本文是李宏毅Machine Learning 2021 Spring 第四节课的笔记,本节课主要讲解了深度学习训练过程中训练失败的一些情况以及对应的处理方法。

李宏毅ML2021-Spring-4: When Training Fails
在前一节课中,我们首先介绍了ML的Framework,具体来说我们分两步介绍了ML Framework:
- 我们首先定义,ML Framework中的第一步是数据集准备
- 数据集中一部分用于训练我们的模型,称为训练集
- 数据集中剩下的一部分用于测试我们的模型,称为测试集
- 然后我们介绍了ML Framework中的第二步是模型训练和测试
- 首先用我们的训练集训练我们的模型
- 然后将训练好的模型在测试集上测试,来看看我们模型的效果
如果我们的模型在测试集上的表现也非常不错的话,那么我们其实就可以部署我们的模型了。
接下来我们由介绍了深度学习训练查错的指导,具体来说:
- 当出错时候首先检查模型在训练集合上的loss
- 如果训练集上的loss比较大,那么:
- 有可能是model bias,即模型的能力太弱,导致模型学不起来,这个时候可以增加模型的复杂程度,即引入更多的可学习的参数。形象的表示:最优的模型不在我们模型的表示范围内。大海捞针——海里没有针
- 还有可能是我们的Optimization出了问题,导致没有对模型进行Optimization,这个时候就要更改Optimization的方法,使用其他的优化方法或者对当前优化方法进行改进。形象的表示:最优的模型在我们的模型的表示范围内,但是我们找不到它。大海捞针——针在海里,我们找不到
- 如果在训练集上的loss比较小,那么:
- 判断模型在测试集上的表现
- 如果模型在测试集上的loss比较大,那么:
- 可能是Overfitting,模型过度的拟合了训练数据。这个时候方法一是收集更多的数据,而方法二则是对模型进行正则化,即要么限制模型的学习能力,要么给模型添加惩罚项
- 还有可能是Mismatch,即模型学习到的训练集的分布和测试集的分布不同,针对Mismatch的方法在后面会专门讲解
- 如果模型在测试集上的loss比较小,Happy Ending🎉
- 如果模型在测试集上的loss比较大,那么:
- 判断模型在测试集上的表现
- 如果训练集上的loss比较大,那么:
以上就是上节课讲的内容的一个复习。
