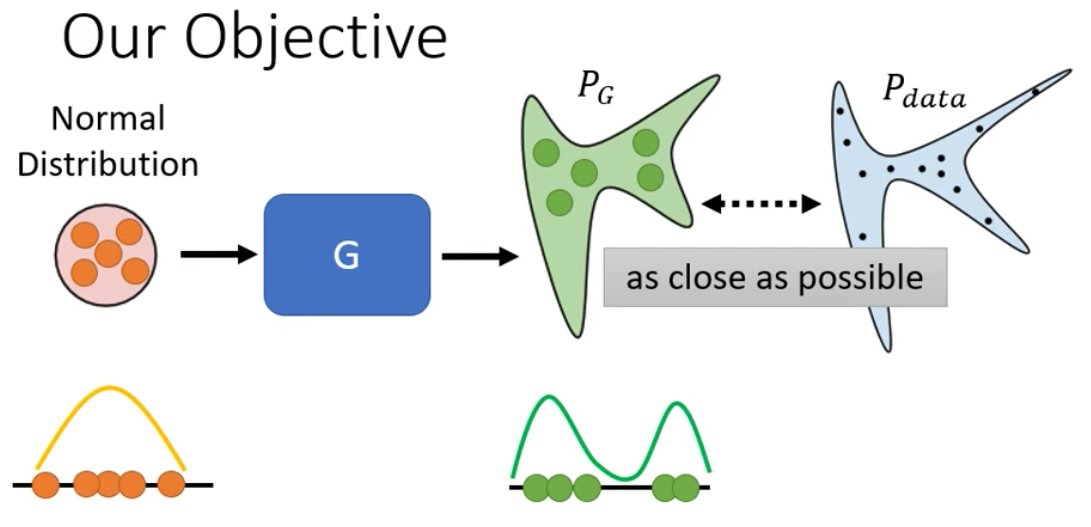
所以,我们现在的目标就是让输出的分布和真实的分布相似。

而我们描述两个分布的相似程度,使用的工具就是散度(Divergence)。而信息论中的Divergence,描述的其实是两个分布之间的距离,距离越近(Divergence越小)的分布就越相似。而当两个分布之间的距离是0的时候,就表示两个分布是equivalent的。
因此我们的目标其实就是要minimize $PG$和$P{data}$的Divergence,即找到一个Generator,这个Generator可以使得Divergence最小,故:
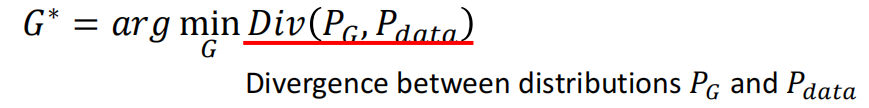
因此,我们现在的问题就是,Loss Function我们定义成描述距离的MSE和最大化似然Cross-Entropy我们都是有式子可以计算的,对于散度来来说,如果我们有了$PG$和$P{data}$的解析式的话,那么我们其实也是可以计算出来Divergence的,因为信息论里面给出来了计算Divergence的式子。
可是现在问题的关键就在于我们并不知道$PG$和$P{data}$的分布,因此如何计算$PG$和$P{data}$的Divergence就成了问题。
此外,类似于MSE和RMSE,Divergence也是有不同,例如KL-Divergence和JS-Divergence,但是不管计算哪种Divergence,我们都需要得知数据分布的解析式。
而GAN神奇的地方就在于:GAN突破了我们需要知道分布的解析式这个限制,我们只需要通过sample就可以计算这个Divergence。
2. Sampling for Distribution
我们前面说到,我们要训练GAN的话,就需要计算模型输出的分布和真实数据分布之间的散度,而散度的计算则需要我们知道数据的解析式。不论是模型输出的分布还是真实数据的分布,这个解析式我们其实都是不知道的,因此训练GAN的难点就在于这里。
而GAN告诉我们的就是,只要我们知道如何从$PG$和$P{data}$中sample得到东西出来,我们就可以计算这两个分布的Divergence。我们不需要知道这两个分布的formulation,我们只需要知道如何从这两个Distribution中进行Sample就可以计算Divergence。

所以,我们首先讲讲如何从$PG$和$P{data}$中进行sample。
而从$P{data}$中进行Sample这件事非常简单,因为$P{data}$表示真实的的动漫头像服从的分布,因此我们从网络上获得动漫头像其实就是从$P{data}$这个Distribution中Sample得到example。考虑到我们现在拥有数据集,因此,我们从$P{data}$ Sample得到example其实就是从database中抽取动漫人物的头像。
而从$P_G$指的是Generator输出的图像服从的分布,因此从$P_G$中sample得到example其实就是让Generator生成一张头像,即从Gaussian Distribution中Sample得到一个Vector,然后让Generator生成一张图片。

3. Discriminator for Divergence
上面我们已经介绍了如何从$PG$和$P{data}$中sample得到example。接下来GAN中剩下的任务就是告诉你如何在只有做Sample的情况下、我们完全不知道$PG$和$P{data}$的formulation的情况下,计算$PG$和$P{data}$的Divergence(或者说approximate Divergence)。而通过Sample来approximate Divergence就是靠Discriminator来实现的。
具体来说怎么样让Discriminator来实现approximate Divergence呢?我们现在告诉大家,我们按照前面的设置进行二分类的训练之后,Discriminator就可以用于approximate Divergence。下面给出来证明
以下部分参考原论文和李宏毅老师的课程
我们前面说过,来训练网络的过程其实就是解含参函数的最优化问题,我们现在用$D$来表示Discriminator的参数,则$D$为决策变量。设我们的优化目标(目标函数)为$V=V(D)$。因为优化目标在计算是需要Generator的输出的,而Generator的输出又和Generator的参数有关,因此我们不妨设Generator的参数为$G$,那么优化Discriminator的时候,我们的优化目标为$V=V(D,G)$。
需要注意的是,我们在上面讲的GAN的训练过程中是先训练一下Discriminator,然后再训练一个Generator。因此在训练Discriminator的时候,Generator的参数是固定不动的,所以$V(D,G)$中$G$是一个常数,因此我们是一个单变量优化问题。
我们现在给出如下的目标函数,则对该目标函数优化之后得到的网络(一套参数值对应一个网络,因此即指优化之后得到的网络)就可以衡量Generator输出的分布和真实数据的分布之间的JS Divergence。为了简单起见,下式中我们把Discriminator记为$D(\cdot)$,则目标函数如下:
经过优化(训练后)后Discriminator的参数记为
看到这里,我们可能就会晕了,为什么最大化$V(D,G)$之后得到对应的参数$D^*$之后,Discriminator就可以来衡量两个分布的Distribution呢?
我们下面就给出数学上的证明,注意上面用的是$y$表示输入是Generator的输出,这里换成$x$强调是Discriminator的输入。
首先是写出来$V(D,G)$的表达式
然后我们要maximize $V(D,G)$,实际上就是要最大化
而我们上面说过了,$P_{data}(x)$和$P_G(x)$的表达式我们写不出来,但是我们可以通过对抽样得到的样本来估计这两个概率,而抽样等价于sample得到数据集合和让Generator生成图片,所以这两个值其实是常数,因此就有
进而对$f(D)$求导,得到
从而解得
把在maximize了$V(D,G)$之后得到的$D^*$带入$V(D,G)$有
其中,KL-Divergence的表达式如下
而Jensen–Shannon divergence(JS Divergence)的表达式如下
其中
因此
所以,我们现在对Discriminator进行优化之后,得到的网络$f_{D^*}(x)$就可以用于衡量Generator的输出的分布和真实的分布之间的差距。
此时我们把从$PG$和$P{data}$中的所有图像让Discriminator计算之后得到输出的值,然后加起来求平均得到的就是JS Divergence。
而优化Discriminator则就是用我们从$P_{data}$和$P_G$中sample得到的example进行Gradient Descent即可。所以我们说,GAN通过Discriminator提供了一种不需要知道Distribution长什么样子,只需要直到如何Sample就可以来估计两个分布之间的Divergence的方法。
之所以说是approximate,是因为我们在实际中得到的example都只是有限个离散的值,而上面在推倒的时候第一步是求期望。因为我们的图像是一个高维的数据,每一个维度都可以是连续的值,因此我们example得到的只是有限的值,所以我们计算得到的Divergence只是approximate的结果。
总之在训练好了Discriminator之后,我们其实就得到一种可以approximate JS-Divergence的手段。此时,我们只需要让Generator实现minimize JS-Divergence即可(这点下面会详细讲),即
以上其实就是在Ian Goodfellow原始的GAN中的论文给出的推导。
4. Rethinking V(D,G)
我们接下来从另外另外一个角度来理解Discriminator的optimization object $V(D,G)$
原始的式子为
而期望在连续的时候就是上面的积分,而不连续的时候就是下面的式子
这个式子就是Cross-Entropy的式子,因此我们惊奇的发现,让输入和输出的分相近,其实就等价于让Discriminator进行Binary的Classification。
李宏毅老师上课的时候自己也说,它猜想Discriminator的这个Loss Function一开始可能真的就是从Binary的Classification来的,只不过在推导的过程中发现让binary Classification的objective function最大的值和JS Divergence是有数值关系的,从而完成了从分布到分类的这一重要的过度。

因此,我们前面说不知道怎么计算Generator output的Distribution和real Distribution之间的Divergence,没关系,train Discriminator,训练完了之后看一下他的objective Function的值有多大,这个值就和Divergence有关。
5. Direct Understanding between Divergence and Classification
我们接下来来直观的理解一下,Divergence和Classification之间的关系。
如果是$PG$和$P{data}$很像,那么其实我们现在从这两个Distribution中sample得到的example就会混在一起。这个时候,对于作为Binary Classifier的Discriminator来说,这两种数据是混合在一起的,因此就很难把他们分开,所以cross-entropy的结果就会比较大,而$\max_D V(D,G)$是负cross-entropy,因此$\max_D V(D,G)$就很小。
反之,如果两个很不像,那么Divergence就很大,进而$\max_D V(D,G)$就会很大

