本文是Machine Learning 2021 Spring 第九节课的笔记,本节课主要讲解了基于Attention(Self-Attention)机制的网络:Transformer,包括Self-Attention和Seq2Seq的网络结构。

李宏毅ML2021-Spring-9: Transformer
在前面的课程中,我们很多次的提到了Transformer,因为在Transformer之前,深度学习的发展大致分为:
- 上古时期:Alexnet出现之前
- Alexnet:Alexnet重燃了大家对深度学习的热情,很多研究员都被DL吸引,开始研究DL
- 大发展时期:在Alexnet提出了之后,大家都一股脑的扎入了DL的领域。这个时候DL训练时候的很多问题就逐渐的暴露了出来,例如梯度消失、不收敛……在这个阶段,人们逐渐的解决了这些问题,渐渐地使得训练一个work的模型越来越简单,人们对DL的认识也越来越深刻
- ResNet:而ResNet的提出很好的解决了深层网络训练过程中梯度消失的问题,配合kaiming初始化,使得人们能够几乎训练任意深度的网络,因此极大地提升了人们探索模型的能力。从这以后模型越来越复杂,越来越大
- 注意力时期:在ResNet之后,人们从人类的在观察的时候会有注意力这个角度出发,开始通过各种不同的方式给网络中引入注意力。而不同的方法对注意力的定义不同,因此引入的方法也不同。
- Transformer:Transformer中抛弃了CNN的卷积,而完全使用Self-Attention,取得了巨大的进步。从此以后,使用Self-Attention来作为注意力就几乎成了注意力机制的范式,而Transformer的架构类似于ResNet一样,称成为了网络的经典范式。
可以说,在目前的阶段,Transformer架构为基础的模型基本上已经占据了半壁江山,很多新的模型都是在Transformer的架构的基础上修改得到的,例如:ViT(Vision Transformer)、Swin Transformer……
因此我们还是需要来学习一下Transformer这个网络架构的。
当我们说到Transformer的时候,我们第一个想到的就是变形金刚,因为变形金刚的英文名就是Transformer😂

此外,课程后面会讲到的bert就是在Transformer基础上建立的模型,而bert是芝麻街里的一个怪物(Monster),所以我们说到Transformer的时候还会想到这个怪物。
1. Introduction of Seq2Seq
Transformer是一个Seq2Seq的模型,其通过Self-Attention结构,同时实现了Seq2Seq和Attention两个能力。
因此在开始介绍Transformer之前,我们最好还是介绍一下Seq2Seq模型以及Seq2Seq模型的作用。
1. Sequence-to-Sequence
在上一节课:Self-Attention中,我们介绍了一类新的模型,和全连接、CNN不同,这类网络的输入是具有上下文关系的Vector Set。然后根据这类模型输入和输出的关系,我们又进一步把这类模型分为了三类:
- 输入和输出等长的模型,这类模型又称为Sequence Labeling的模型
- 输出只有一个值,这类模型又称为Sequence Regression/Classification的模型
- 输入和输出不等长(由网络自己决定),这个时候因为输入和输出都是具有独立的、完整含义的Sequence,因此这类模型又称为Sequence to Sequence的模型,简称为Seq2Seq

2. Application of Seq2Seq
我们下面讲讲Seq2Seq模型的一些运用
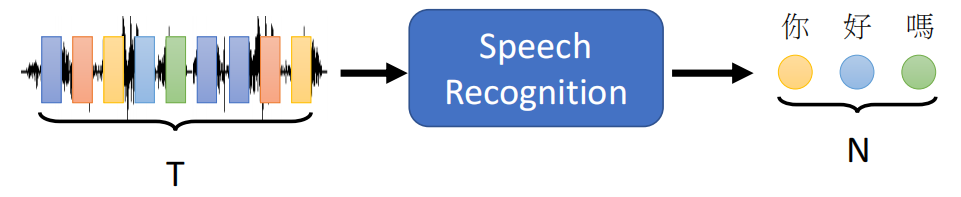
A. Speech Recognition
在语音辨识的时候,输入的语音是一段PCM波形信号转换之后得到的向量,而输出是这段语音对应的文本。而输入和输出都是具有独立含义的Sequence。
我们前面在作业二的时候,讲过了Phoneme的Classification,我们讲到用MFCC、filter bank等算法实现把一小段语音讯号(25ms左右)转换为一个长度为39或者其他长度的向量。然后通过Sliding Window把一个长度为1秒的语音信号转换成100个向量的集合。
但是1秒的语音转换成文字可能就几个字,因此完成Speech Recognition任务的模型的输入输出就是长度不等的,因此Speech Recognition任务的Model就是Seq2Seq。
B. Machine Translation
机器翻译同样也是输入和输出不等长的例子,例如几个字的中文(文言文)就可以翻译成很长的英文。因此机器翻译也可以用Seq2Seq的模型来解决。

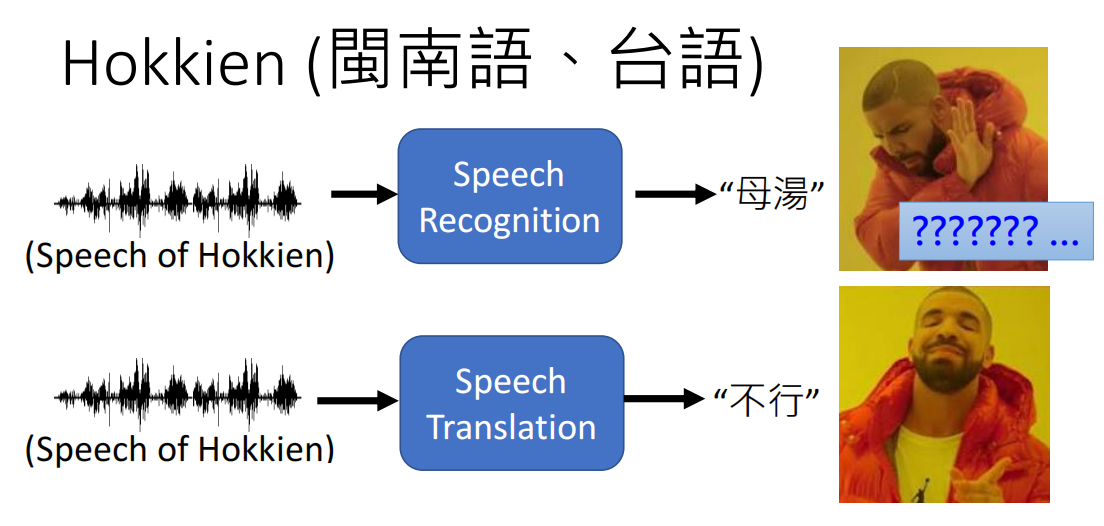
C. Speech Translation
还有一类人物就是语音翻译,语音翻译指的是模型现在的输入是一段语音信号,而输出则是另外一个语言的文本。

虽然我们轻易就能知道Speech Translation的输入和输出是不等长的,可是我们就会问,为什么不把语音识别的模型和机器翻译的模型接起来,而非要在提出一个Speech Translation的模型呢?
其实是因为,现在世界上有7000多种语言,其中一半都是没有文字的。而没有文字的语言是没有办法进行语音识别的,因此我们是有必要直接得到一个Speech Translation的模型的。
其次,使用一个专精某个任务的模型其实是比两个模型的效果好而且开销要低很多。
D. Chat Bot
使用Seq2Seq模型,还可以做出来一个聊天机器人。因为聊天时候的前后两句话其实长度是不一定相等的。

而这个时候我们的训练的数据就可以来自于剧本。

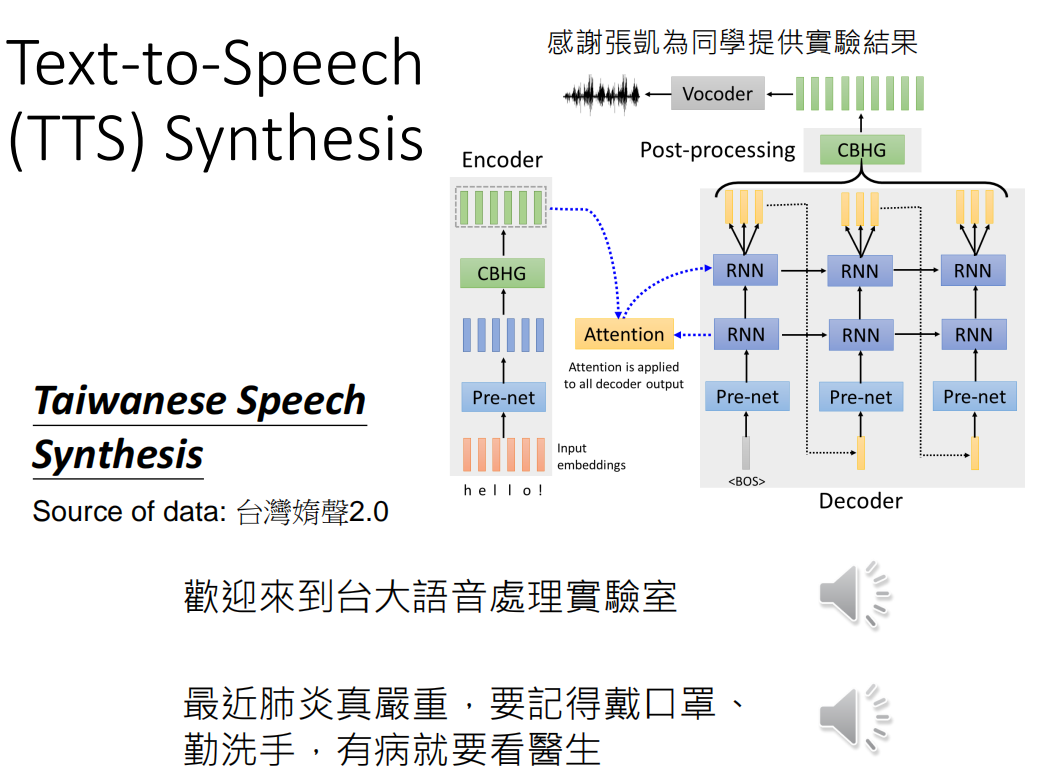
3. Case Study: 闽南语/台语转中文
举一个真实的Seq2Seq的Speech Translation的例子,就是把闽南语/台语转换成中文文本。
A. task identification
虽然说台语的确是有自己的文字的,但是绝大多数人都看不懂泰台语的文字。例如用一个台语语音识别的模型来做的话,现在给一段台语的语音信号,转换出来的台语文字其实是看不懂的
因此我们就需要一个Speech Translation的模型,即把闽南语当做是外语来翻译。
B. Preparation of dataset
要完成台语的Speech Translation的Task的话,我们需要的训练数据是台语的语言和对应的中文文本作为label。
这样的数据还是很好收集的,直接去YouTube上搜索肥皂剧/乡土剧的视频即可。把语音从视频里面抠出来,然后把字幕作为label。

有了数据之后,我们接下来就可以用各种各样的Seq2Seq的模型来完成Speech Translation任务,包括我们后面要讲的Transformer模型。我们进行了真实的实验,下载了1500个小时的乡土剧来训练模型,最后得到了一个模型。
C. Dataset ShortComing
其实我们直接用上面这些来自于肥皂剧的数据来进行训练是有不少问题的:
电视剧里的背景音乐如何处理?
- 答:不理他