然而在上节课,我们其实有两个地方没有展开讲,第一个就是Optimization失败的时候,我们没有讲如何提升Optimization的效果,即没有讲怎么样对Optimization的方法进行提高。第二个就是对于Mismatch,我们也没有讲处理方法。
其中,Mismatch将在后面讲解,本节课将讲解Optimization失败的几种原因及其处理方法。
一、原因一:Critical Point
网络更新失败的第一种原因就是由于Critical Point。下面就将详细讲解Critical Point,然后在其基础上讲解处理Critical Pioint的办法以及和Critical Point有关的Batch Size的问题
1. What happened when Optimization failed?
我们首先讲解Optimization失败的时候到底发生了什么,然后我们在从中总结规律,为后续的处理方法做好准备。
A. Differential of parameters is 0
我们说Optimization失败,通常是在训练阶段不管我们怎样的训练,模型在训练集上的表现一直都很差。
而就真实的情况而言,其实在训练集上的loss很大有两种表现:
- 第一种是模型有在学习,但是最终学了一会学不动了,而且此时表现比较差
- 第二种是模型没有在学习
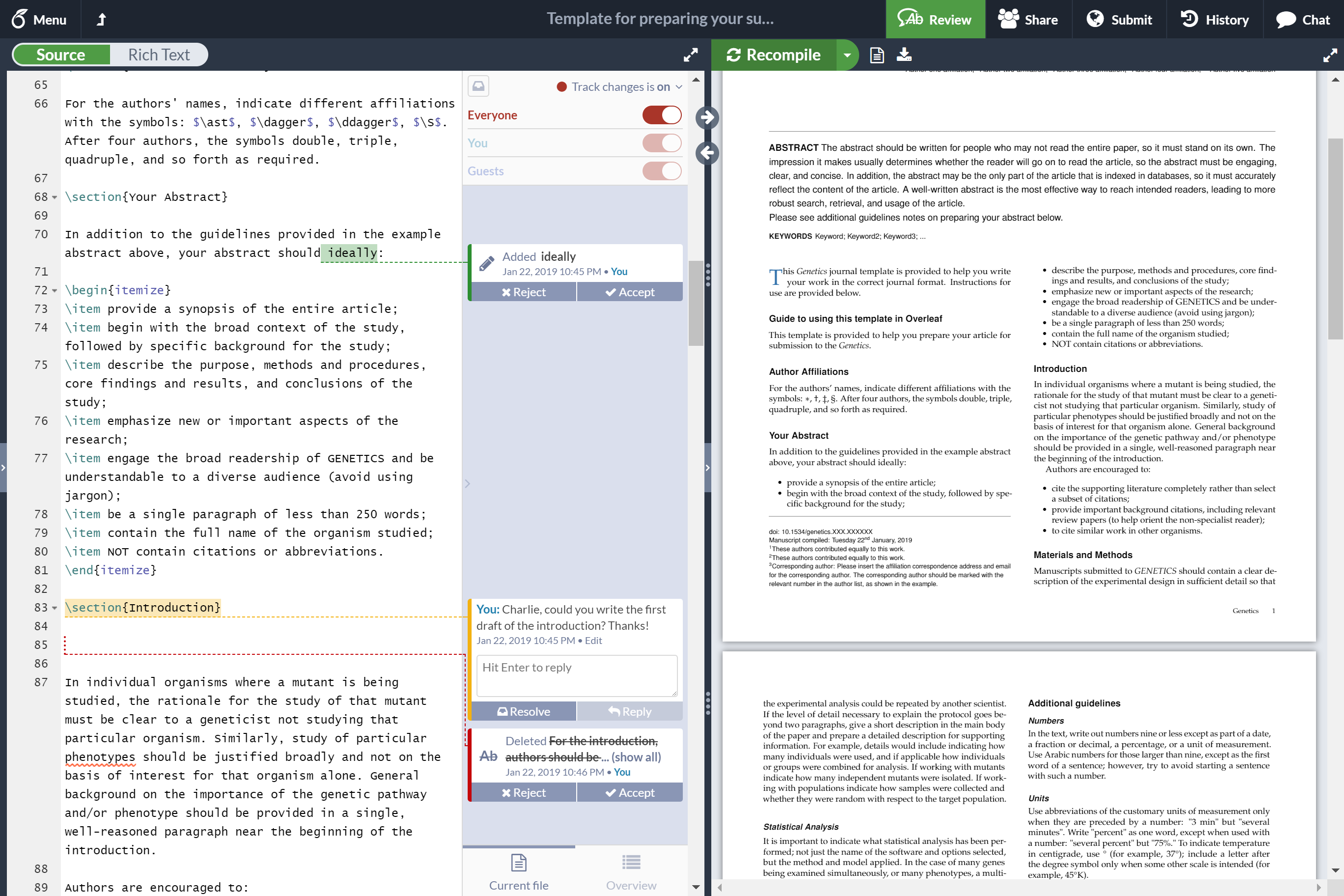
而根据我们前面讲过的Gradient Descent这个优化算法,我们只要能够根据loss算出来Gradient那么就一定够提升模型的表现。而想上面这两种情况,模型的loss最终收敛(稳定)到了一个值附近。这也就意味着我们的梯度中的大部分都成了0。
为什么我们认为大部分都成了0呢?其实我们反过来想,如果梯度全都不是0,那么我们的模型的表现一定还有所提升。如果全部都是0,那么我们模型的表现应该是一条直线。只有大部分是0而少部分不是0,我们的模型得到的梯度只能在几个方向上指导模型去梯度下降、探索Loss Surface。而在这几个方向上的loss其实都差不多,因此最终表现在图上就是模型在震荡。
因此,导致上面模型最终收敛的原因就是loss对模型中参数的微分是0(后面我们说的是0往往指近似为0)
B. What may cause this?
由于微分是根据loss对参数求微分得到,因此我们在loss space中可视化出来了话,有两种可能导致梯度为0:
- 陷入了Local Minima
- 陷入了Saddle Point
而我们统称Local Minima和Saddle Point为Critical Point