6. Replace Divergence
所以说,我们原本的目标是找一个Generator,他可以minimize $PG$和$P{data}$之间的Divergence

可是我们现在卡在了不知道怎么样算这个Divergence。
我们接下来又发现,我们可以训练一个Discriminator,训练完以后,这个Objective Function的最大值就是和Divergence有关的。

因此,我们其实就可以把Divergence替换成Discriminator的Objective Function。

我们乍看之下就会觉得
这个式子有些复杂,他有一个Maximum,又有一个Minimum。
其实对于Generator来说,我们现在就是要找一个Generator来Minimize后面红框里的东西。而红框里的东西又是另外一个Optimization Problem,它是在给定Generator的情况下去找一个Discriminator,它可以让$V$这个Objective Function越大越好。
因此,我们上面讲的两个的互动,其实就是在求解
而为什么两者的互动就是在求解上面的Optimization Problem,参考GAN的原始论文

7. Why not other Divergence?
我们前面说过,对于Discriminator训练的时候使用Cross-Entropy进行二分类之后得到的Discriminator可以来approximate JS Divergence。其实我们在训练Discriminator的时候使用不同的目标函数得到就是不同的Divergence。
那我们就会问为什么一定要用JS Divergence?能不能用别的Divergence,例如KL Divergence、Reverse KL Divergence?能不能直接用JS Divergence而不用含JS Divergence的式子呢?
答案其实是可以的,我们只需要对Discriminator的Objective Function进行修改就可以实现approximate各种Divergence。
而具体如何进行修改,在一篇f-GAN的paper里给出了详细的证明。

在这之前,还有人说GAN之所以非常的难Train,就是因为原始论文里用的不是JS Divergence,而是JS Divergence相关的Discriminator,因此难Train。
但是f-GAN的文章里最终说明了,不管你用哪种Divergence,其实都是很难Train
所以对于GAN,就有一句玩笑,No pain, No GAN

5. Impoving GAN: WGAN
在2014年的Ian Fellow完成了GAN这个非常惊艳的框架之后,大家在实际训练的时候发现,GAN其实非常难train,而原因其实就出在了我们用二分类训练Discriminator得到的Divergence是JS Divergence。JS Divergence用来训练其实是有问题的,因此针对JS Divergence的问题,WGAN这篇文章就对其进行了修改,使用了新的Divergence。
而也正是因为WGAN,才使得GAN的训练变得相对简单,因此我们下面就来讲讲这个对GAN进行了重大改进,以至于不得不对其进行讲解。
1. Why is JS Divergence bad?
我们下面从两个角度来讲解为什么JS Divergence是不好的,第一个是从流型学习的角度,另外一个是从采样的角度。
1. From Manifold Learning
在从流型学习的角度进行讲解之前,我们先简单的介绍一下什么是流型学习
流型学习
流形学习(manifold learning)是机器学习、模式识别中的一种方法,在维数约简(降低纬度)方面具有广泛的应用。它的主要思想是将高维的数据映射到低维,使该低维的数据能够反映原高维数据的某些本质结构特征。流形学习的前提是有一种假设,即某些高维数据,实际是一种低维的流形结构嵌入在高维空间中。流形学习的目的是将其映射回低维空间中,揭示其本质。
如何理解流行学习的的假设呢?我们下面举一个图片的例子。
假设现在图片是256*256大小,那么一个图片就可以用一个65536维度的向量来描述。而在这个65536维度的空间中,并不是每一个点都代表一张人类可以理解的图片。
在这个空间中,实际上只有非常非常小的一部分的区域能够表示图片。因此流行学习中假设存在一个空间,这个空间中的每一个点都是一张图片,而65536维空间中的点,就是这个空间中的点通过某种方式映射得到的。
流形是指的是连在一起的区域,数学上,它指的是一组点,且每个点都有其邻域。给定任意一个点,其流形局部看起来像是欧几里得空间。换言之,它在局部空间有欧式空间的性质,能用欧式空间来进行距离计算。因此,很容易地在局部建立降维映射关系,然后再设法将局部关系推广到全局,进而进行可视化展示。为什么说图片是一个低维度的流型结构呢?首先低维很好理解,因为假设的图像空间的维度比较低,而流型结构则是因为在维度空间中,把图片中某个像素修改,比如r通道的强度增减10,依旧是一张图片,如果认为每一个像素值都是连续的话,那么其实在某个图片代表的点周围都是连续的。所以图片就是一个流型结构。

因此从流行学习的角度来说,在高维空间中的数据都是低维度的流型。
为了方便讲解,我们现在假设高维空间就是二维,而表示数据的低维空间就是一条线。那么表示生成数据的和真实数据的线其实很有可能重叠的部分很小,即$P{data}$和$P_G$的重叠部分很小。尽管表示$P_G$的线是随着Generator的改变而变的,但是绝大部分时候,$P_G$和$P{data}$表示的线重叠部分都很小,以至于可以忽略。

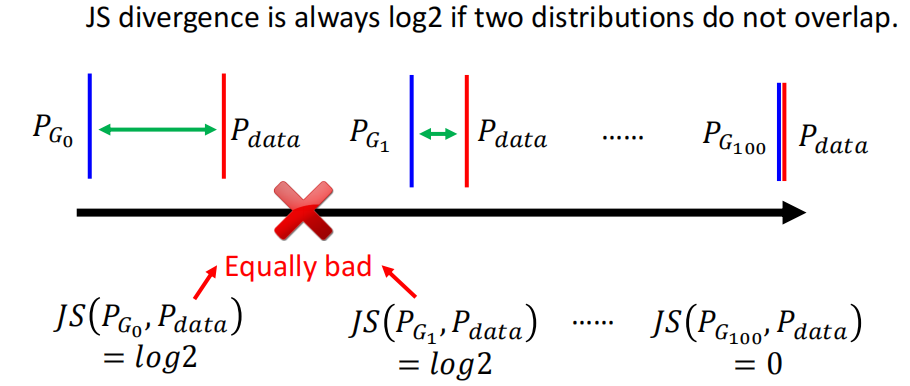
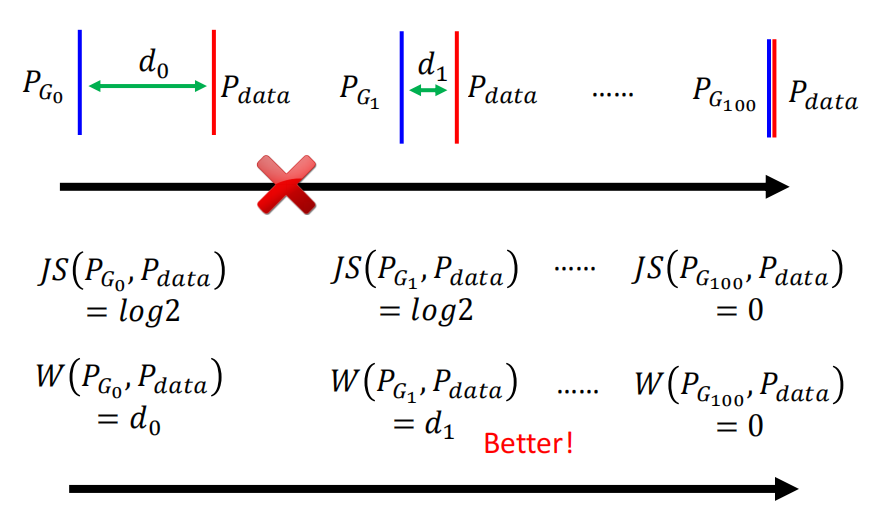
而JS Divergence计算的是两个分布的重叠程度。所以,如果用JS Divergence来计算Generator输出的分布和真实的分布的差别的话,那么在绝大多数时候,JS Divergence计算得到的值都近似$\log 2$(当两个分布完全不重合时候,JS Divergence计算得到的值为$\log 2$)。
那么这个时候就有一个问题了,只有在极少数$PG$和$P{data}$已经有相当一部分的重叠的时候,JS Divergence计算得到的值才是介于$\log 2$和0之间的值,此时才可以有效的来更新。
可是正如下图所示的,我们人类直观的理解,第二个分布显然比第一个好,但是JS Divergence却认为第二个分布是和第一个分布一样坏的,因为两者都没有重叠。然而在我们理想的情况是,在训练中输出的分布和真实的分布之间的距离是慢慢减小的,直到输出的分布和真实的分布重合。
因此,用重叠来衡量输出的分布的好坏其实是不如距离的,因为同样是不重叠的分布之间也是有好坏之分的。
2. From Sampling
我们上面讲的从流型的角度来说因为分布重叠部分很小,所以JS Divergence并不是最好的。可是这个说法是建立在流行学习中存在一个低维度的数据空间的假设上的。如果你不相信这个假设的话,我们从另外一个角度来讲解为什么JS Divergence不是最好的。
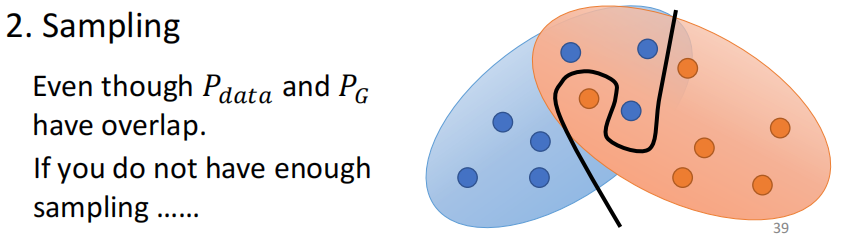
我们说真实数据的分布和生成数据的分布我们其实是不知道的,因此我们只能通过sample来估计这两个分布,因此用Discriminator来估算JS Divergence的时候也是通过这些数据来实现的。
因此现在假设$PG$和$P{data}$之间存在比较大的Overlap,可是如果我们现在sample的数量不够多,sample的不够密,对于Discriminator来说,重叠也是很小的,或者说重叠近似于0.
因此使用重叠来衡量好坏其实是有问题的。
而sample导致的问题在实践中是非常直观、非常常见的。因为通常来说sample到几万张图片才会有效果。而训练时候为了节省图片一般都是sample几千张。
sample几千张的话就会导致上面说的问题。更进一步,如果两个分布重叠的非常非常小的话,那么对于Binary Classifier的Discriminator来说,其分辨的accuracy轻易就可以达到100%。
还会造成的问题就是非常不易于训练
因此如果你自己在实践Train一个GAN的话,那么每一次Train完Discriminator之后,accuracy基本都是100%。所以我们原先假设,在Generator和Discriminator两者博弈的过程中,Generator的表现越来越好,反映在图片上就是生成的图片越来越逼真,因此Discriminator就越来越难分辨出来,所以理想的情况就是Discriminator的accuracy越来越低,loss越来越大,这样的话我们就可以知道生成的结果越来越好。
可是现在每次train完Discriminator的accuracy都是100%,所以这个时候看Discriminator的Accuracy就没有用了,不会给我们提供任何的信息。
所以我们在train的时候,就真的很像黑魔法,因为每一个epoch之后都要生成图片来看一下,然后就要一边吃饭一边看生成的图片,如果发现结果坏掉了,然后就卡掉重做。
综上,使用GAN原始论文中提出的JS Divergence其实并不是一个很好的选择,WGAN中就对其进行了弥补。
2. Wasserstein Distance
1. Idea of Wasserstein Distance
我们上面说道,使用重叠来作为衡量不好。而由于训练的过程就是输出的分布逐渐靠近真实的分布的过程,因此使用分布之间的距离(Distance)来作为衡量的好坏才是更好的选择。所以就使用Wasserstein来计算两个分布之间的距离。
Wasserstein Distance的想法是这样的:
- 假设现在有两个分布$P$和$Q$
- 他计算的方法就是想象现在有一台推土机,$P$是要推得土,而$Q$是土堆的目的地。
- 推土机把$P$移动到$Q$所需要的平均距离就是Wasserstein Distance。
因为在讲解的时候我们用的推土机(Earth Mover)来讲的,所以Wasserstein Distance又称为Earth Mover Distance