字母和语音如果有错位(mismatch)怎么办?
- 答:不理他

为什么直接用mp3而不是先转成台语的Phoneme?
答:为了方便……

所以,像上面这样明明问题很大,但是没有管这些直接训练一个模型出来的方法,叫做:硬(Ying)train一(Yi)发(fa)😂

D. Results
最后是上面硬Train一发得到的模型的一些结果。
第一个例子(中文发音:你身体无刊),但是机器听到无刊的时候能够正确的翻译成撑不住

第二个例子(中文发音:没代没志,你系为嘎母亲家),而机器听到了没代没志之后就直到是没事

虽然有一些成功的例子,但是机器其实也是会犯错的,例如下面的例子:
第三个例子(中文发音:梅涩弄),而一开始李宏毅老师听到之后的结果和机器给出来的结果一样,都是要生了吗。但这句话正确的翻译却是:不会腻嘛
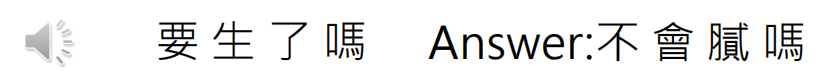
第四个例子(中文发音:我有答强奖拜托),这个是一个倒装句,正确的翻译应该是我拜托厂长了,但是机器的翻译却是:我有帮厂长拜托,所以机器其实没有学习到这个倒装句

而反过来,就是语音合成任务,不过由于没法把模型合成的声音进行播放,所以就略掉这部分
2. More General Seq2Seq
我们上面讲的一些任务,他们的特点都是输入和输出是非常明显的不相等的关系。但是需要注意的是,Seq2Seq模型的应用其实非常非常非常广泛,千万不要被输入和输出不等长这个特点迷惑住。
很多即便是输入和输出等长、只有一个输出,乃至有一些问题的输出都不是Sequence的任务也可以用Seq2Seq来解。
而能够用Seq2Seq模型来解的任务,我们首先要把他们抽象成一个QA问题,然后再把任务的数据转化为Sequence数据。
下面就将讲解这两步,以实现Seq2Seq模型更广泛的运用。
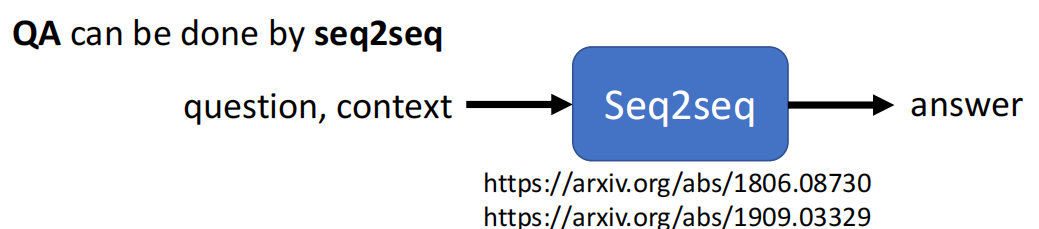
1. Question Answering
所谓的问答系统指的是给机器一个文章(序列输入),然后问机器一个问题,让机器给出来答案(输出)。注意,Question Answering并不是一个具体的任务,而是我们认知上的概念。
通过看能否把一个具体的Task抽象为Question Answering,我们其实就可以知道一个任务能不能用Seq2Seq模型来解。而Question Answering的关键就在于如何提出问题,因为输入和答案其实就是任务的数据
下面举几个通过把Task抽象成QA的从而使用Seq2Seq来解例子:
- 机器翻译:输入是一篇文章,问题是这个文章的德语翻译是什么,输出是德语句子(Label)
- 文章摘要:输入是一篇文章,问题是这个文章的摘要是什么,输出就是摘要
- 情感分析:输入是一篇文章,问题是这个句子的情感是正面的还是负面的。
- 动作预测:输入是过去人的动作,问题是未来人的动作是什么

那么假如说我们现在已经把一个Task转换为了QA问题,那么我们该如何使用Seq2Seq来进行求解呢?可以参考下面的两篇文章:
这两篇文章直接从问题和文章的抽象概念出发,一步步说明该如何用Seq2Seq来求解
2. Output as Sequence
在把问题抽象为QA问题之后,我们还需要做的一个步骤就是把任务的输出变换为一个序列(Sequence)数据。变换的方式有很多,这个具体就看具体的数据的label的格式自己来思考。
下面举一个文法剖析(Syntactic Parsing)的例子。所谓文法剖析指的就是现在给机器一个句子,句子要给出整个句子的文法。例如,现在给机器一句话:Deep learning is very powerful。那么机器要能够划分出来:deep learning在一起构成名字短语,very power在一起构成状语、is very powerful在一起构成动词、状语结构,最终所有词语在一起构成一个句子。

所以,文法剖析这个任务的目标就是输入是一个句子,输出是一个文法的解析树。

可是这个输出是一个树状结构,因此我们如果想要用Seq2Seq的模型来解的话,就要把树状结构转换为一个Sequence。那么这件事情其实是办得到的,我们可以用括号来表示不同的层级,即

而这件事情,在文章Grammer as a Foreign Language中做到了

这篇文章现在是古早时期的Paper,在这篇文章出来之前,Seq2Seq模型并不是非常的流程,而且主要用于翻译问题上。所以这篇文章才起了Grammer as a Foregin Language这个名字,意思是把文法当做是一门外语来进行翻译。
李宏毅老师上课时候讲,又一次开会老师遇到了这个文章的一作,那个时候大家都不太熟悉Seq2Seq的模型,于是李宏毅老师问一作训练Seq2Seq有没有什么特别的trick,结果没想到一作说没有什么Trick,他们甚至连Adam都没有用,简单的SGD就Train起来了,而且第一次Train性能就很好。只不过为了达到State-of-the-Art的精度还是稍微调了一下参数。
再举一个例子,Multi-Label的分类问题。和Multi-Class不同,Multi-Class指的是有很多个Class而每一个物体只能有一个Label。而Multi-Label则指的是一个物体可以有很多个Label。例如特朗普出轨这个新闻分类的时候既可以是政治新闻,又可以是桃色新闻,还可以是娱乐新闻……
那我们就会说,能否取输出的Possibility Vector中的前几位作为Multi-Label呢?这样做其实是有问题的,因为Multi-Label的话每个object的Label数量可能是不相等的。

这个问题其实可以用Seq2Seq来硬做,即硬Train一发,损失函数除了分类的损失函数以外,再加上输出的Label数量的损失函数
有些甚至输入数据和Sequence完全无关、看起来甚至和Seq2Seq八竿子打不着的问题都可以用Seq2Seq来求解,例如Object Detection

3. QA is not the best
需要说明的是,经过前面两步,我们其实可以用Seq2Seq来求解很多的问题,但是需要注意的是,有一些任务中,Seq2Seq往往不是最好的模型。
打个形象的比喻,Seq2Seq就是一个瑞士军刀,我们可以用瑞士军来切菜、砍柴,但是瑞士军刀不见得是最好用的工具。往往为了这些任务特制化的工具才是最好用的工具。即牺牲通用性换取了高精度。例如Google的英语转文字的模型Pixel 4,里面就没有用Seq2Seq的模型,而是从语音数据的特点出发设计的模型。
而这些任务特质化的模型的讲解,就不是我们这个课程讲解的内容了,如果想学习可以参考李宏毅老师之前的课程: https://speech.ee.ntu.edu.tw/~hylee/dlhlp/2020-spring.html
3. Transformer
千呼万唤始出来,前面我们为了讲Transformer,讲解了一大堆的Seq2Seq模型作为铺垫,现在终于讲到了Transformer模型。下面就将开始讲解Transformer的架构。
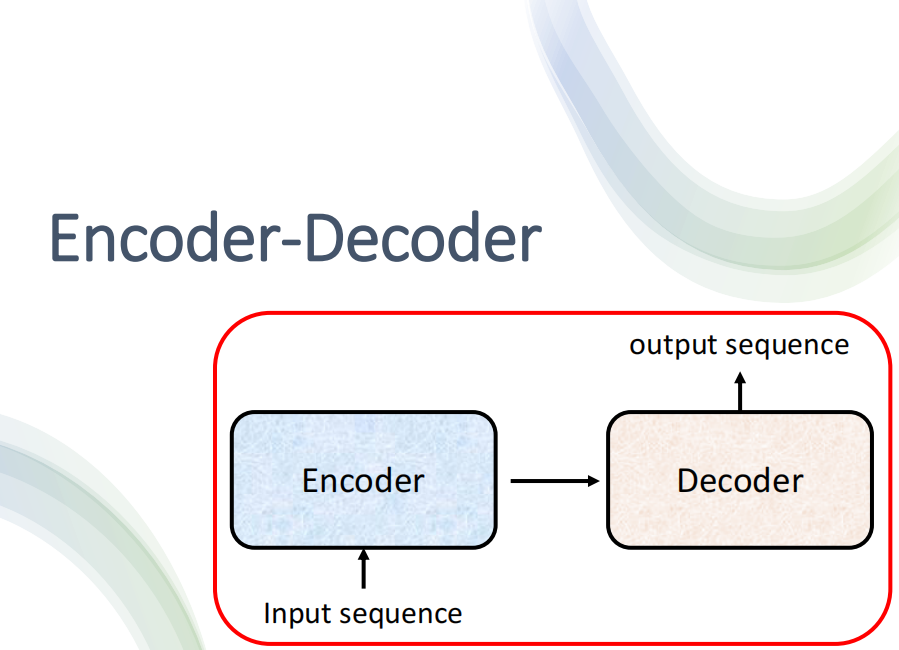
1. Overview of Transformer(Seq2Seq)
(因为Transformer是Seq2Seq的模型,)我们不妨先看看Transformer(Seq2Seq)模型的结构。
总的来说,Seq2Seq模型分为两部分:Encoder和Decoder。Encoder的作用是接受一个输入,然后对输入进行处理之后把处理的结果交给Decoder,由Decoder决定要输出什么样的Sequence。
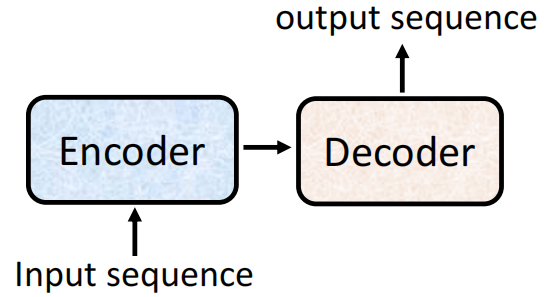
更加详细的结构如下图,下图是2014年Seq2Seq第一次被提出的时文章的图