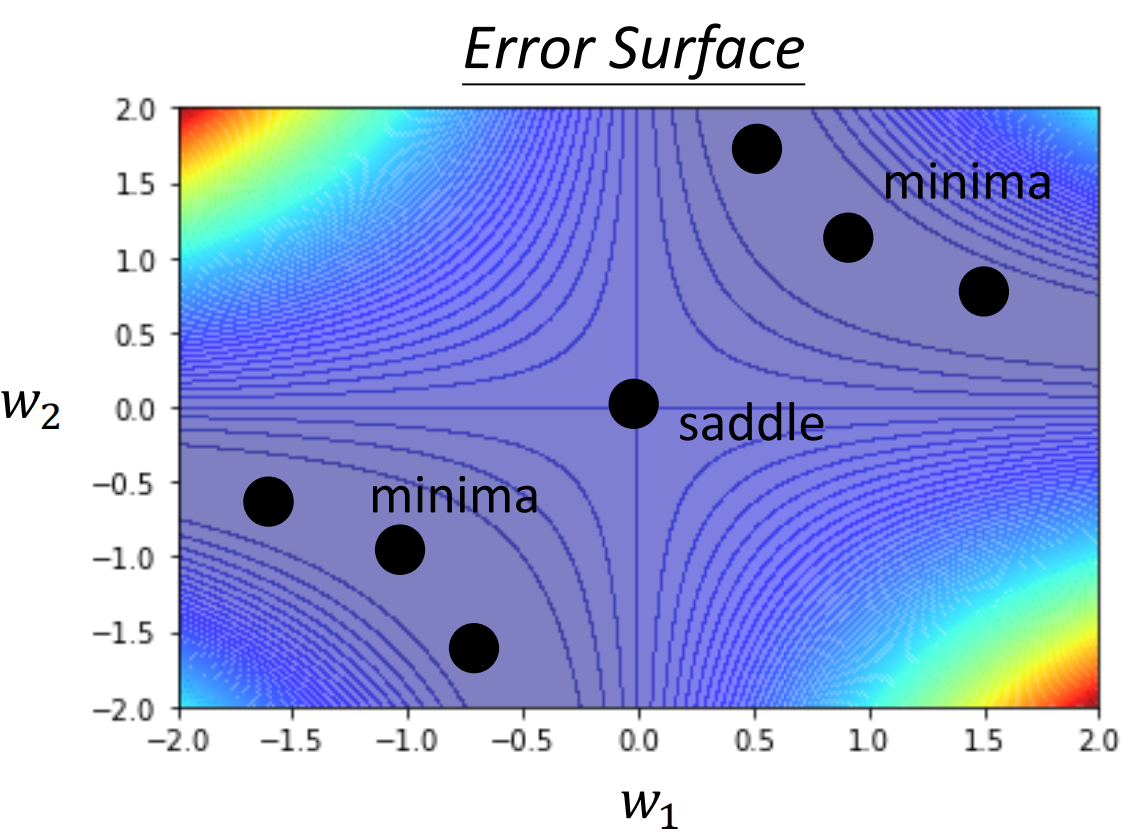
C. Local minima or saddle point?
那么我们在发现模型陷入到了Critical Point的时候,我们其实很有必要去知道模型到底是陷入了Local Minima还是Saddle Point。因为两者最重要的一个差别就是Local Minima意味着周围没有新的路了,而Saddle Point意味着其实模型的loss还可以继续降低