2. How to calculate Wasserstein Distance
Wasserstein Distance指的就是把一个Distribution变形成为另外一个Distribution需要移动的距离,因此不同的移动的方式,需要的距离不同,因此其实有“多个Wasserstein Distance“”。
因此,Wasserstein Distance的定义就是需要的距离最小的移动方案的移动距离
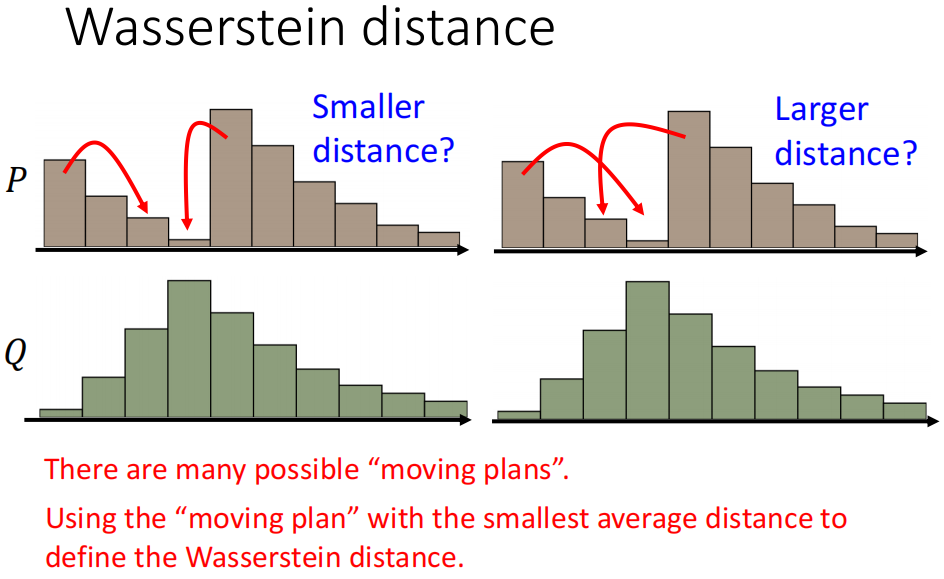
因此,如果我们现在用Wasserstein Distance来衡量Generator输出的分布和真实数据的分布之间的距离的话,就会好很多
Wasserstein Distance
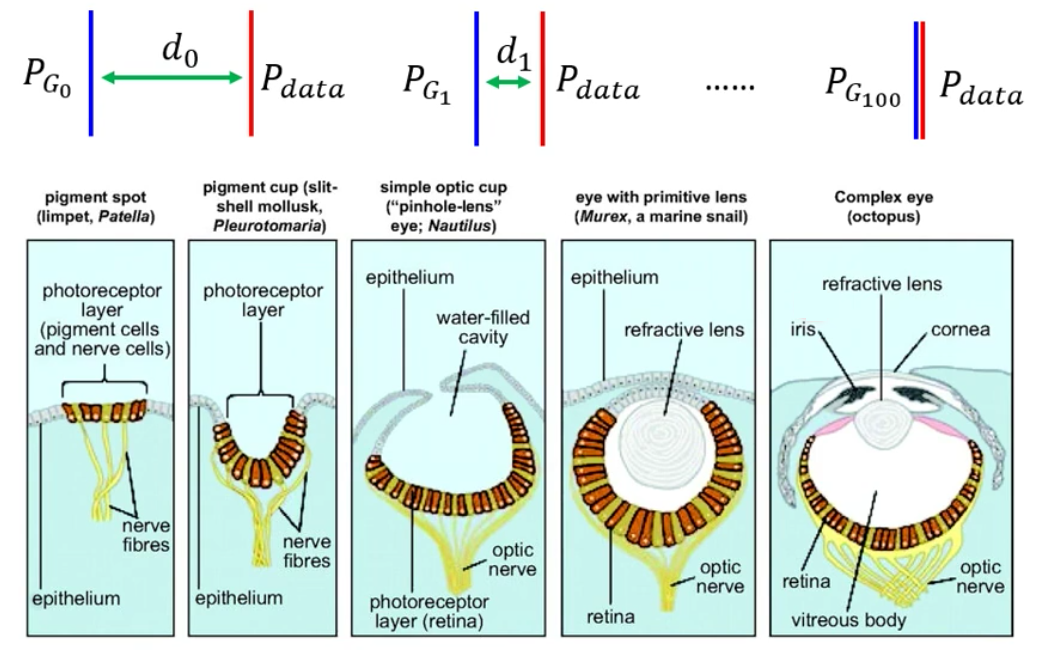
Wasserstein Distance让李宏毅老师想到了一个生物学演化的例子,就是眼睛的形成
右边是人类的眼睛,具有非常精巧的结构,而左边则是非常原始的眼睛,只有一些感光细胞。但是,这些简单的眼睛是如何演化成为右边的复杂的眼睛呢?针对于人类来说其实非常难以想象,而且一步直接从感光细胞进化到眼睛想也知道不可能
那么其实,在天择的压力下,眼睛是逐渐的在进化的。例如这些感光细胞会逐渐凹陷下去,从而可以接受各个方向的光。然后开始被包围起来,可以形成保护与小孔成像。然后有了液体,可以调节焦距。最后就形成了现在的眼睛。而每一小步都会让一个生命存活的概率变高,因此这样的改变是必要的。
而同样的事情对于WGAN也是一样的,使用Wasserstein Distance的时候,输出的分布和真实的分布之间的距离越来越近,所以就类似于进化的过程,眼睛(输出的分布)在不断的向人类现在的眼睛(真实的分布)进化(靠近)。
可是使用JS Divergence的重叠的话,那么其实就是要求眼睛(输出的分布)一步进化(重叠)到人类现在的眼睛(真实的分布),因为只有一步直接从感光细胞到眼睛,JS Divergence才会有不同。
而在进化的过程中,Wasserstein Distance是在不断变化的,而Wasserstein Distance有变化,就可以用Gradient Descent来进行训练。
3. WGAN
当我们修改了Discriminator的Objective Function以至于最终Discriminator的approximate的Wasserstein Distance之后的GAN就称为WGAN。
如果像上面一样要进行数学上的推导的话,那么我们首先需要知道如何计算两个我们已知解析式的分布的Wasserstein Distance。这个计算本身就比较复杂。
然后在此基础上,我们还需要寻找一个合适的Objective Function,使得训练之后Discriminator可以估计Wasserstein Distance。
这个过程我们就直接略掉了,如果想要学习的话就去看一下WGAN的论文。最终,训练Discriminator的目标函数如下:
而上面这个式子的含义就是,如果现在$x$是真实的数据,那么在经过Discriminator之后的输出越大越好,而如果是生成的数据,那么经过Discriminator之后的输出越小越好。
但是论文中在进行推导的时候有一个限制就是Discriminator所代表的函数必须是一个$1-Lipschitz$的函数。
$k-Lipschitz$函数
对于在实数集的子集的函数$f:D\subseteq R\rightarrow R$,若存在常数$K$,使得$|f(a)-f(b)|\leq K|a-b|, a,b\in D$,则称$f$符合利普希茨条件,对于$f$最小的常数$K$称为$f$的利普希茨常数。
利普希茨连续(Lipschitz continuity)以德国数学家鲁道夫·利普希茨命名,是一个比通常连续更强的光滑性条件。利普希茨连续函数限制了函数改变的速度,符合利普希茨条件的函数的斜率,必小于一个称为利普希茨常数的实数(该常数依函数而定)。
因此WGAN中,要求Discriminator表示的函数$D(\cdot)$必须满足