而到了今天,当提起Seq2Seq模型的时候,大家脑子里的第一个印象就是Transformer的结构图,下面这些花花绿绿的block我们接下来就会进行讲解

2. Encoder
我们上面说到,Transformer架构也分为Encoder和Decoder两个部分,因此我们下面就来讲解一下Encoder部分

A. Purpose of Encoder
Encoder的作用就是吃进去一排向量,然后吐出来一排向量。

那么我们可能第一个想到的,就是上节课讲的Self-Attention的结构,其实除了Self-Attention的结构可以用作Encoder以外,RNN、CNN都可以吃入一排向量,然后输出一排向量,因此他们也可以用作Encoder。
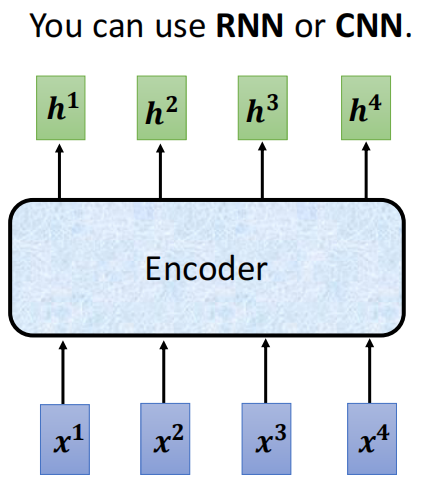
而Transformer的Encoder用的用的就是Self-Attention的结构。
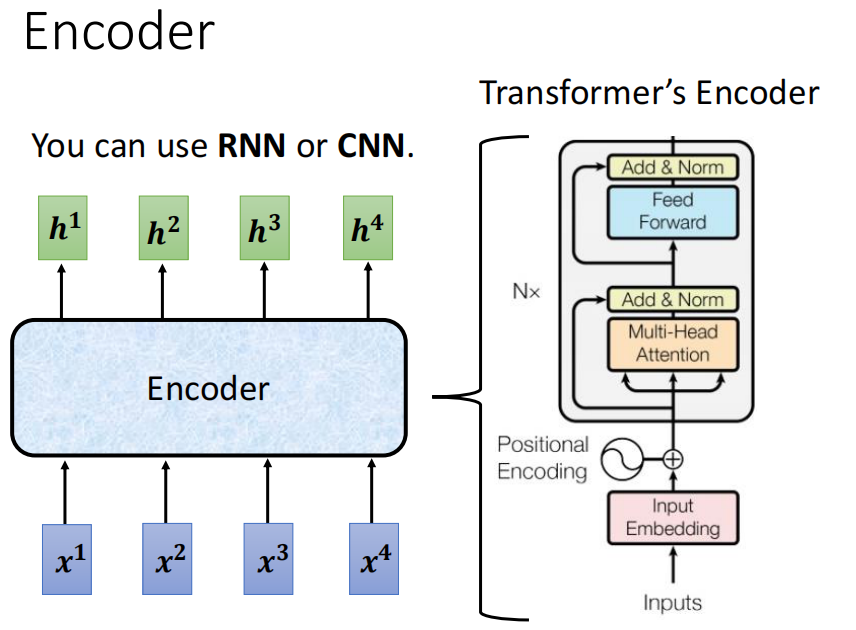
B. Transformer Encoder
我们前面讲到的Self-Attention的结构是一层Self-Attention层提取上下文信息,然后一层FC提取局部信息。然后不断交替
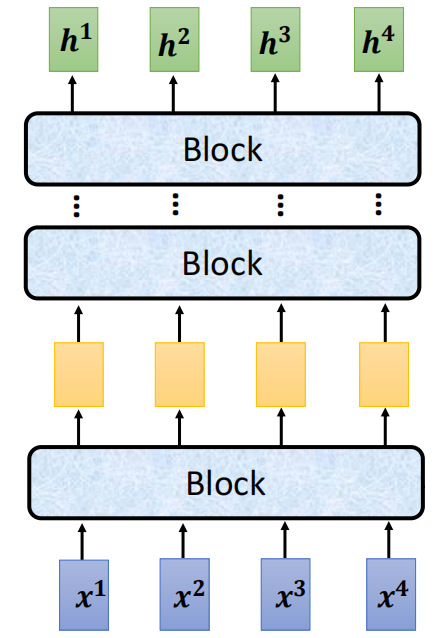
为什么上面的图里用的是Block,其实是因为Transformer的Encoder中的Block除了Self-Attention以外,还干了很多的事情。但是中间的输出数列都是和Self-Attention保持一样的

我们下面详细的来介绍一下Transformer的Encoder。
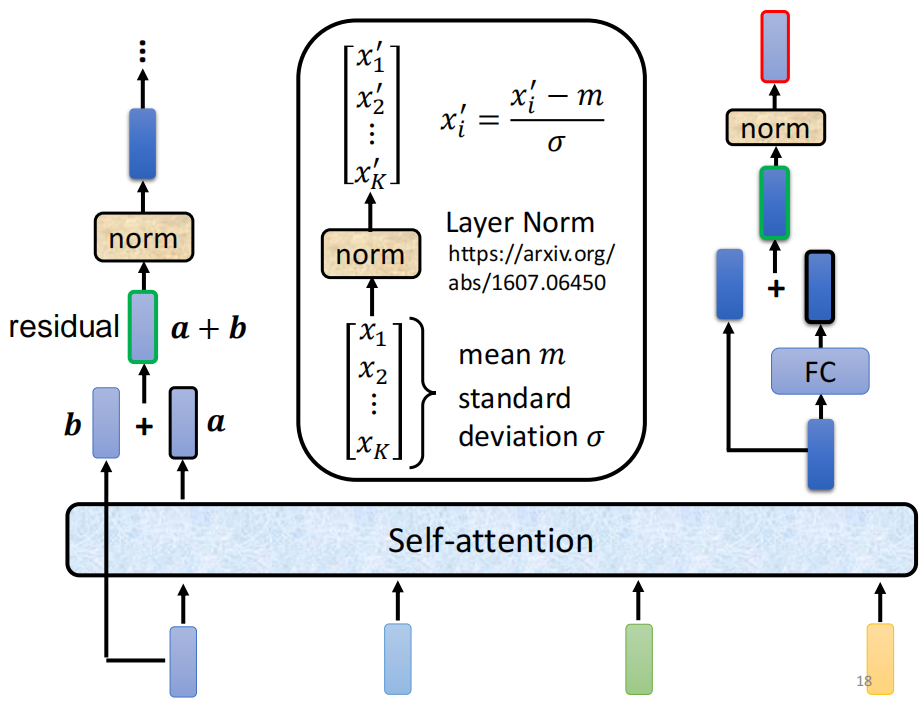
首先在经过一个Self-Attention的Layer之后,得到含有上下文信息的输出,但是在这个基础上,又增加了Residual Connect。

然后这还不算完,接下来又对residual之后得到的输出进行Layer Normalization。Batch Normalization是针对不同的example的同一个Dimension计算,而Layer Normalization则是针对同一个example的不同的Dimension进行的

最终,在经过了Layer Normalization之后得到的输出才是FC的输入。而FC也会有一个Residual Connection,在计算完Residual之后也会计算Layer Normalization,最后得到的才是这一个Block的输出。
对照论文里的图给出的Encoder的结构,输入首先被添加了一个Positional Encoding,然后用了Multi-Head Attention,接下来把Residual和Layer Normalization画在一起,然后Feed Forward表示全连接。
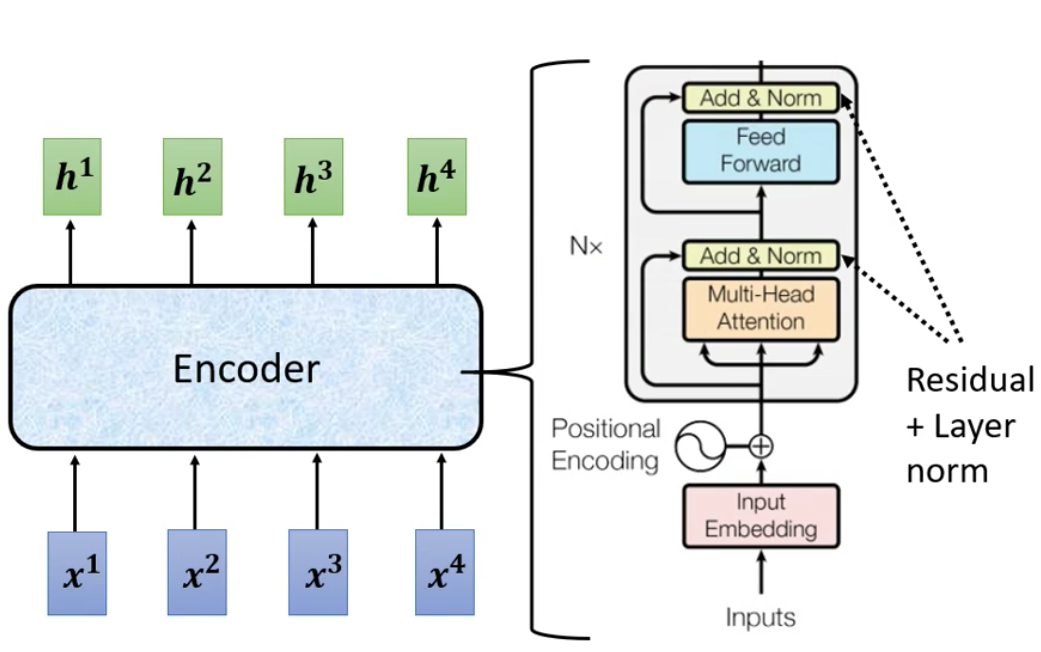
以上就是Transformer的Encoder的结构。而在接下来我们会讲到的Bert模型的Encoder用的就是Transformer的Encoder
C. More about Transformer Encoder
我们在学习了Transformer的Encoder之后,我们就会有一些疑问:
- 为什么Encoder要这样设计?能不能不这样设计?
- 答案:行
- 为什么要在Residual之后进行Layer Normalization?能不能在别的地方进行Layer Normalization?
- 答案:行
我们这里是按照Transformer的原始的结构来讲的,而原始的结构不一定是最好的结构,例如有一篇文章:On Layer Normalization in the Transformer Architecture,里面就讨论了为什么Layer Normalization就要放在那个地方呢?Layer Normalization能不能放在别的地方?能不能把Layer Normalization放到别的地方?
这篇文章里把Layer Normalization放到了每个Block里面,结果发现效果更好