而对Local Minima和Saddle Point的判断其实需要一些数学的知识
泰勒定理告诉我们其实可以用一个多项式来在某一个区间内以一定的精度来逼近某个函数。而在全部范围(定义域)内逼近这个函数则需要无穷多项。
因此,对于损失函数$L=L(\theta)$,我们可以用一个无穷多项的多项式函数来进行逼近。但是我们其实不需要损失函数在全部范围内的值,因为我们现在的目的在于判断模型当前收敛到的参数的这个点到底是Local Minima 还是 Saddle Point。而要判断一个点是不是Saddle Point,我们其实只需要看这个点周围的值是否都比这个值大即可
因此我们其实只需要损失函数在$\theta’$这个值附近的值即可。因此对于泰勒定理来说,我们只需要在$\theta’$的一个邻域内,在一定程度上逼近$L$即可。
因此我们在$\theta’$这个地方展开第二项即可,即
其中,$g$是$L$对$\theta$的在$\theta’$处的梯度,每个分量都是$L$对$\theta$中某个分量的偏导,即
而H则是Hessian Matrix,可以理解为二阶导,H中的每个元素都是混合偏导数,即

而我们现在在Critical Point的话,就意味着$L$对$\theta$的梯度为0,即上面的式子中的第二项没了,那么我们的二阶泰勒展开式就只有两项了
那么这个时候,我们就可以用$H$来估计$L(\theta’)$周围的值,有了这些值之后,我们就可以判断某个点周围的地貌,从而判断某个点周围是不是Saddle Point了

当然,对这个点周围的值进行穷举来获得Critical Point周围的地貌所需要的计算量太大了,因此不现实。我们下面从数学上来用$H$判断Critical Point是Saddle Point还是Local Minima
首先为了符号记录的方便,我们记
则有
那么如果对于所有的$v$,均有
那就意味着
那么此时,$\theta’$就是Local Minima
反之,若
则$\theta’$为Local Maxima
而如果有时候$v^THv<0$而有时候$v^THv>0$,这就意味着这个点是Saddle Point。
而要实现全部大于0或者全部小于0,我们只需要$L$对$\theta$的Hessian Matrix是正定或者负定或者不定的。如果是正定的话,那么所有的特征值全都是正的,负定的话全部都是负的,不定的话则有正也有负。
对应的我们只需要计算Hessian Matrix矩阵的Eigen Values即可。

D. Example
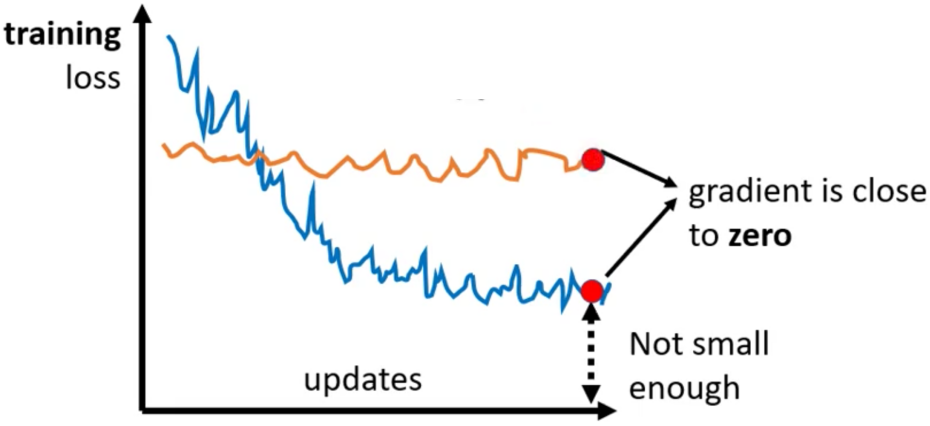
下面我们真实的给出来一个Loss Function的曲面,然后来判断这个Surface上的Loss的情况。不过为了能够把Loss Surface绘制出来,我们的网络必须要简单,最多只能有两个参数。我们选下面这样的网络
训练集只有一个example,输入是一个数字,label也是一个数字,激活函数是$y=x$线性函数