4. How to fulfill 1-Lipschitz?
单纯的以上面的目标函数来训练网络是简单的,但是难点就在于训练的时候如何保证Discriminator表示的网络是1-Lipschitz的。
在WGAN的原始论文中,文中自己说的是使用了rough的处理方法,即clipping。而clipping指的是在train网络的时候,如果发现网络的参数超过了一个范围之后,就把这个参数限制到这个范围内,即
然而这个方法并不一定会让Discriminator变成一个1-Lipschitz的function,但是相比原来的GAN已经非常平滑了,以至于可以train出不错的效果。

因此就会别的新的文章来研究如何让Discriminator成为一个1-Lipschitz的function,例如在Impoved WGAN中,提出了Gradient Panelty的方法,具体方法是什么则参考其论文:https://arxiv.org/pdf/1704.00028.pdf

最后,今天最常用的是Spectrum Normalization,因为这篇文章中的方法真的方WGAN中的Discriminator成为了1-Lipschitz函数。这篇论文中用Spectrum Normalization训练的网络简写为SNGAN

3. Train GAN is still hard
我们前面讲的WGAN只是弥补了Train GAN过程中的一个问题。但其实除了这个问题,Train GAN的过程中还是有很多的问题。例如Generator和Discriminator对抗的问题
因为两者是在对抗的过程中互相从对方身上学习,因此两者中的任意一个出了问题,就会导致另外一个的训练失败。例如现在Discriminator训练失败无法分辨出来图片,那么Generator就没有办法来提升自己
同理,如果Generator无法骗过Discriminator,Discriminator也就无法进步
因此,在训练的时候必须要保证两者棋逢对手,才可以训练出来

可是我们前面已经训练了不少的网络了,而这些经验告诉我们,并不是每一次训练都是成功的,更何况现在train GAN是要训练两个GAN。
6. Tips for training GAN
除了Wasserstein Distance以外,还有更多的Train GAN的技巧

这些Tips并不是对每一个任务都是有技巧的,因此他们的使用见仁见智
7. Problem of training GAN
我们下面讲讲GAN训练的过程中常见的一些问题。
1. Mode Collapse: Diversity
所谓的Mode Collapse指的是,我们预期的GAN输出的分布和真实的分布一样,可是在有的时候,训练之后GAN的输出的分布坍缩在了真实数据分布中的某个点。这样的结果就是GAN输出的图片的确是我们希望的输出,可是却缺乏了多样性,生成的图片都是同一张图片。
我们画示意图来说,就是下面这样的,输出的分布都围绕在某个点附近。例如我们看到崩坏的人脸老是出现,而且同样的脸,发色还不一样

为什么会有Mode Collapse这个问题发生?其实这个比较好理解,因为在某个蓝色点周围的这些点就是Discriminator的盲点。这个点周围的点都是Discriminator无法分辨出来的,因此Generator在学会了这个点、发现了这个现象之后,就会硬打一发,导致模型现在的输出全部集中在这个点附近,从而导致了Mode Collapse问题。
如何解决Mode Collapse这个问题呢?李宏毅老师认为,今天其实没有一个非常好的解答。例如Google的BigGAN,即便是强如Google,在train到之后也是Model Collapse。
那BigGAN是如何解决这个问题的呢?很简单,就是每一次update前保存一下checkpoint,然后train到Mode Collapse之后,把前面的参数拿出来用就行了。
2. Mode Dropping: Diversity
Mode Collapse这个问题比较好发现,因为train到最后我们就会发现所有的图片都是一样了。而Mode Dropping这个问题更加隐蔽一些。
Mode Dropping指的是,我们预期的GAN输出的分布和真实的分布一样,可是在有的时候,训练之后GAN的输出的分布只是真实数据分布中的一部分,即抛弃掉了真实分布的一部分。这样的结果就是GAN输出的图片的确是我们希望的输出,可是却缺乏了多样性,生成的图片都是同一类的,或者说缺乏某一类图片。
距离来说,对于人脸,人脸包括白人的、黑人的、黄种人的等等各类人种的脸

8. GAN for Sequence Generation
Train GAN最难的呢,其实是让GAN来生成一段文字。具体原因就是由于Classification的不可导问题。但是经过科研工作者的努力,这个问题最终还是被解决了。下面就来讲讲如何用GAN来进行Sequence Generation
1. Framework of Sequence Generation
我们首先讲解一下GAN是如何用在Sequence Generation任务上的。
首先GAN中的Generation是用于产生我们需要的数据的,因此Sequence GAN中的Generation就是用于生成文字的。而我们在前面已经将结果了可以用于生成文本的Seq2Seq的模型,因此我们就可以直接用Seq2Seq模型来作为我们的Generator。
Seq2Seq中的Encoder用于接受一个Sample自Gaussian Distribution的input vector,然后Decoder decode出一段文字,这个就是Generator。注意,下图中我们没有画出来Encoder。

然后GAN中的Discriminator是用于判断这个文本到底是机器产生的,还是真实存在的文本。因此我们就把Generator产生的文本再丢到Discriminator中进行辨别即可。
因此,我们一个完整的Sequence Generator GAN的Framework如下图所示,我们的目标就是让Generator生成的本文在经过Discriminator后的分数越大越好
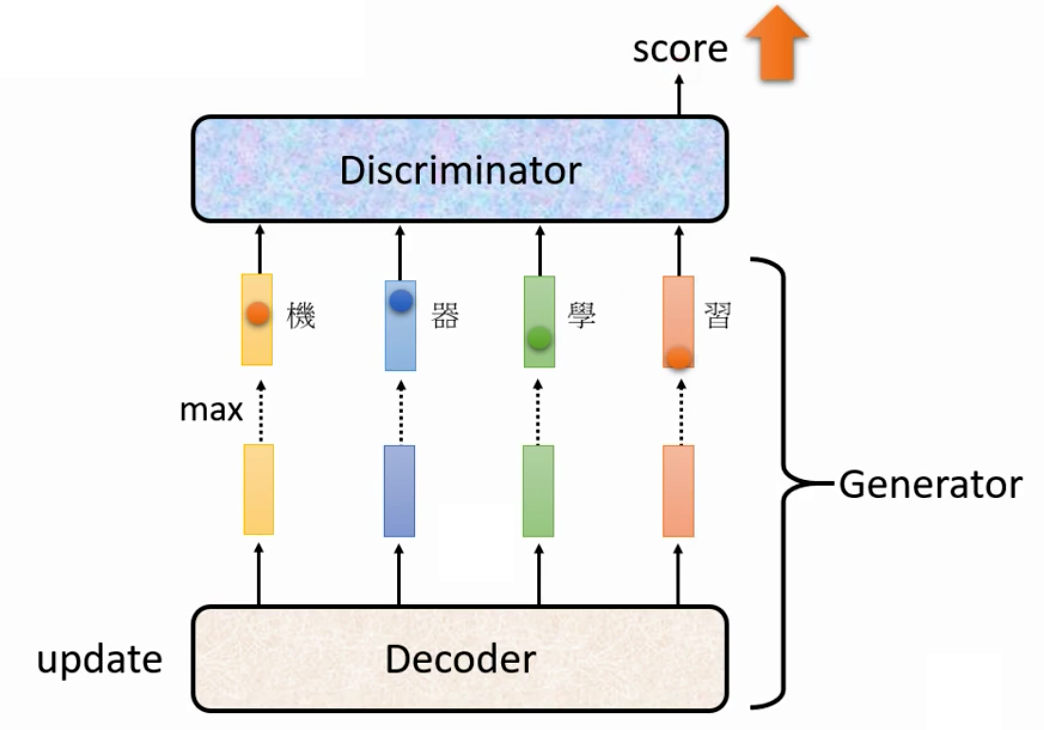
2. Non-differentiable
我们乍一看,认为上面的Framework和一个GAN没有任何的区别,但其实上面的这个Framework是无法训练的,因为上面的式子是不可导的。
而导致不可导的原因,就是我们在得到输出文本的时候进行的argmax操作,这一步是不可导的。举例来说,我们现在给Decoder进行一个微小的扰动$\Delta$,然后Decoder输出的Sequence就会有一个微小的扰动$\Delta$。
可是因为这个扰动很小,因此我们在取argmax之后输出的结果并没有改变。因此,Discriminator在反向传播计算梯度的时候,上游的梯度为0,因此下游的Generator就Train不动。