然后还有问题,就是为什么要用Layer Normalization?能不能用Batch Normalization?这个也有文章在讨论,文章里提出了Power Normalization,他首先讲为什么Batch Normalization不如Layer Normalization,然后根据他的理解提出了效果更好的Power Normalization
3. Decoder
上面讲完了Encoder,我们接下来讲一下Decoder的部分
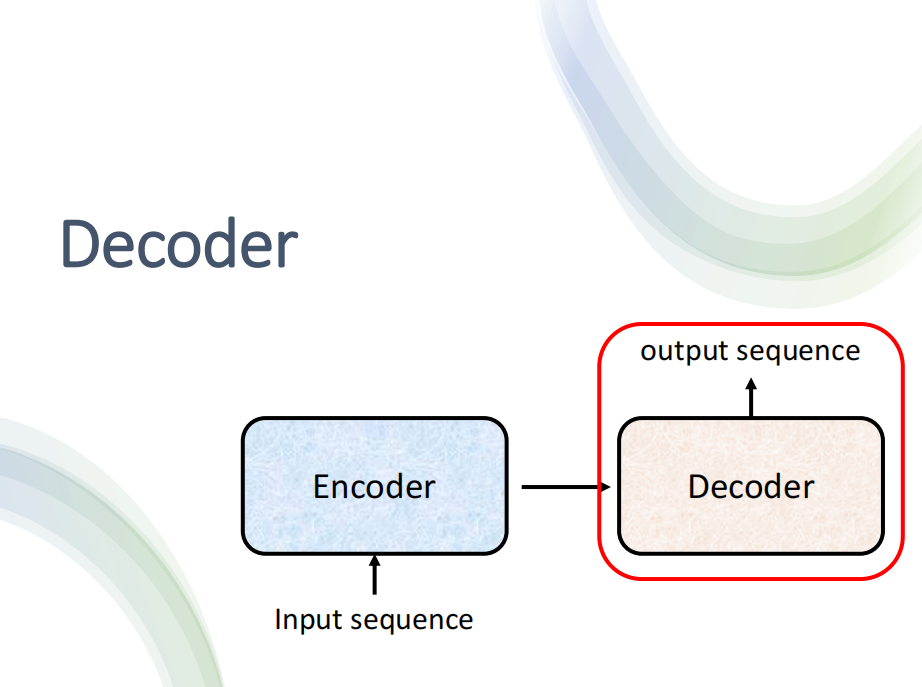
而常见的Decoder的结构有两种:
- 一种是AutoRegressive的Decoder
- 另外一种是Non-AutoRegressive的Decoder
下面就来讲讲这两种Decoder
4. AutoRegressive Decoder
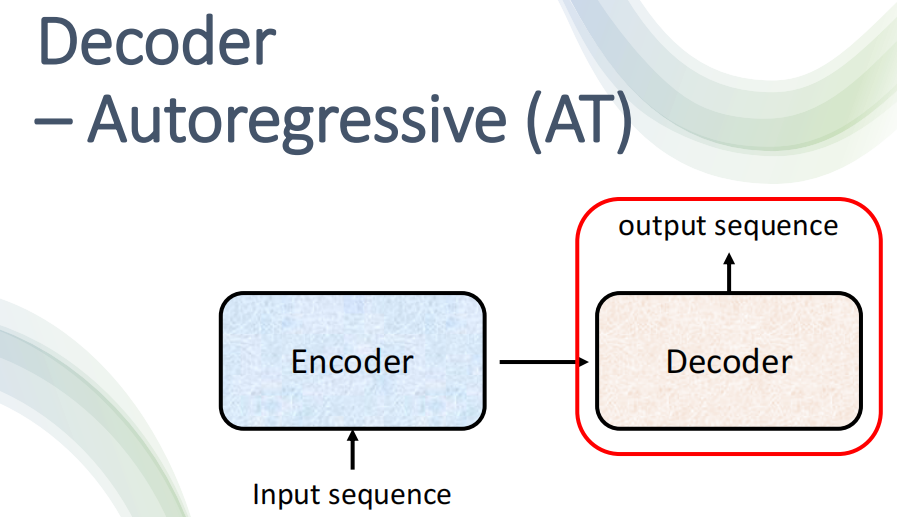
我们接下来结合语音识别的例子来讲讲AutoRegressive的Decoder是如何工作的。
A. Before Decoder
我们上面讲了Encoder,Encoder接收一排向量,然后输出一个向量。在语音识别的例子中,Encoder吃入的向量组是转换成向量的语音信号,然后输出一堆向量

然后Decoder就会接受这一排向量作为输入,然后开始产生语音识别的结果

B. Output of Decoder
我们接下来先不去考究Decoder内部的结构,先从输入输出的角度讲讲Decoder是如何给出来输出的。
Decoder除了会吃Encoder的输出以外,还会吃一个特殊的符号(BOS:Begin of Sentence)来表示句子的开始,这个符号就在我们的lexicon里面,和其他的字符的地位是同等的

在吃了这个特殊的符号之后,Decoder会输出一个长度和我们的Vocabulary长度一样的向量。而Vocabulary则是模型所有可能的输出在一起构成的表。
例如,如果我们模型的输出的英文的字母的话,那么输出的向量的长度是26维的向量,每一个维度表示一个单词。如果模型输出的英文的单词的话,假设现在只有4000个词语,那么模型的输出是长度为4000的向量。如果模型输出的是中文文字的话,那么假设有8000个汉字,那么输出的向量是长度为8000的向量。
类似于分类一样,我们对输出的向量取一个Softmax,然后取最大值作为输出的class。需要注意的是,这里用Softmax只是单纯的为了把所有的值归一化到0~1,与概率无关
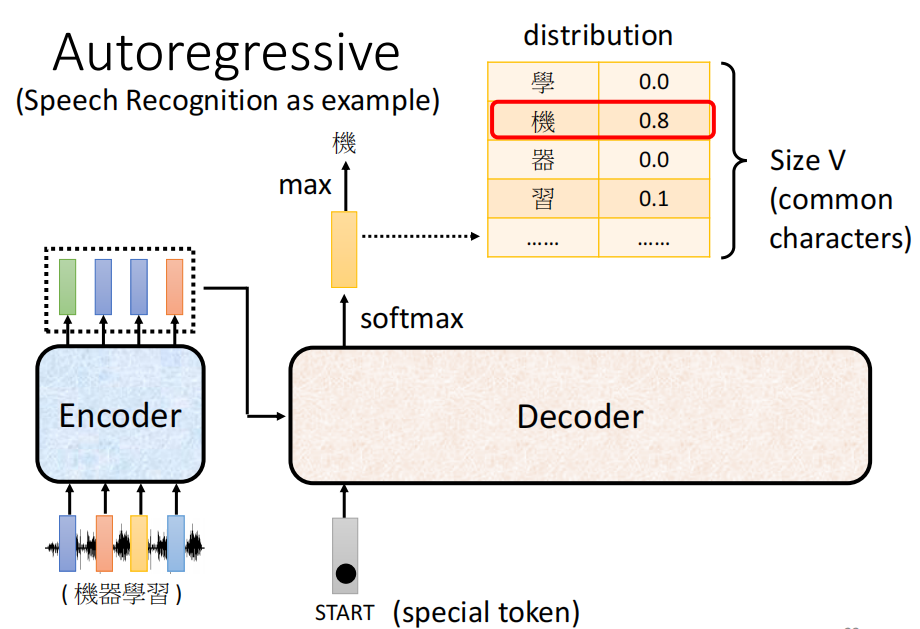
接下来第二步,我们就把模型的第一个输出当做第二个输入,得到第二个输出

同理,这个过程我们不断反复的执行下去,就得到的很多的输出
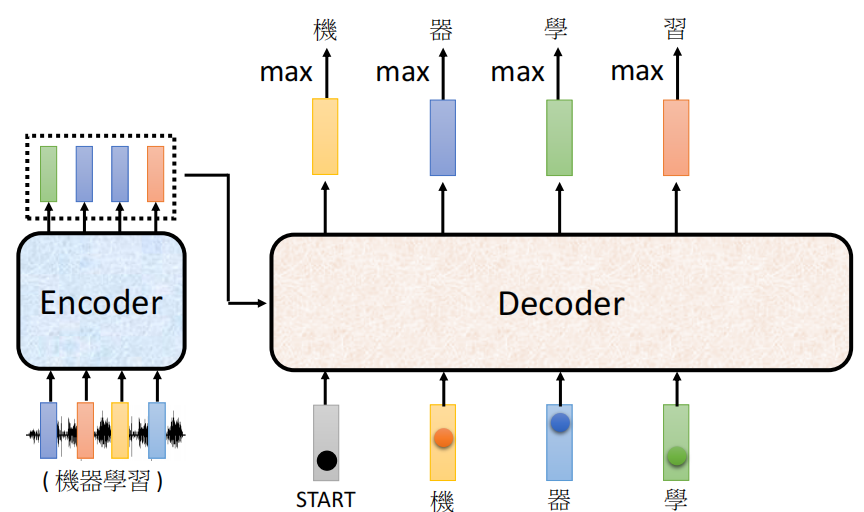
因此,除了第一个特殊符号意外,Decoder的输入其实都是自己的输出。
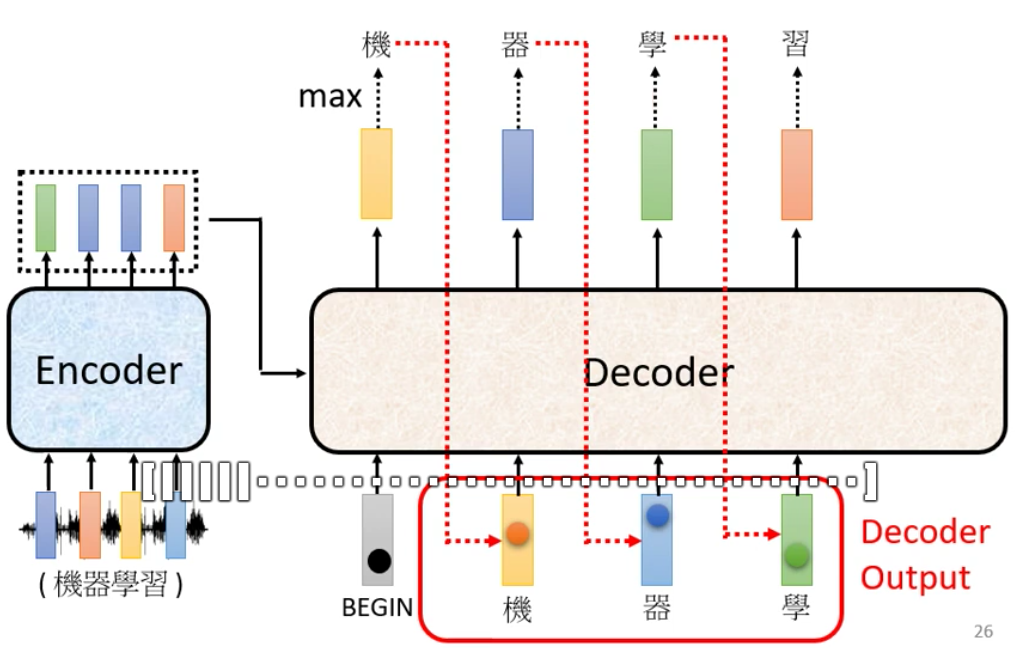
C. Problem of Decoder
因为Decoder的输入都是自己的输出,所以其实会有一个Error Propagation的问题,即如果网络中间某一次输出是错误的,那么会不会导致接下里的输出也是错误的?毕竟Decoder是基于输入得到的输出。

D. Structure of Decoder
我们接下来看看Decoder内部的结构,这里我们先关注Decoder如何通过自己的输出来得到新的输出,这里先忽略掉来自于Encoder的Output,等下在将这部分。
我们先来看看Transformer论文中Decoder的结构图,可以看到还是有很多花花绿绿的Block