那么,由于我们的Loss Function是$L=L(\theta)$中$\theta$只有两个参数(我们连Bias都没有加),因此我们就可以绘制出来Loss Surface
在此基础上我们找出来其中梯度为0的点,最后所有Critical Point和Error Surface的图如下
接下来,为了搞清楚这些Critical Point是Local Minia 还是 Saddle Point,我们需要求一下Hessian Matrix。因为这里我们的Loss Function我们其实是可以写出来的,即
而上式中的example是$(x,\hat y)$,而由于我们的example只有一个$(1,1)$,因此,Loss Function为
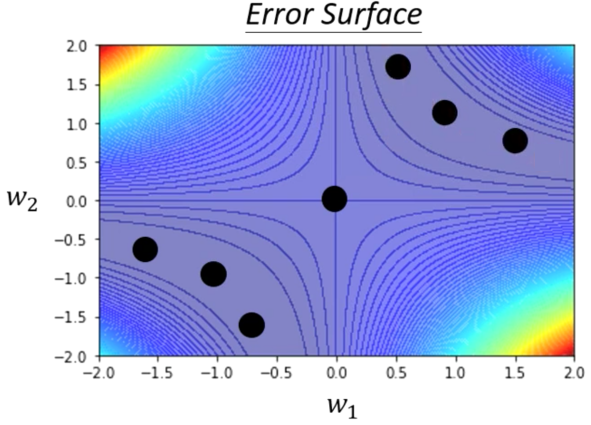
那么我们写下来$L(\theta)$对$w_1$和$w_2$写出来他们的梯度
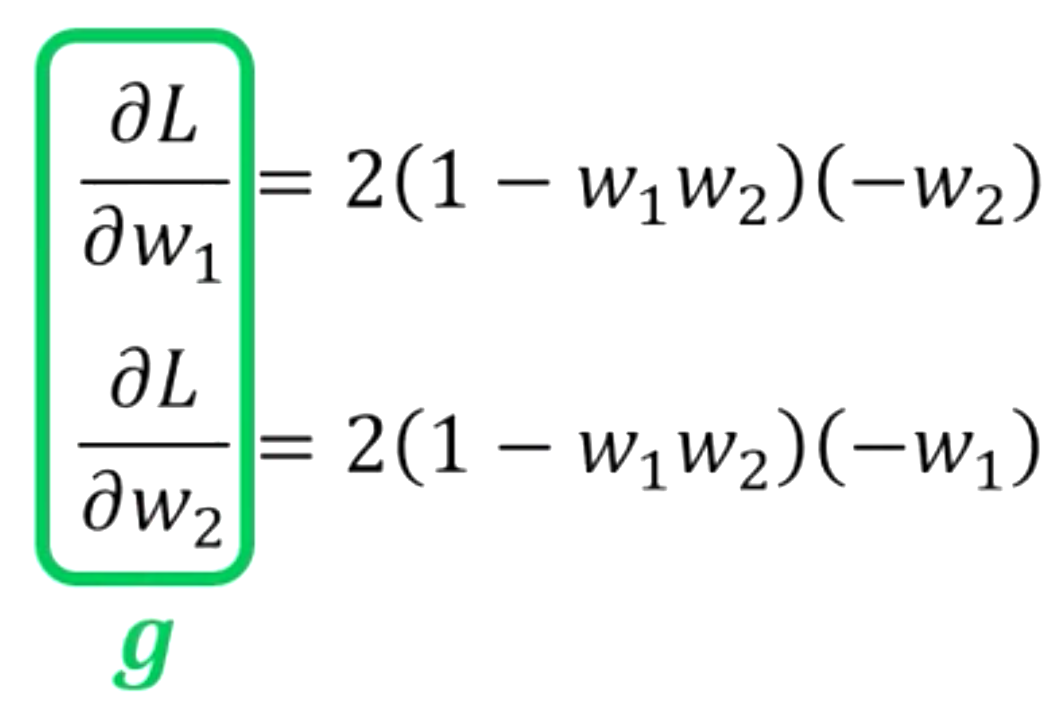
然后我们再算出来二阶导数,就可以得到Hessian Matrix

然后我们把$(w_1,w_2)$的值带进去,就可以计算得到他的Hessian Matrix。然后在Hessian Matrix的基础上,计算Eigen Value

那么由于特征值有正有负,因此$(0,0)$这个点就是一个Saddle Point。同理,我们计算完剩下的点,就可以得到这些Critical Point的类别了
其实Hessian Matrix其实不仅能够帮助我们去判断一个Critical Point是Saddle Point还是Local Minia,他还可以帮助我们去进一步指导网络的下降。
我们如果把$v$换成$u$,那么在损失函数中第二项的正负其实就由Eigen Value决定的