梯度为0导致无法训练Generator只是一个问题,更重要的问题是argmax操作是不可导的。
为什么max可导而argmax不可导?
对于max函数,我们其实可以写出其表达式,以二维的输入为例,
那么这个式子只有在0处不可导,而考虑到一般的情况下,并不是所有的参数都是相等的,因此在一般情况下max是可以求导的。
下面考虑多维情况下的max pooling操作。我们以一维的max pooling为例
那么这个从长度为4的向量$\vec x$到长度为2的向量$\vec y$的转换,可以用一个矩阵来表示
即
因此现在输出对输入求导的话,
因此,max pooling是可以求导的。
而对于下面的例子,argmax的操作则是
可是即便是同样的数字,排列不同的时候,输出也不同
因此argmax操作,它的不可导性质在于,它的输出不能写作输入的一个表达式,从上面的例子就可以看出来,计算argmax输出的变换矩阵来源于输入组织方式而不是输入的任何元素,因此argmax的输出对于的任何元素都不存在偏导数。对于argmax操作来说,可以使用gumbel-softmax重参数化来替代,知乎上有很多相关文章,不再赘述。
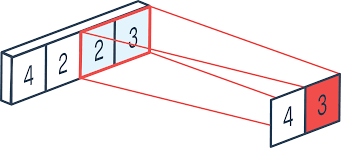
因此即便是上游的导数不为0了,梯度传到这里来也是无法计算的,因为计算图在这里被argmax截断了。
3. Atom Bomb
我们上周说过,只要是无法训练的问题我们就可以当做一个RL问题来求解,因此,对于不可导的Argmax,我们其实也可以用RL来硬train一发
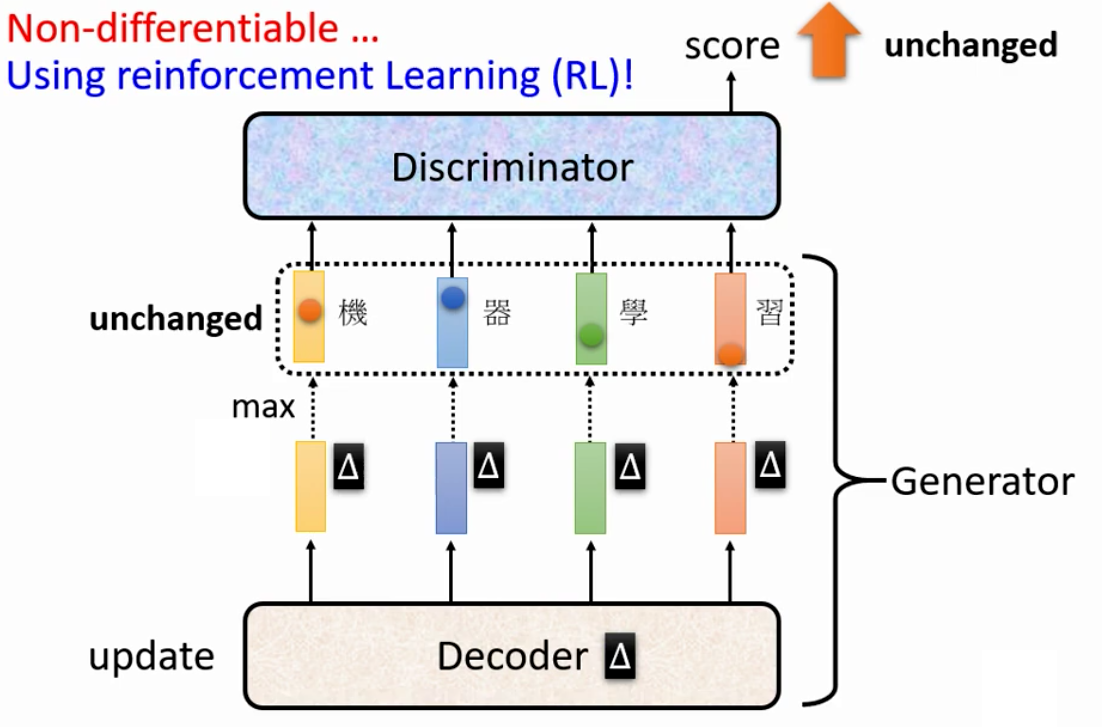
可是我们前面就说过,RL本身就很难train,GAN也难train。所以两者加起来再train就炸了

因此,在过去的很长一段时间中,没有一个人成功的用RL train出来Sequence Generation GAN
4. Sequence Generation GAN
上面说道,用RL来从头train一个Sequence Generation GAN很难,因此不少方法使用的都是finetune其他任务上得到的GAN到Sequence Generation Task中。

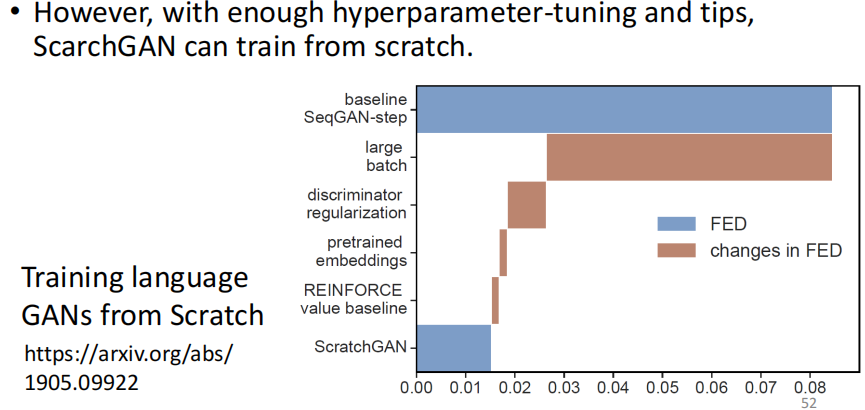
直到这篇文章:Training language GANs from Scratch,它告诉我们说我们可以从头训练一个Sequence Generation的GAN。
具体来说它是怎么样实现的呢?他就是暴搜了超参数,然后用了一堆trick,最终train出了性能。FED这个值在Sequence Generation任务用用于衡量生成的句子的好坏,越小越好。
9. More about Generative Model
其实Generative的Model除了GAN以外,还有其他的很多Generative的Model。例如VAE、FLOW-based Model等等
这些Generative Model都可以用于生成图片,但是使用VAE、FLOW-based Model得到的结果并不如GAN好。在他们的论文中,都是用了一堆Trick、然后暴搜了参数,最后说得到的结果和GAN差不多

以往的VAE和FLOW-based Model的课

10. Supervised Learning?
我们上面讲了这么一大堆,我们可能会有一个疑问,就是既然我们现在的目标是输入一个低维度Vector,输出一个表示图片的高维度Vector,那么为什么我们一定要用上面的这些做法而不能用Supervised Learning的方法一步到位呢?
我们给每一个头像一个从Gaussian Distribution中sample得到的向量,然后硬train一发,这样可不可以呢?
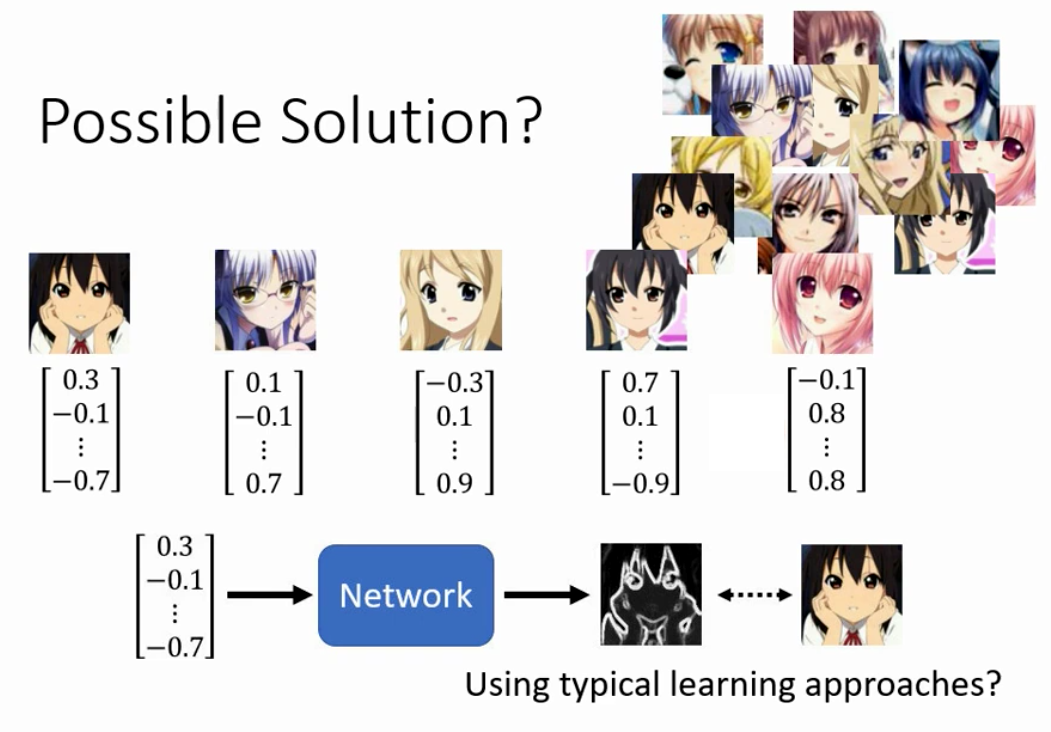
答案是其实是可以的,真的有人这样干。但是直接这样做得到的效果不好,必须要有特殊的手段,具体特殊的方法则参考这些论文。

我们以后面会讲到的Conditional GAN为例,Conditional GAN接受一个$x$和random variable $z$然后生成图片。我们现在假设$x$是一张label image,要求它输出原始图片。

如果我们现在用Supervised Learning硬train一发,得到的结果是这样的

我们会发现图像的边缘是非常模糊的。而造成这个现象的原因和前面的小精灵的例子是一样的,在训练数据中,存在多个窗户是中间这样,但是边界不同的房子。因此模型两边讨好的结果就是中间的窗户处清晰,但是边缘模糊的图片。
这也是为什么我们说需要使用额外的手段来确保生成的图片是清晰的。我们在最前面讲过,使用GAN确保输出是一个分布这样就可以保证输出的图片是清晰地。不同的房子由Random Variable来保证

11. Evaluation of GAN
我们接下来要讲的GAN中衡量生成得到的图像好坏的评估方法。

1. Problem of Human Evaluation
为了要衡量GAN生成的图片的质量的好坏,最直观的一个方法就是用人眼来看。可是用人眼来看就会产生很多问题。首先就是评价的标准不一样,有的人看可能觉得这张图片很好,而有的人看可能觉得这张图片很烂。
所以在过去的很长的一段时间,尤其是在人们刚开始研究GAN的时候,人们评价模型的好坏都是按照人眼来看的。所以那个时候结果都是吹得,只需要在appendix后面放几张实验图,然后说我觉得比现在文献上的结果都要好,所以我这个文章的结果就是State-of-the-Art,然后这样就结束了。
所以早年的研究GAN的paper,全篇都是没有数字的,只有最后的效果图让人眼来看。那么想也不用想,这样的结果肯定是不行的。
因此,人眼来看这种不稳定、不客观的方法肯定是不行的,我们需要有客观的、稳定的方法来评价生成的图片的质量。