我们把Encoder和Decoder拿来比较一下,就会发现Decoder相比于Encoder多了中间的一个部分

而除了中间这个部分意外,Encoder和Decoder基本上没有太大的差别,只有在Multi-Head Attention部分Decoder是Musked Multi-Head Decoder
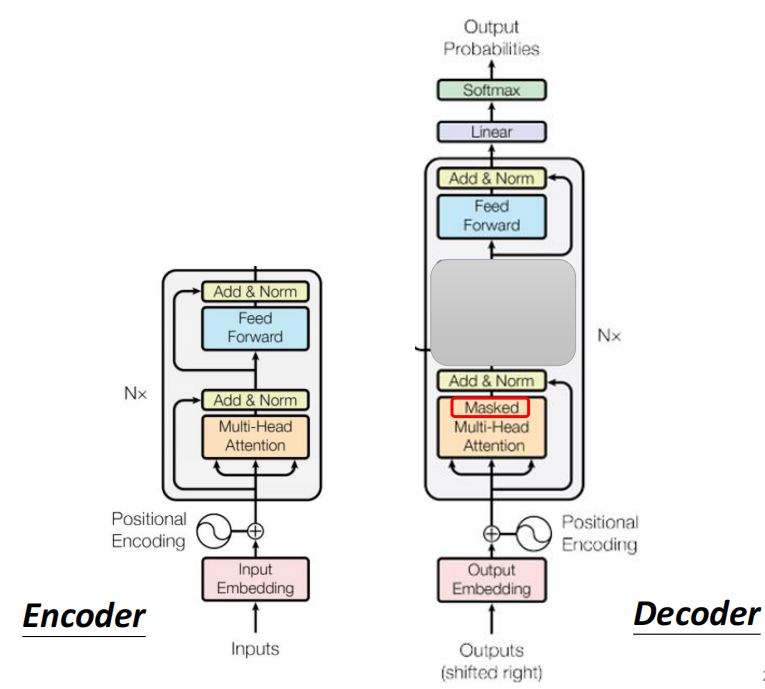
所以我们接下来就会着重讲这个Masked Multi-Head Attention和中间遮起来的部分
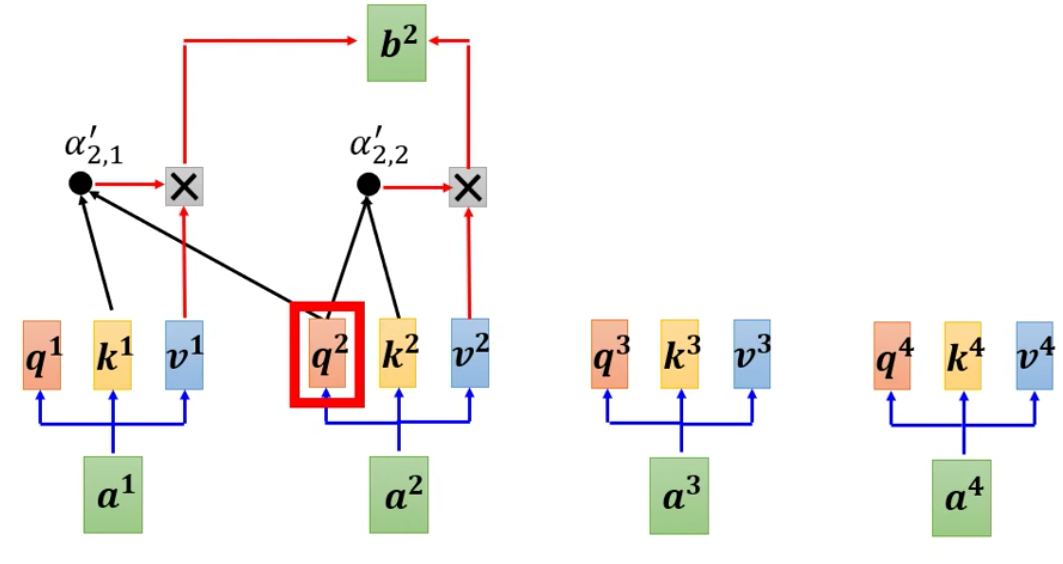
E. Masked Multi-Head Attention
Masked Multi-Head Attention是为了解决在Decode阶段的Self-Attention存在的的问题。
在Encode阶段,我们是一次性获得所有的输入的,因此我们的Self-Attention的时候是对所有的input的vector计算Attention的。

可是在Decode阶段,输出是依次获得的,为此,我们就是用Masked Multi-Head Attention。
Masked Multi-Head Attention说的就是在产生前面的输出的时候,计算Attention只看前面的input,而不考虑后面暂时未得到的input,相当于把后面的input vector mask起来。
依照上面的图来说,就是在产生第一个输出的时候,Attention只能计算第一个input,而产生第二个输出的时候,只能计算前两输入的Attention,第三个的时候看前三个,以此类推……
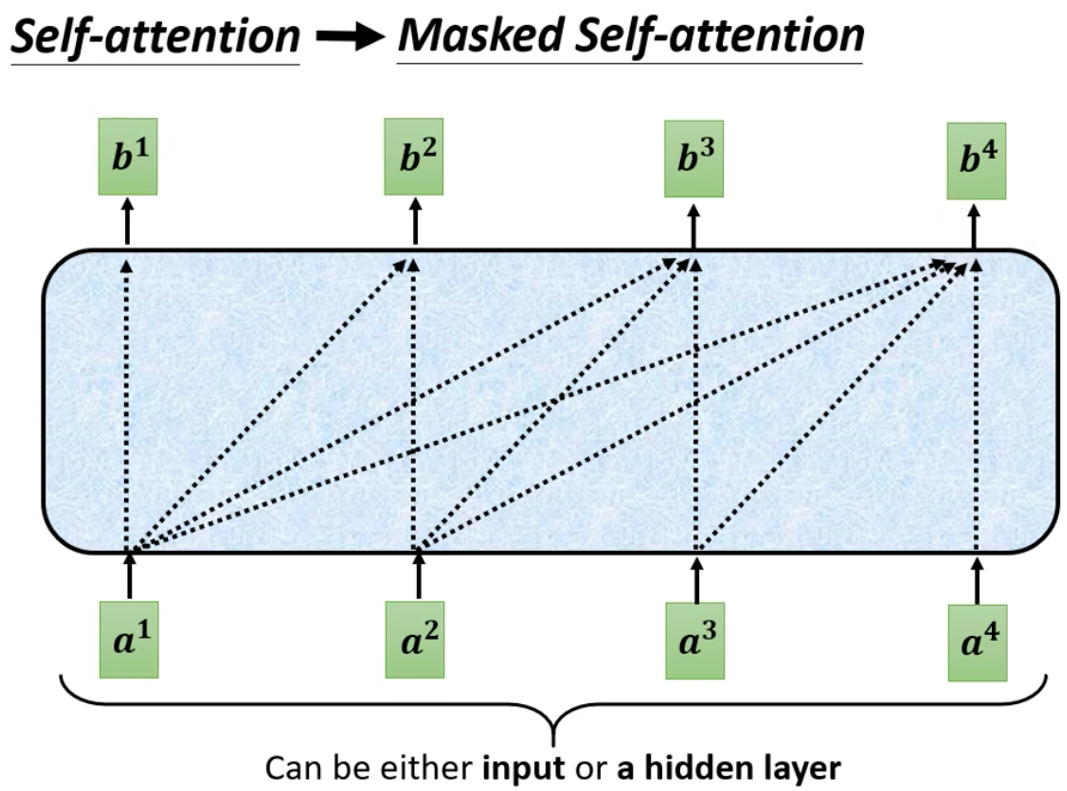
更加具体的来说,计算第二个的output的时候,只用第二个input vector的query向量乘以第一个和第二个input的key向量,得到了两个input的Attention Score。注意我们这里为了表示Mask,所以把后面两个input vector画了出来,其实在真实的计算的时候是没有后面两个input vector的。
F. AutoRegressive
AutoRegressive Decoder和Encoder在一起是一个Seq2Seq模型,输入和输出不等长,因此还有一个问题就是需要让机器自己决定需要输出多长的句子,因为按章上面讲的计算output的方式的话,机器的Output是无休止的。
因此有可能在输出了机器学习之后可能会输出惯这个字

推文接龙(Tweet Solitaire)
李宏毅老师上课讲到,在很早前的台湾的聊天室里会玩一个叫做叫做推文接龙的游戏。具体来说就是第一个人先发出来一个字,然后后面就会有人接上新的字,前后两个字构成一个词语
这个过程可以持续几个月都不会停下来。
那么如果要结束掉这个游戏的话,该怎么办呢?那么就需要有人发一个
断的消息


所以对于Decoder来说也是一样的,我们希望模型可以自己自己输出一个断,那么我们就要在Vocabulary里面加一个表示断的符号。END符号可以和开始符号相同,也可以不同,这个是无所谓的。

所以有了断之后,我们就预期模型能够自己输出一个END符号来结束输出。

5. Non-AutoRegressive Decoder
另外一种Decoder的结构就是Non-AutoRegressive的Decoder

A. Non-AutoRegressive
AutoRegressive的模型一次只产生一个输出,然后通过不断地循环迭代,最终得到所有的输出(直到输出断)。而Non-AutoRegressive则是一次吃进去一排Begin Token,然后输出整个句子
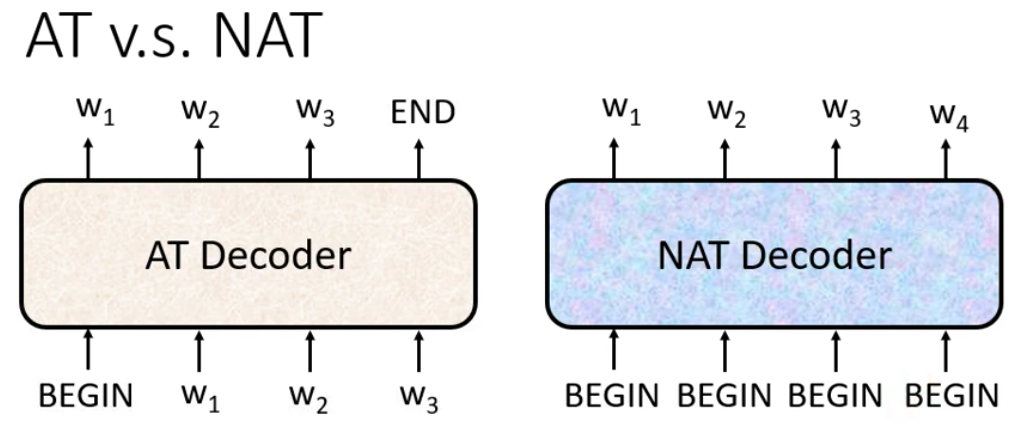
那这样的话就会有一个问题,就是我们是不知道输出有多长的,所以我们如果是NAT的话,那么该给多少个Begin的Token呢?
所以针对这个问题,就有了几种可能的解决方法:
在网络之外额外训练一个Classifier,这个Classifier吃入一排向量,然后输出一个值,这个值就是输出的句子的长度
输出一个非常长的句子,假设我们现在输出的句子的长度不会超过300,那么我们就直接把Decoder的输出设为300,然后只选用第一个END前的输出作为网络的输出

而使用Non-AutoRegressive的好处有:
- 可以并行计算,因为只需要运行一次Non-AutoRegressive的Decoder就可以获得输出,而AutoRegressive的Decoder则需要不断重复的运行
- NAT的输出的长度比较好控制
可是,NAT有一个缺点就是NAT的效果往往不如AT,如果要让NAT达到和AT的精度一样高的话,往往需要非常多的Trick。
B. More about Non-AutoRegressive
我们对NAT的讲解其实是非常简单的,但是NAT其实是目前研究的一个热点,因为人们现在都在研究为什么NAT性能比AT要差,研究如何能够对NAT进行改进,使其达到AT的性能。
例如上面我们说NAT性能一般没有AT好,其实有一个可能的问题Multi-Modality,即多模态的问题,不过关于这些我们这里都不准备讲,如果需要学习的话看一下往年李宏毅老师课程。