所有这个时候,我们让参数沿着负特征值对应的特征向量$u$的方向前进即可

所以利用Hessian,我们就可以逃离中间的原点。

但是其实在现实中很少会用Hessian来帮助我们逃离Saddle Point,因为计算Hessian的话,要算二次微分,并且要算$len(\theta)^2$个二阶导数,而考虑到在真实的情景中,$\theta$中包含的参数的数列往往有几万个,计算量实在是太大了,即便是只算一次,开销都是无法接受的。
这还不包括计算特征向量的开销等等
上面讲的这些内容呢,其实是为了让我们明白,卡在Saddle Point的时候还是有办法的,只不过用的可能不是我们这里介绍的方法+
E. Local Minima v.s. Saddle Point: which one is more?
上面我们介绍了Local Minima和Saddle Point,然后介绍了如何利用Hessian来逃离Saddle Point,其数学原理就是Taylor Series Approximation。
所以对于我们来说,Saddle Point不可怕,真正可怕的Local Minima。那么我们不禁要问, 在真实的情况中,我们的网络最终是在Local Minia还是Saddle Point?或者说有多少的比例,我们最后的网络是应为Local Minima导致无法进行训练的?
所以接下来,我们就要讲解这两个问题
在讲之前,我们先讲一个三体里的故事
君士坦丁堡的故事
在公元1543年的时候,土耳其人进攻君士坦丁堡。那个时候君士坦丁堡本来是东罗马帝国的城堡,可是被土耳其奥斯曼帝国进攻,最后君士坦丁堡沦陷,东罗马帝国灭网
这个故事就是,在土耳其人进攻的时候,君士坦丁堡的皇帝,君士坦丁一世不知道该怎么样抵挡土耳其人的进攻。
这个时候,就有人向君士坦丁一世推荐了魔法师地奥伦纳,地奥伦纳说自己有万军从中取敌军将领首级的能力。那么大家肯定就不相信,大家纷纷都要求地奥伦纳展示一下自己的能力。
于是地奥伦纳就拿出了一个圣杯。
大家看到这个圣杯纷纷都大惊失色,因为这个圣杯本来是存放在圣索菲亚大教堂的地下室里的,而且是放在一个密封的石棺里的,没有人能够打开他。
地奥伦纳就说自己并不止是把圣杯拿出来了,还放了一串新鲜的葡萄进去。于是君士坦丁一世就命人打开了石棺,发现石棺里真的有一串葡萄。
那么为什么地奥伦纳真的可以拿到石棺中的圣杯、放葡萄进去呢?
其实是因为,在我们看来封闭的石棺只是在三维上是封闭的,而在高维空间,例如四位空间中,它不一定是封闭的。而地奥伦纳就可以进出四维空间。




上面这个故事的意义其实在于,三维空间没有路可以走的地方在高维空间中可能会有路能够进去。那么Error Surface会不会也是这样?
这样的猜想是合理的,因为我们很轻松就可以给出一个例子。在一维中我们看来的Local Minima在二维中可能只是一个Saddle Point,在一维中我们没有路径能够达到Global Minia但是在二维中我们却依然有路。
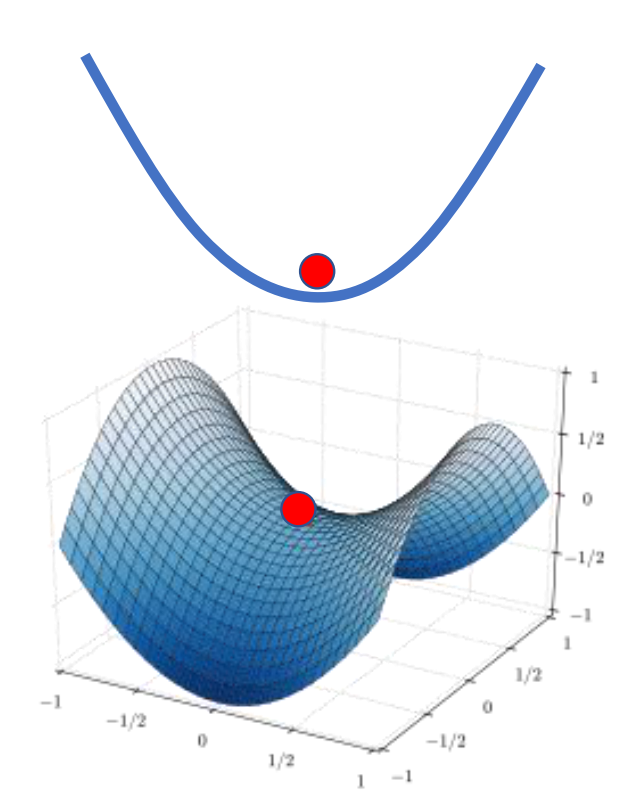
所以,我们依次类推,而一个崎岖的二维平面上的Local Minia有没有可能是高维平面上的Saddle Point?