2. Task Specific Evaluation
其实针对于特定的任务,我们是可以设计出来特定的Evaluation的方法的。
例如我们作业中的用GAN生成人脸的,那么我们其实可以利用Cascade Face Detection等成熟的人脸识别算法,或者说专门的动漫人脸检测的系统。然后来看看GAN生成的图片中有多少个是可以被检测到的,然后用这个准确率来作为Evaluation Metric。

3. Judge from Quality of Image
上面讲了如何对人脸的质量来进行判断,那么对于生成猫、狗这类更一般的GAN来说该怎么样衡量生成图片的好坏呢?为此,我们其实可以把上面的评价方法推广一下。
我们现在对于生成猫、狗等任务,我们可以用一个Train好的Classifier来计算accuracy,把accuracy视为Evaluation Metric。
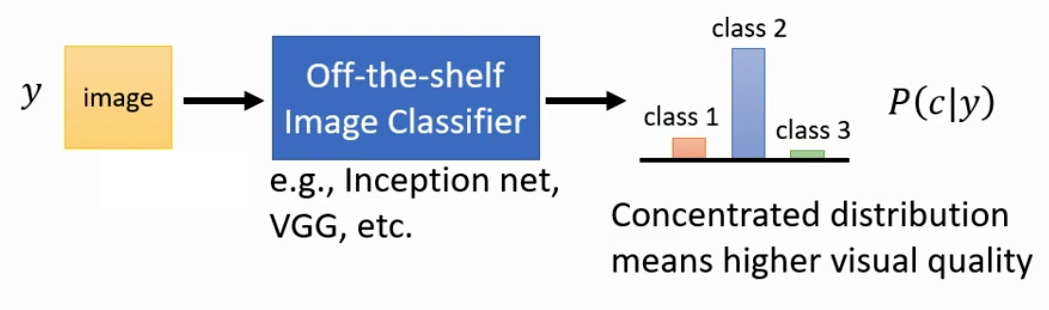
4. Judge from Diversity of Images
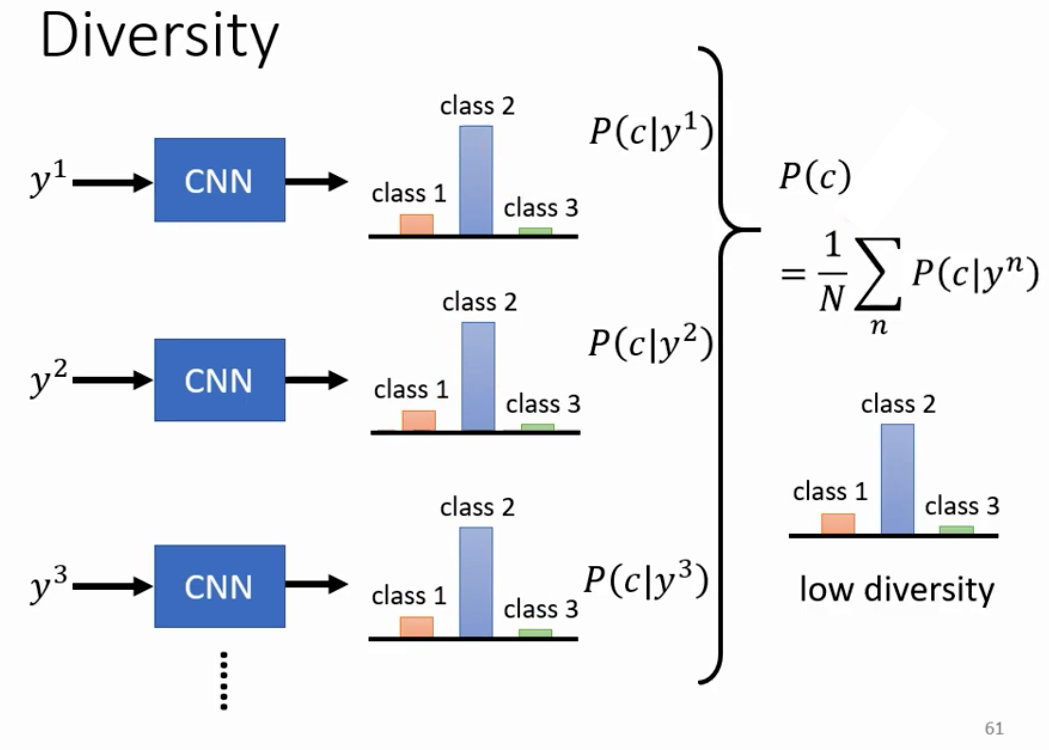
我们前面讲了GAN训练的过程中会有Mode Collapse和Mode Dropping这类Diversity的问题。因此,我们其实可以从模型生成的图像的Diversity来衡量模型的好坏。
这个时候我们可以把所有生成的图片经过Classifier之后的得到的概率向量的分布加起来求平均,如果最后是比较集中的,就证明Diversity比较小,因此不太好
而对于好的GAN来说,它输出的分布应该是非常diverse的,因此加起来的平均就会是一个uniform的Distribution。

我们需要注意的是,上面说的从图像的质量来衡量是针对一张图像而言的,我们希望得到的伪概率向量是越集中越好,而从图像(们)的多样性来说,我们希望Generator生成的所有的图像的分布是Diversity的,因此其实是针对两个不同的对象来衡量的,因此我们说是从两个角度来衡量Generator生成图像的效果。
5. Inception Score, IS
我们上面讲了如何用Classifier来衡量GAN得到的图片的好坏,而不同的Classifier计算得到的分数不同,因此我们如果想要比较的话,就需要使用一个固定的Classifier。
一般来说,大家用的都是inception score,即Classifier用的是inception net。

但是需要注意的是,Inception Score有些情况下并不适用,即生成的图片并不在Inception的Class中。
例如我们现在要生成手机,那么假设手机不是Inception所有的类别,那么就没有办法计算。其次,Inception的类别中的一些子类别也是没有办法的,例如生成动漫书,那么Inception很有可能会分类成书,而因为不是动漫书、故事书、课本等类别,所以不管怎么样算都会得到Low Diversity的结果。
6. Fréchet Inception Distance (FID)
除了IS之外,还有了一种新的衡量的方法,即计算FID。
FID的思想是不要用softmax之后的伪概率向量来判断Generator生成图像的好坏,而是用经过softmax之前的vector。
这个vector是一个长度和class数量相同的vector。而这个vector作为高维空间中的一个点,把所有的点画出来之后其实就可以看到Generator输出的分布。
然后我们同样的把真实数据的分布也这样计算出来,就得到了真实的分布和Generator输出的分布

我们假设,产生的和真实的图片在这个空间中都是服从Gaussian的Distribution,然后我们计算这两个Gaussian Distribution的FID作为评估的方法。
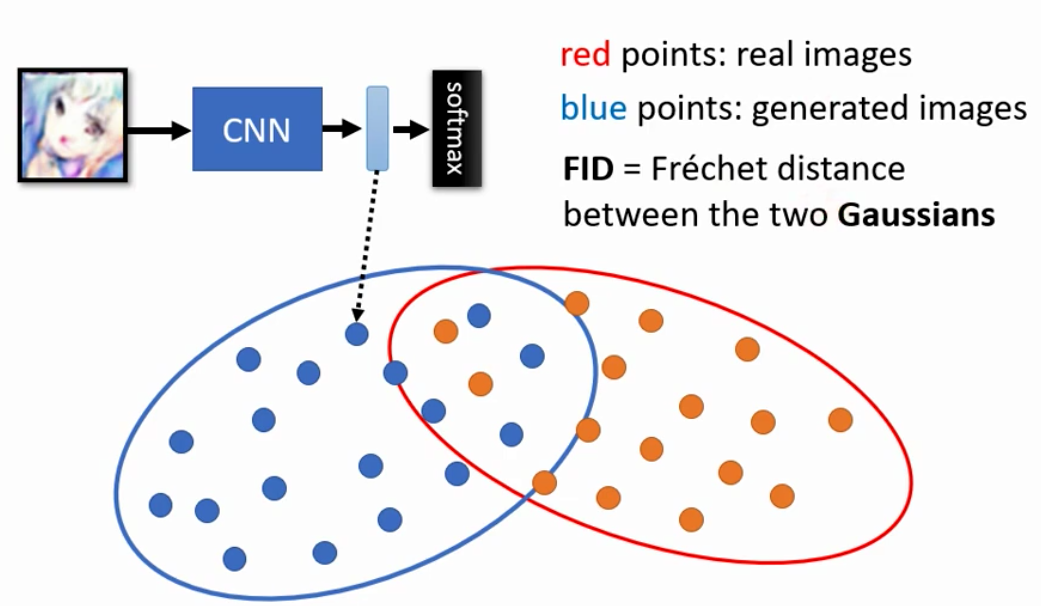
因为现在是Distance,所以其实Distance越小越好。
其次我们也不一定是一个Gaussian Distribution,这个数据点服从的分布是假设的,Gaussian不一定和它真实的分布类似。
7. More about Evaluation
其实上面讲的FID也是有问题,举例来说,如果现在我们的GAN只是单纯的记住了每一个输入。这样的话计算得到的FID就很小。
可是这样的GAN真的是我们需要的么?显然不是,因为我们希望GAN是能够生成新的图片的,如果只是单纯的记忆的话,那么我们为什么不直接从Dataset里面sample呢?