6. Encoder-Decoder: Cross-Attention
我们上面单独讲解了Encoder和Decoder,我们接下来讲讲Encoder和Decoder中间是如何连接的
A. Cross Attention
我们上面在将Decoder的时候只讲了Masked Multi-Head Attention、AutoRegressive和Non-AutoRegressive三个内容,我们没有将Encoder和Decoder是如何链接起来的,在前面我们其实用灰色的部分把Decoder的一部分遮住了。而这部分就是起着连接的作用。
灰色方块遮住的部分其实叫做Cross Attention。为什么称为Cross Attention呢?是因为这一个Attention的Block的输入有两个来自于Encoder,有一个来自于Decoder

我们下面详细讲解一下Cross-Attention是如何运行的。
B. Details of Cross Attention
在前面我们说道,Encoder部分最后会输出一排向量,而Decoder(我们以AutoRegressive的Decoder为例)的第一层则是Masked Multi-Head Self-Attention。Masked Multi-Head Self-Attention根据输入的个数,计算Attention Score然后给出来输出。
所以在Cross Attention前,我们就有了Encoder输出的所有向量和Decoder Masked Multi-Head Encoder输出的向量

然后我们对来Encoder的输出计算通过Key Matrix计算得到每个输出的Key Vector,然后对Decoder的输出利用Query Matrix得到Query Vector。

接下来我们用query向量和key向量计算得到三个Attention Score,然后再进行Softmax得到最终的Attention Score

类似的,我们给Encoder的输出用Value Matrix进行转换,得到Value Vector。然后乘以得到的Attention Score就得到的了Cross Attention的输出
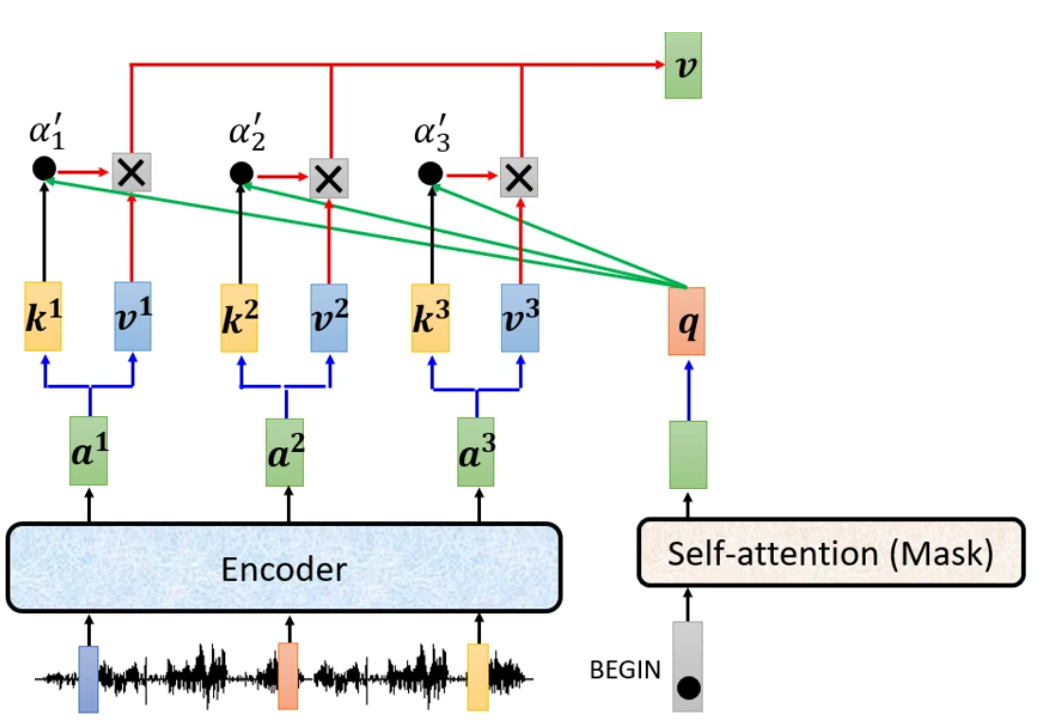
Corss Attention的输出就用于接下来的计算,例如交给FC提取局部特征。
因为我们计算Attention时候的Query来自于Encoder,而Key和Value都来自于Decoder,因此这样的计算称为Cross Attention。
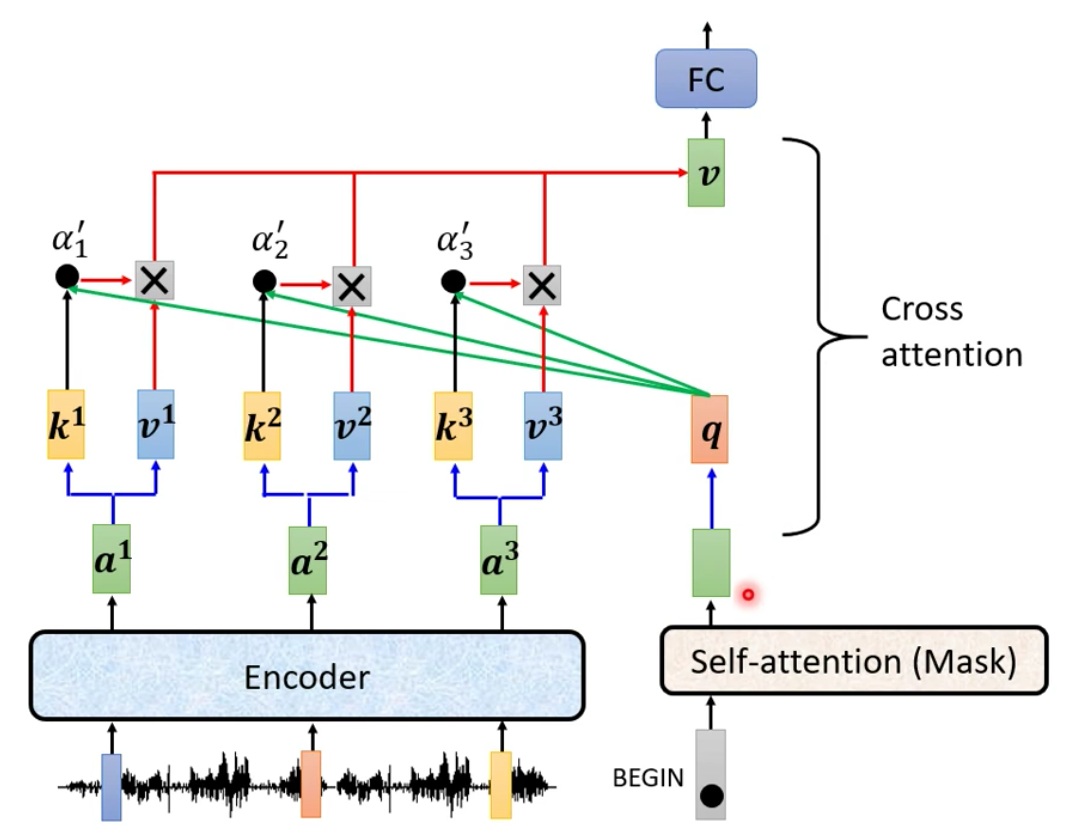
同理,我们在得到第一个输出之后,计算第二个输出的时候,我们计算Cross Attention的步骤也是一样的

C. Case Study
我们接下来讲一个真实的Cross Attention的例子。这个例子是来自于2016年的文章Listen, attend and spell: A neural network for large vocabulary conversational speech recognition:https://ieeexplore.ieee.org/document/7472621
这篇文章用Seq2Seq模型做出来了Speech Recognition问题,并且性能和当年的State-of-the-Art的结果所差无几。因此2016年这篇文章的会议现场人山人海,因为在这年之前的最好的方法使用其他的方法做的,而这篇文章cast light on Seq2Seq模型,让人们觉得Seq2Seq用在语音识别任务上是非常有前景的。
需要注意的是,Cross-Attention出现和Self-Attention并不是同步的,是先有了Cross-Attention才有了Self-Attention。所以Transformer中也不是自己提出了Cross Attention。
在2016年的这篇文章中的Seq2Seq使用了Cross Attention。其中的输入是下面的向量组,其中横轴为时间,纵轴为feature。这句话实际上是一句英文的绕口令

而这个文章Decoder部分输出的unit是一个个字母,空格和句号等标点都是用特殊的符号来表示的,相当于记为一个特殊的字母。
而模型再给出来每一个输出时候的Cross Attention的分数如下图所示,横轴是Encoder的输出,纵轴是Decoder的每个输出。而颜色越深,就表示Attention的Score越高。
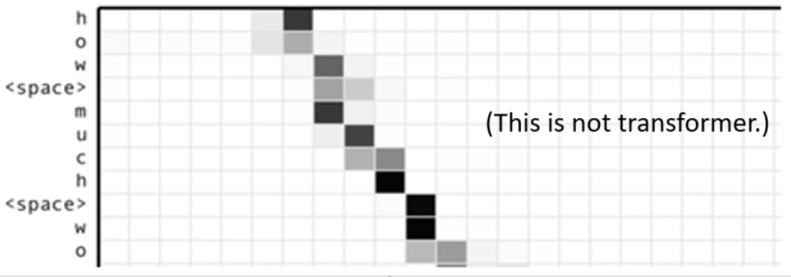
那么在Decoder输出第一个字母的时候,它关注了语音的开始部分(一开始的几毫秒是空白),然后它关注到一开始的部分的说了h,然后就输出h,然后输出第二个字母的时候,就注意力就会主键后移,接下来在输出w的时候,注意力基本上移动到了后面。接下来随着语音的继续,注意力不断地后移,直到输出完了整个句子
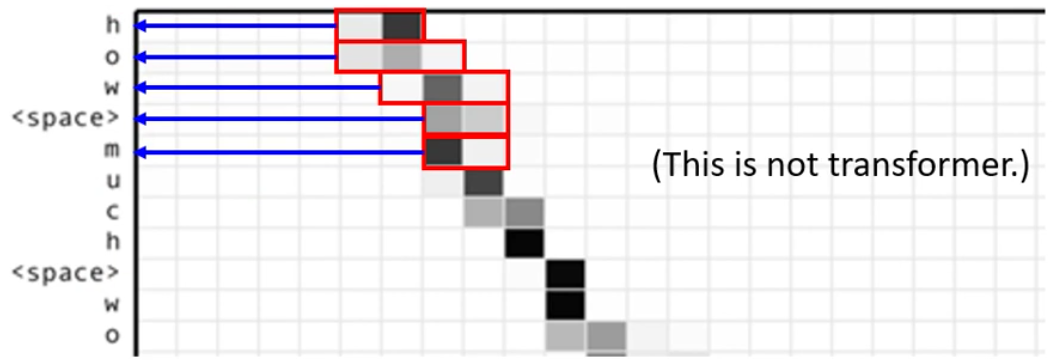
D. More about Cross Attention
其实目前Transformer也是在处在研究的过程中,人们不断地对其进行研究,以获得更深的认知。而Cross Attention也不例外,有很多的文章在研究Cross Attention。例如这篇文章
这篇文章的研究的出发点就是,在Transformer的标准论文里,计算Cross-Attention用的是Encoder最后的输出。而Encoder在Encoder的过程中其实是用了多层的Self-Attention、FC的Block堆叠。在Decode阶段也是一样的会有多个Self-Attention、FC的Block堆叠。当然,在Block中间还会加载Cross-Attention层。
所以这篇文章的角度就在于,为什么进行Cross Attention的时候是用Encoder最终输出给每一个Cross-Attention,为什么不能用Encoder的Self-Attention中间的输出来给Decoder进行Cross Attention?