那么我们在真实的网络训练中,参数是百万千万的,那么我们其实就会想,这么多的参数,会不会真真的Local Minima会比较稀少?
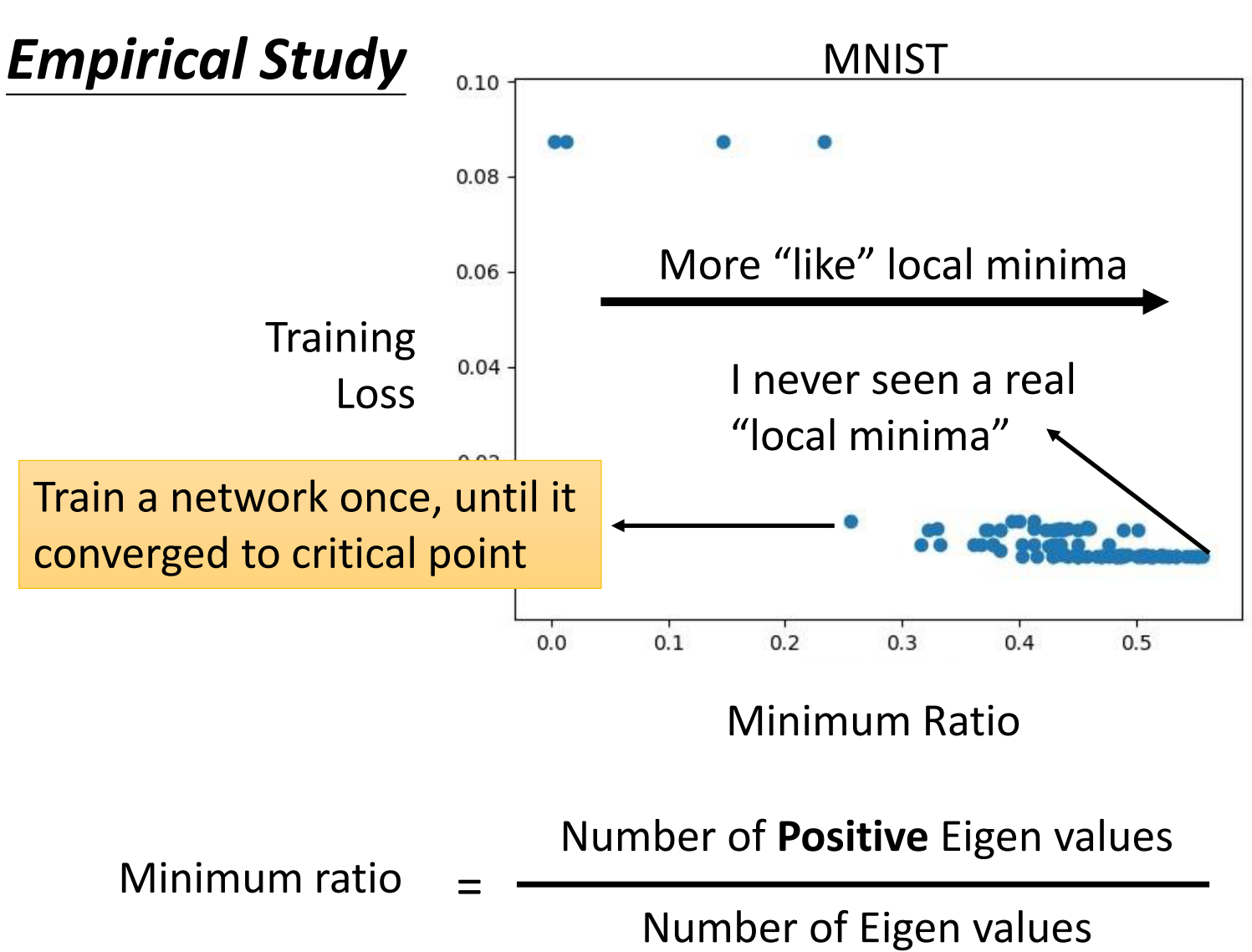
那么我们自己做实验的结果其实也支持这个假说。我们自己训练一个网络,然后等网络收敛。这个时候我们来看一下此时网络的Hessian Matrix,看看到底是不是Local Minia。