更棘手的是,还有单纯的翻转了图像这个问题

因此,其实GAN的Generator生成的结果的Evaluation其实是非常困难的,研究Evaluation的方法都可以写成一篇文章。

12. Conditional GAN
我们前面讲了,GAN根据输入可以分为两类,分别是:
- Conditional GAN:输入是$x$以及一个sample自某一个简单分布(一般是Gaussian Distribution)的随机变量$z$
- Unconditional GAN:输入是一个sample自某一个简单分布(一般是Gaussian Distribution)的随机变量$z$
我们上面讲的都是Unconditional的GAN,下面我们就来讲讲Conditional的GAN

1. Why Conditional GAN
1. Control Output of GAN
我们上面讲的都是Unconditional GAN。可是为什么还要有Unconditional GAN呢?其实第一个原因就是因为我们现在希望能够控制GAN来生成我们需要的东西。
因为对于Unconditional GAN来说,我们现在直到给它一个Gaussian Distribution中sample得到的vector,它确实可以生成一张图片的。但是它生成的图片是不受我们的控制的。我们并不知道给一个向量,他会生成什么样的图片。
因此,如果我们可以给一个GAN一个额外的输入(Condition)来控制生成的结果,那么其实就可以让GAN来完成一些额外的任务。
2. Different output
使用Conditional GAN的第二个原因就是因为我们希望在同样的Condition下,在Gaussian Distribution中sample得到不同vector生成的结构都是符合Condition的不同的结果。但是其他的Generative的模型并不能实现输出同一个Condition下得到不同的图像。
例如text-to-image任务,我们输入的文本,要求GAN生成符合我们文本要求的图片。这个时候,文本是input,图片是label,因此其实是一个有监督的任务,我们需要文本和图片的pair
然后我们给Generator输入除了Sample自Gaussian Distribution的Random Variable $z$以外,还有input的文本。这个input的本文我们当然可以用one-hot等方式转换成向量。但是正如我们前面说的embedding的问题,因此我们不妨先用一些方法尝试把高维度的One-Hot转换为Embedding。
在过去我们可以用Word Embedding、RNN,现在可能用Self-Attention等等,这个都是可以的。

而我们现在告诉机器说我们要生成一个红眼睛的角色,那么因为Sample得到的$z$的不同,可能生成酷拉皮卡,也有可能生成辉夜大小姐。
而这件事可以做到么?其实是真的可以做到的,在过去的课程中是真的有这个作业的

2. Conditional GAN
我们接下来就来讲讲Conditional GAN的架构。
1. Unconditional GAN Generator
首先是Conditional GAN的Generator。Conditional GAN的Generator会吃两个输入,具体吃入的方式可以是最前面说的$x$和$z$直接相加,也可以是$x$和$z$拼接起来,也可以是两个经过Transform之后相加……具体以哪种方式吃入两个输出,就看个人的设计。

2. Unconditional GAN Discriminator
而对于Discriminator来说,如果我们用Unconditional GAN的Discriminator的话,其实是有问题的
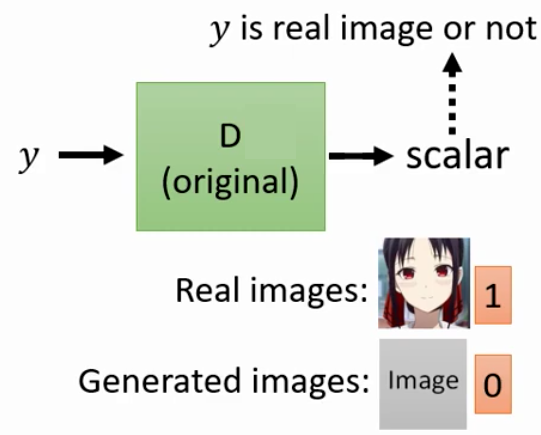
而如果Discriminator的输入只有生成的图片的话,那么Discriminator的目标其实就只是分辨这张图片到底是不是真实的。因此Generator最终只会学会生成非常真实的图片但是生成的非常逼真的图片和输入的Condition没有任何关系。
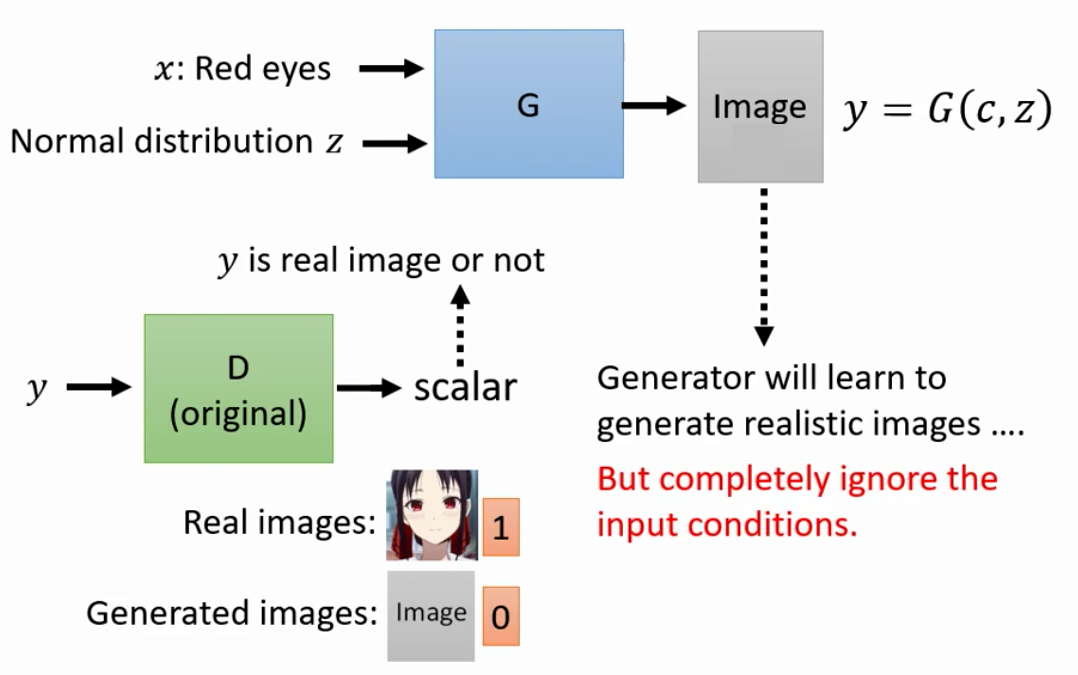
因此,我们的Generator现在也不能只吃生成的图片,也要吃入Condition $x$

因此,我们Discriminator对生成的图片在打分的时候,就要考虑两个因素,第一个是生成的图片是否逼真,另外一个就是生成的图片是否能和Condition match起来。
3. Unconditional GAN Data
除了GAN的Generator和Discriminator要做出改变以外,训练时候的数据也要有改变。我们因为会存在输出的图片和Condition Mismatch的现象,因此我们其实还需要有Mismatch的数据,这样的话Discriminator才会从Mismatch的数据中学到Mismatch这件事情,从而强迫Generator学会生成match的图片这件事

3. Conditional GAN Application
其实到这里,我们就讲完了Conditional GAN训练时候的注意事项。下面就来讲讲Conditional GAN的一些运用
1. Image Translation / Pix2Pix
除了上面讲的Text2Image任务以外,Conditional GAN其实完全可以以一张图片作为Condition,然后输出一张图片。
而这样的任务在实际中有非常多的应用。例如黑白图片上色、白天黑夜转换、设计图转效果图等等应用

2. Sound to Image
Conditional GAN的另外一个应用就是把声音转换成图片。虽然为什么要进行转换听起来可能很莫名其妙。

而对于Sound2Image任务来说,example就是pair在一起的音频和图像。这个数据其实并不是很难找,用电视剧的声音就行了

最后,这样的GAN实际训练下来的结果如下,上面的声音是水流的声音,那么机器在听到了之后就生成了一个小溪,而下面是一个发动机的声音,听到了之后机器就生成了一个快艇的图片

然后有一个神奇的现象,就是我们如果放大音频的音量,那么得到的图片如下。上面的图片中,随着流水声变大,模型的输出逐渐从消息变成了尼加拉瓜瀑布。而随着发动机声音越来越大,输出的快艇边上的水流越来越大。

但是需要说明的是,这个结果是挑选过的结果,并不是每一个图像都是这样的,例如给一段逐渐声音变大的钢琴声,输出的图像不知所云,只有声音合适的时候才生成了钢琴

3. Talking Head Generation
最近的一个使用GAN得到的惊艳的效果的任务就是让静态照片中的人脸说话

13. GAN for Unsupervised Learning
我们要讲的关于GAN的最后一个内容,就是如何用GAN来进行无监督学习,即从Unpaired Data中学习。
我们前面讲了Conditional GAN和Unconditional GAN。Conditional GAN和Unconditional GAN都是Supervised Learning。Conditional GAN是Supervised Learning非常好理解。而Unconditional GAN的话虽然训练过程中不需要Label,但是如果直接用它来硬train一发其实是有问题的,这个等下会详细的介绍。
但是为了用到Unsupervised Learning中,我们先讲讲如何把GAN用到Unsupervised Learning中。