所以从这个角度出发,这篇文章进行了不同的实验,把Encoder不同层的Self-Attention的输出拿来给Decoder不同层的Cross Attention进行计算

所以这个例子的目的在于告诉大家,现在DL这个领域是处于火热的研究中的,只要我们有任何的想法、new idea就可以去进行尝试。
3. Traning Transformer
到这里,我们就已经讲完了Transformer的结构,接下来我们来讲讲Transformer是如何进行训练的

1. After Inference
根据我们前面讲的,我们的模型现在的example是语音的vector和对应的句子的pair,而模型的输出就是多个Vocabulary的Distribution
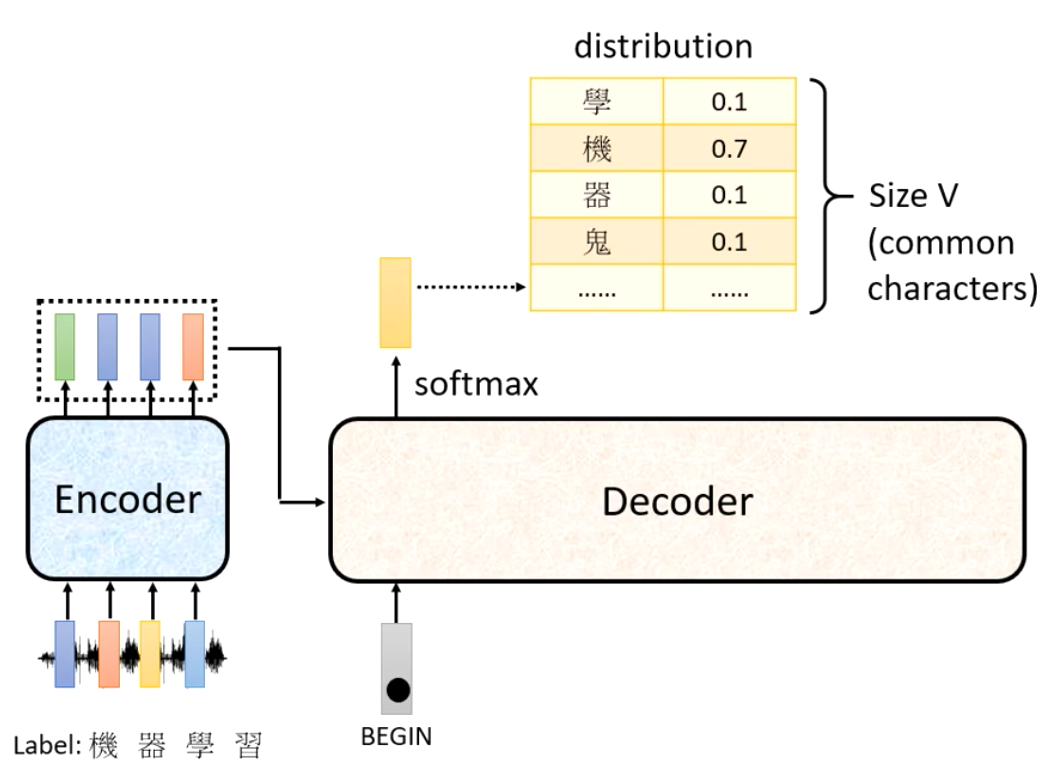
2. Single Output
现在对于一个输出的vector来说,我们的输出是一个所有class的(伪)概率向量,而target我们也可以表示成一个one-hot向量,所以对于一个输出单独来说,这个就是一个分类问题,所以我们可以用Cross-Entropy来作为损失函数
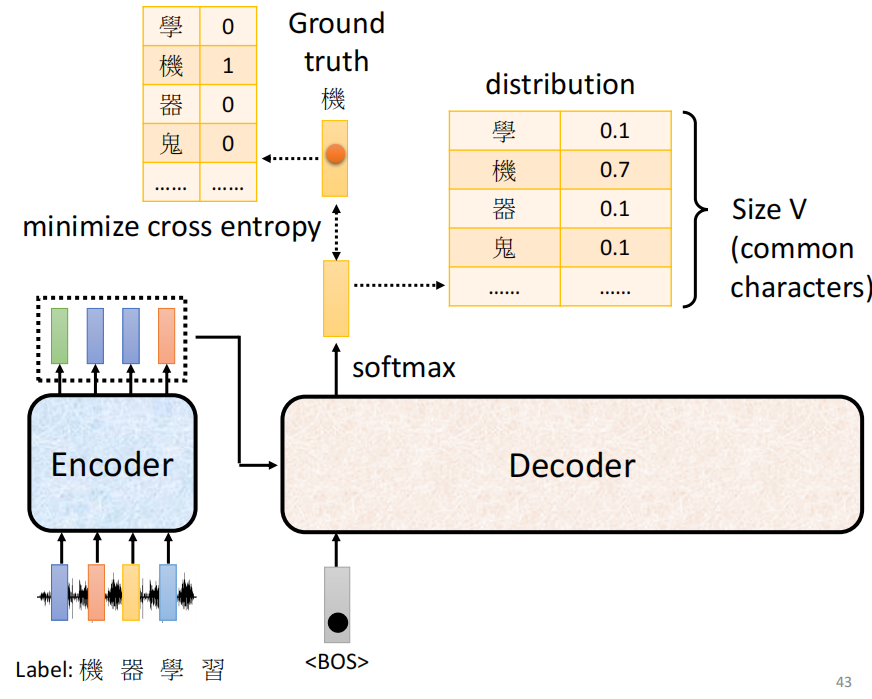
3. Multiple Output: Teacher Forcing
对于多个输出的话,我们的可以直接当做多个分类问题,然后summation所有的Cross-Entropy即可。需要注意的是,我们还需要额外加一个END,所以相比于原始的Label,我们还要再多一个Classification。
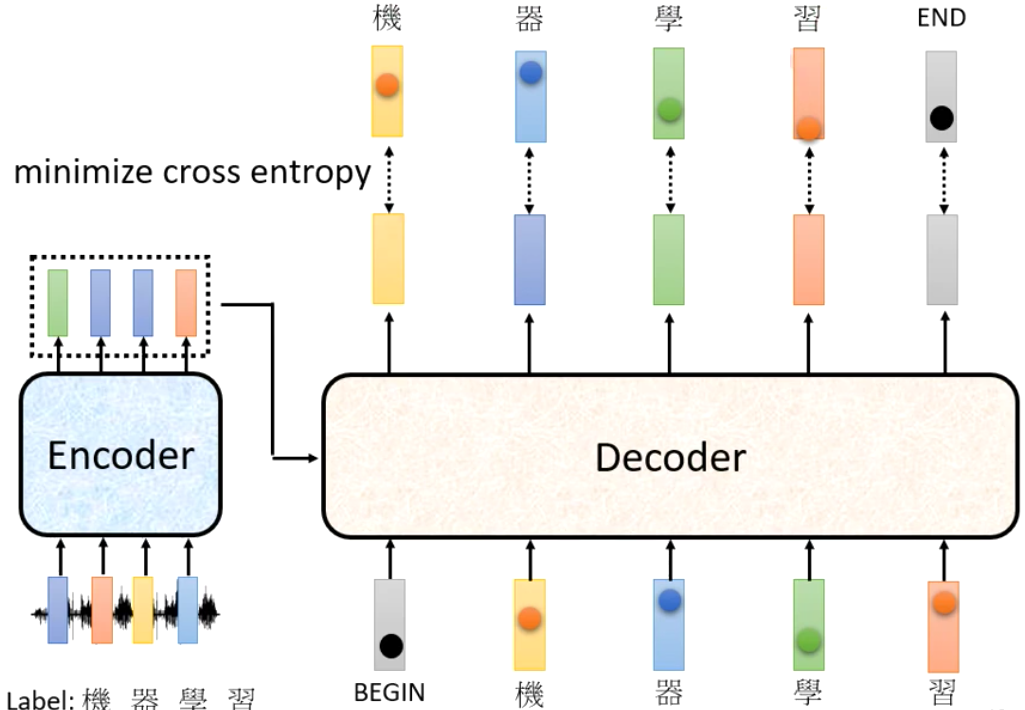
但是在训练的时候需要注意,虽然上面讲的是让Decoder用自己的输出作为输入,但是在训练阶段我们是使用的Ground Truth来作为每一次解码的input。这样的操作叫做Teacher Forcing,意思是现在有老师强迫模型在学习
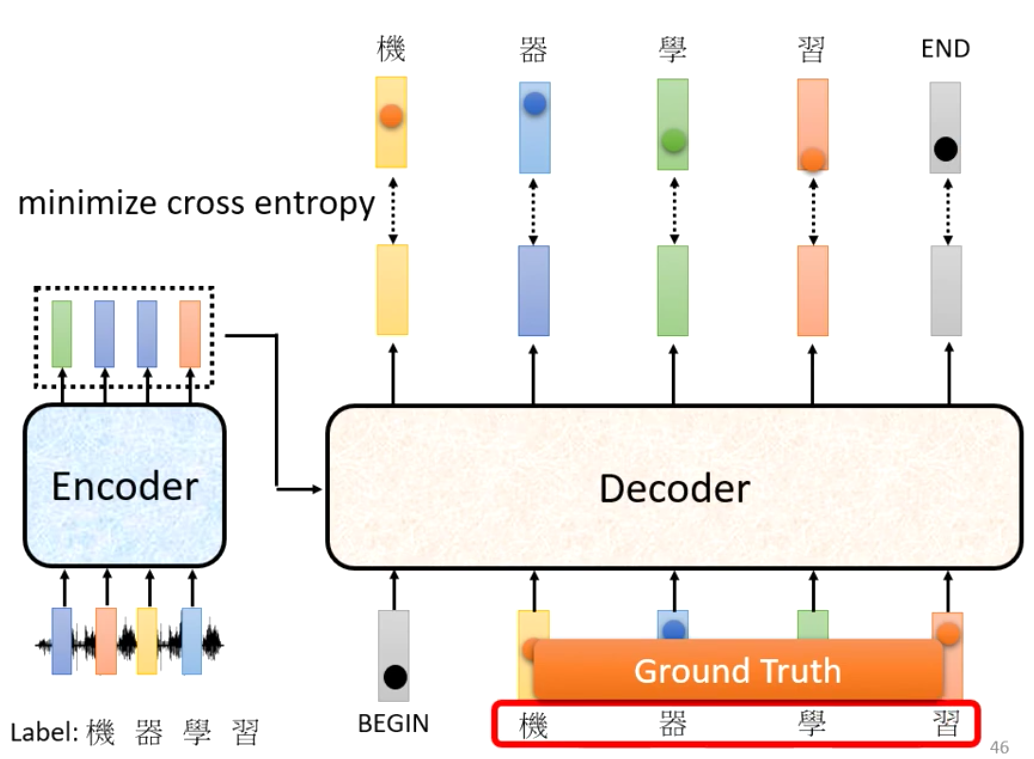
我们需要注意的是Teacher Forcing和我们的讲的Decoder得到输出的方式不一样,所以其实是会有Mismatch的问题的。即模型现在吃了正确的Label的话的确能够给出正确的输出,但是如果模型如果吃了错误的输入的话,就没有办法得到正确的输出了。
所以这个就是由于训练和测试阶段不同的设置(训练时候用了Teacher Forcing)导致的Mismatch。
关于这个问题,我们会在下面进行讲解。
4. Application variance of Seq2Seq
我们上面讲到,Seq2Seq模型其实是可以用到很多任务上的,针对不同的任务我们根据我们的Domain Knowledge设计出来一些新的模块或者Layer,将他们implement到Seq2Seq的模型上就可以实现各种各样的任务。
所以我们接下来就来讲解一下可以对Seq2Seq模型进行的改变。
1. Copy Mechanism
所谓的Copy Mechanism指的是,对于很多的Seq2Seq的Task来说,我们的output的一部分是是来自于我们的input的,有的时候甚至是完全来自于output的。
举例来说,对于一个聊天机器人来说,经常会有下面的例子