1. Why Unsupervised GAN?
我们前面在作业中遇到了Semi-Supervised Learning,就是数据只有一部分是有Label的,而有一部分是没有Label的。在作业3中我们用的Pseudo Label来进行的Semi-Supervised Learning。
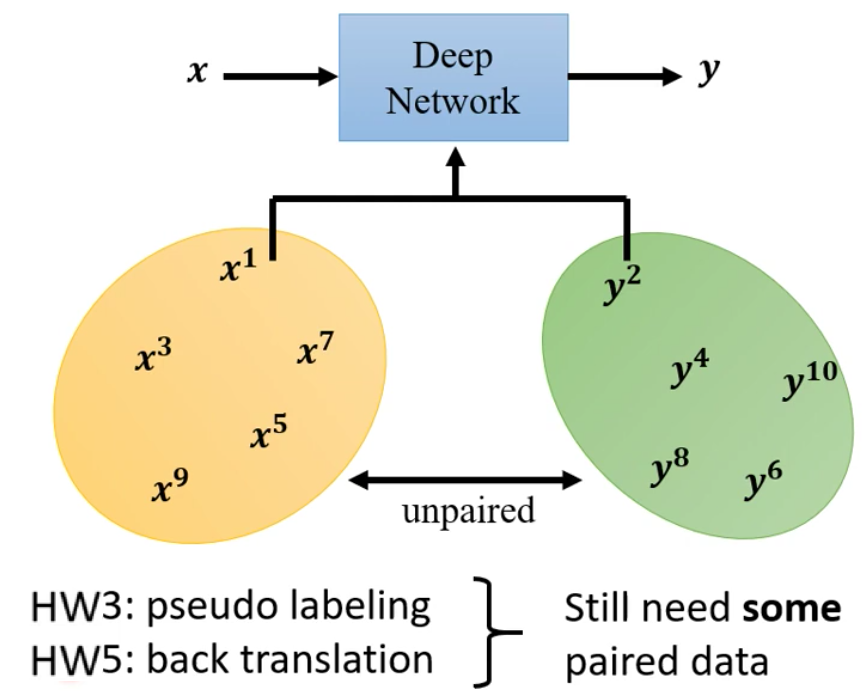
可是在有一些任务中,我们的数据是完全没有label的,例如图像风格迁移。我们要把$x$ domain中的图片转移到$y$ domain中,例如把照片转换到漫画风格。

这个时候就根本没有Label,因此就需要对GAN进行改进,让其进行Unsupervised Learning。

2. Why not Unconditional GAN?
我们前面说GAN的输入是有一个Gaussian Distribution,然后输出也是一个Distribution。为了遵从Unsupervised Learning中的惯用语,我们这里用Domain而不是Distribution。
那么GAN的任务就是把X Domain中的数据经过变换到Y Domain中去。注意,这个时候X Domain不一定是我们前面说的一个来自Gaussian的low Dimension的variable,他可以使一个high Dimension的vector

而Unconditional GAN只需要一些真实的图片,因此也是Unsupervised Learning,那么我们为什么不用Unconditional GAN来做Unsupervised Learning呢?
这是因为,如果用Unconditional GAN来硬做Unsupervised Learning的话,会遇到和前面Conditional GAN一样的Mismatch的问题。
例如对于上面这个图像风格迁移问题来说,如果用Unconditional的Learning的话,那么Discriminator只会看生成的图片是否逼真,而不会看生成的图片是否是和输入的X Domain的图片是否是一一对应的。
这个时候对于Generator来说,他很有可能把X Domain的图片当做是High Dimensional的Gaussian Distribution

在Conditional GAN中解决这个问题是依靠paired data解决的,可是在UnconditionalGAN来说,就没有办法了。
3. Cycle GAN
为了解决上面说的问题,有一个想法就是Cycle GAN。Cycle GAN中train了两个Generation,第一个Generator是把输出从X Domain转到Y Domain上去,而第二个Generator是把Y Domain的输入转会X Domain上去。
这样强迫第一个Generator学会的Transformation是可逆的,因此就存在了一个映射关系,从而使得Transform的结果和X Domain中的图片是Match的。
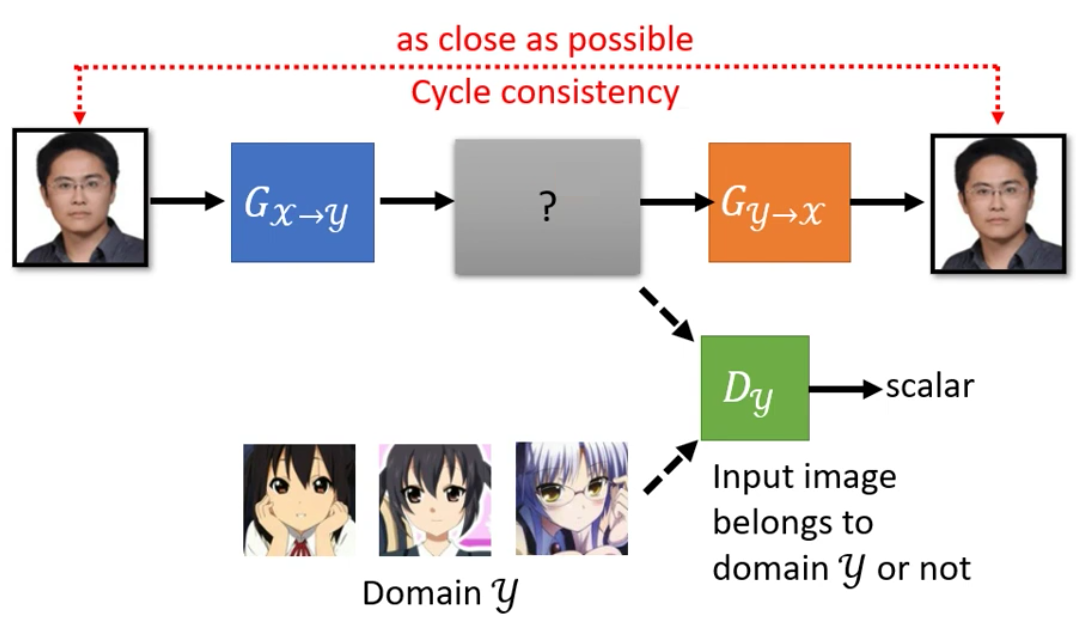
因此,CycleGAN在训练的过程中的训练目标除了第一个Generator生成的动漫头像Discriminator无法分辨以外,还有第二个Generator生成的图片和原来的输入要尽可能一致。
虽然CycleGAN听起来比较靠谱,但是其实是没有办法处理一个问题的,就是第一个Generator学会了图像左右翻转,第二个Generator也学会了图像左右翻转。这样的奇怪的转换满足我们的要求,但是得到的图片的质量显然不高。
这样的状况在CycleGAN上确实有可能会发生,而且也无法避免。但是这个状况一般不会发生,或者说发生概率比较小
4. More about CycleGAN
其实关于CycleGAN,有一个比较神奇的事情就是,几乎在同一个时间,三个不同的团队都提出来了CycleGAN,虽然名字不一样,但是干的都是同一件事。

此外,StarGAN能够实现多个风格之间的转换
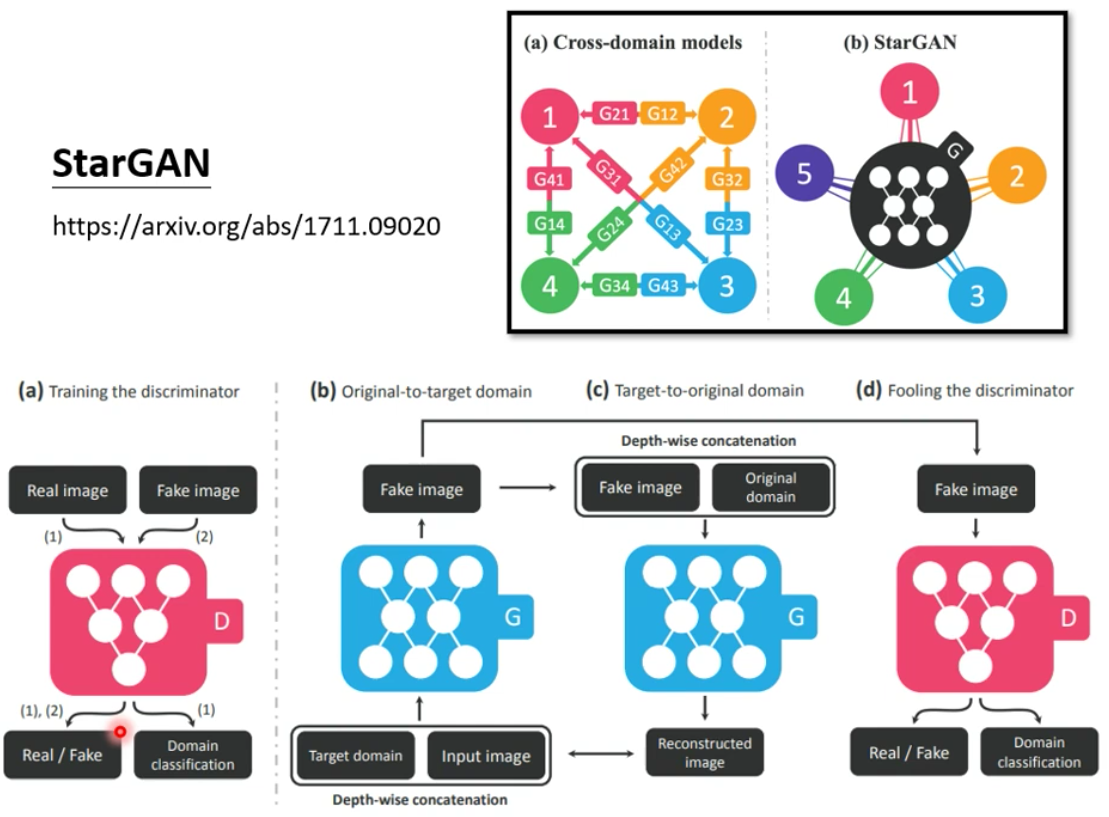
5. Application of CycleGAN
我们最后讲一讲CycleGAN的作用
1. Selfie2Anime
最后上面这个把照片转成真人头像这个任务是真实可行的

2. Text Style Transfer
同样的,我们也可以进行Text Style Transfer,即转换文本的情感。

而这个任务我们就用CycleGAN,什么都不用改

最后,得到的效果如下,我们可以看到,有的效果确实不错,而有的生成的句子则不知所云

3. More tasks
Unsupervised Learning还可以解决其他的各种任务,具体如下图所示