而有一些极端的任务,他们的output是完全来自于input的,例如文章摘要任务。
对于文章摘要任务来说如果我们直接让Seq2Seq生成句子的话,那么这个需要的数据量是非常恐怖的。先不说摘要任务,首先让模型生成看起来合理的句子就需要上百万的数据,更不用说还需要在生成句子的基础上完成摘要任务。
可是这个时候我们换一个角度,我们现在不需要让模型自己学会输出一个句子,而是学会如何从input中copy得到output,那么这样的话,我们需要的数据量就会小很多,而且性能也会非常好。

最早提出Copy Mechanism的文章是Pointer Network,这篇文章老师过去有讲过,所以链接直接放在这里了。此外,还有另外的一篇讲Copy Mechanism的文章,Reference放在了下面。

2. Guided Attention
神经网络是一个黑盒子,所以我们训练完之后,我们其实是不知道模型在处理输入的Vector Set中每一个input vector的时候的注意力以及输入的注意力间变化的。但是我们有的时候在有一些情况下,或者说在一些任务中,我们其实是知道我们的模型的注意力的变化的。
举例来说,在进行语音合成的时候,我们输入是文本,输出是一段语音(MP3)。那么我们再输入每个字的词向量的时候,我们知道模型的注意力应该关注当前的文字和前后两个文字,并且逐渐后移。
我们用红色的线来表示模型的注意力,越高表示Attention Score越大。那么TTS任务的Attention的变化应该如下

可是我们实际上合成的时候却有问题,例如下面,前面三个发财都是没有问题的,可是合成最后一个发财的时候,只能听到财而没有听到发

那么造成这个问题可能的就是模型的Attention在合成发这个字的时候,全都集中到财这个字上面去了,所以造成的问题就是语音合成有问题。
更进一步,在我们知道模型合成语音的Attention应该是什么样的情况下。模型的Attention如果是错乱的话,那么就会存在问题。例如合成第一个字的时候注意力都在后面的句子上,而合成第二个字的时候注意力没有关注后面,合成第三个字的时候注意力又在首尾。
关于Guided Attention的话,想要去学习的话去Google一下Location Aware Attention
3. Beam Search
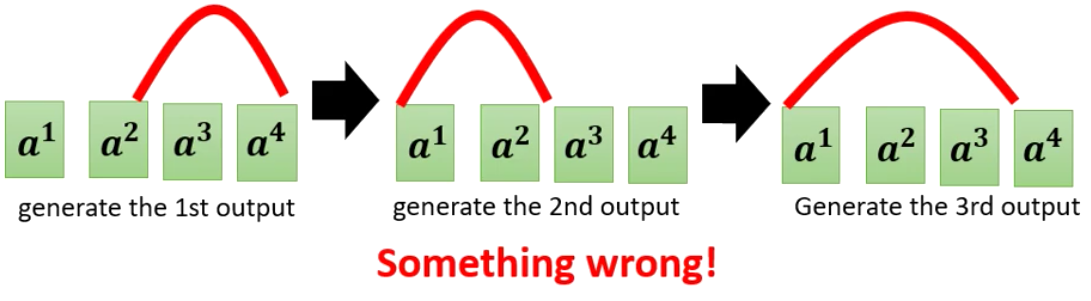
Seq2Seq模型在Decode的时候,是先输出第一个字,然后输出第二个字,然后以此类推,直到输出断。而在每一次输出的时候,我们计算的都是argmax,所以我们每一次生成结果的时候都类似搜索树的展开。
假设现在世界上某种语言只有两个字,那么我们Decoder解码三次就可以展开为下面的搜索树

而每一次输出概率向量中的每一个维度都是某个class的概率,我们又是取得最大概率的类别作为输出,所以我们Decode得到输出的过程类似于贪心算法。
然而贪心的问题就是我们生成输出Sequence并不是具有最优子结构性质的问题,因此贪心其实是有问题的,即我们每次选择概率最大的作为分类的结果其实是有问题的,每个字的概率最大并不意味着输出的整个句子的概率最大

考虑到真实的情况,每一次输出其实都是有4000个可能的,因此搜索树是一个4000叉树,暴力搜索根本没有办法解决。
所以这个时候,就有一个叫做Beam Search的算法,能够有效的进行搜索,最终得到approximate的最优结果。

不过需要注意的是,Beam Search这个方法对于一些任务不一定有用
4. Sampling: adding noise
再有一些任务中Beam Search的效果其实是不好的,例如下面的文本补全问题。我们用Beam Search的话,就会发现得到的文本全部都是一样的,因为这些文本的得分是最高的。

在这个时候,得分不是最高的输出看起来却是比较合理的,因此就启发我们,有一些任务的满足Metric的最优解并不一定是我们人类理解的最优解。
为什么会出现这样的问题呢?其实问题发生的根本,就在于这类任务的评判标准不是唯一的。就相对于艺术品的评价,不同的人认为美的标准不一样,有的人可能喜欢毕加索的画、有的人喜欢莫奈的印象画、还有的人喜欢前卫的画……而这些人对美的评判标准不一样,我们看不懂或者觉着这幅画不好看,并不能说别人也觉得这幅画不好看。而评判标准不唯一,往往对应的就是创造的问题。因为创造出来的作品的评判标准并不是唯一的。
所以上面的文本生成问题其实就是有那么一点点创造的任务,当然接下来就会开始讲生成任务。
针对创造任务,我们其实为其引入一些random的因素之后得到的表现其实更好,比较明确的任务,beam search的效果会更好。具体如何添加杂讯,则参考文章The Curious Case of Neural Text Degeneration:https://arxiv.org/abs/1904.09751
比如对于TTS任务来说,如果不加入一些杂讯的话,那么合成得到的声音类似于机关枪,很难听,可是加入一些杂讯之后,声音会更加的拟人。
所以这就对应了一个谚语,美存在于不完美之中。

5. Reinforcement Learning
我们上面说道,在Seq2Seq的时候我们的损失函数就是summation over all cross-entropy。然而这样做的话,我们最后优化得到的解有可能不是最优的解。因为我们的目标是一整句话,而非一个字,所以理论上来说,我们的损失函数应该是吃进入output的句子和target的句子然后给出来输出。
我们用cross-entropy的相加,其实是把句子视为单独的字的组合,所以这样优化得到的结果不一定是最佳的。例如对于翻译来说,翻译的句子可以不同,只需要意思是一样的即可。因此,我们应该要求计算的是机器翻译的结果和人工翻译的结果的相似性,而非让机器模仿label。所以我们计算的应该是输出句子和label的blue score而非cross-entropy
Blue Score
BLEU的全名为:bilingual evaluation understudy,即:双语互译质量评估辅助工具。它是用来评估机器翻译质量的工具。BLEU的设计思想:机器翻译结果越接近专业人工翻译的结果,则越好。BLEU算法实际上就是在判断两个句子的相似程度。想知道一个句子翻译前后的表示是否意思一致,直接的办法是拿这个句子的标准人工翻译与机器翻译的结果作比较,如果它们是很相似的,说明我的翻译很成功。
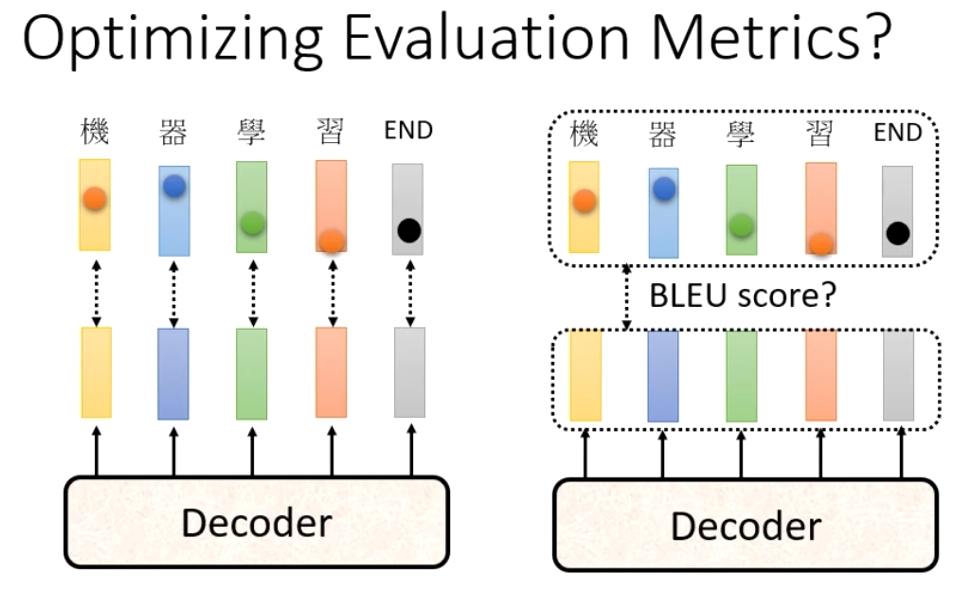
可是使用Blue score有一个问题,就是blue score的计算过程是不可微分的,所以没法用Gradient Descent进行优化得到最优的参数。
所以这个时候怎么办呢?这个时候有一个口诀,就是遇事不决用RL。即把无法优化的问题当做是RL问题,然后来硬Train一发。
具体过程是,把Loss Function当做是reward,Model当做是Agent,然后把整个问题当做RL问题来硬做。这样确实可以做,不过不推荐这样做。因为RL训练的成本太大了。具体的方法下面的文章里有写

6. Exposure bias: Scheduled Sampling
我们前面再讲训练decoder的时候,用了Teacher Forcing。而Teacher Forcing会导致和真实的inference的时候出现mismatch现象。因此,为了解决这个问题,我们就可以用Scheduled Sampling,即在训练阶段,人为的给Decoder一些错误。
Scheduled Sampling在Seq2Seq模型出现的时候就已经有了,并不是在Transformer出现之后就有了。但是需要专注于,Scheduled Sampling会伤害NAT的平行化能力