所以说,上面的图片中,每一个点就表示网络训练一次,直到网络停在了Critical Point

上面这个图的纵轴表示最终收敛的时候的Training Loss而横轴表示Minimum Ratio。Minia Ratio的定义如下图,我们计算Hessian Matrix的所有特征值,然后用其中正特征值的数量除以所有特征值的数量。
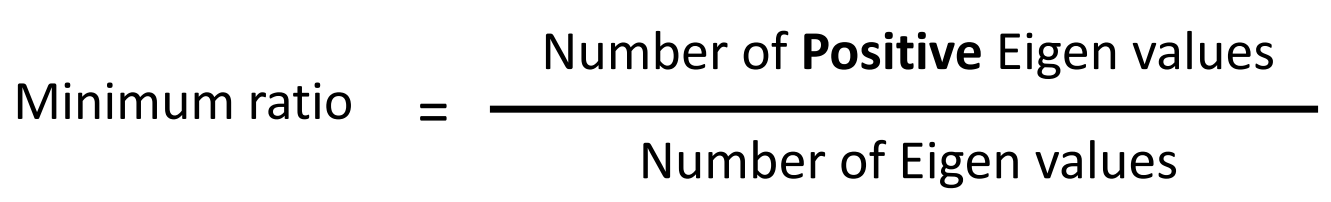
因此,横轴实际上反应了Critical Point接近Local Minima的程度,越向右越接近Local Minima。可是在实践中,从来没有见过所有的特征值都是正的的情况,最多只有接近0.6,即60%的Eigen Value是正的。
因此从经验上来看,我们训练不下去了往往不是因为到了Local Minia,而是卡在了Saddle Point
2. Batch
我们在前面第二节课:Introduction to ML的时候讲解了ML的Framework,其实就三步:
- 根据我们对任务的认识,设计一个含参的函数
- 根据我们对任务的认识,设计一个用于衡量参数表现好坏的损失函数
- 接下来通过方法(对于神经网络而言就是Gradient Descent)对函数的参数进行优化,以实现在损失函数上表现良好的参数
其中,对于参数进行优化的时候,我们说了我们在真真通过Gradient Descent的时候,我们不是计算了所有的example的loss再求Gradient,而是只看一部分example,然后求出来其梯度,然后进行计算,求出Gradient。
所以我们其实是把数据分成不同个Batch,然后每个Batch进行计算的

我们下面就将对Batch进行一下讨论,然后给出通过Batch来减少由于Gradient下降的方式导致Optimization失败的解决方法
A. Small Batch v.s. Large Batch
我们现在假设我们的训练集只有20个example(N=20)。然后我们分别通过大Batch和小Batch两种方式计算一个epoch。
- 对于大Batch,我们取Batch Size为20,即Full Batch
- 对于小Batch,我们取Batch Size为1
然后我们对这两种Batch都计算一遍整个Training Set,得到的结果如下
注意,由于我们是每个Batch之后都会计算一个Gradient然后下降,所以Batch Size为1的时候为了看完整个Training Set,其实已经梯度下降了20次了
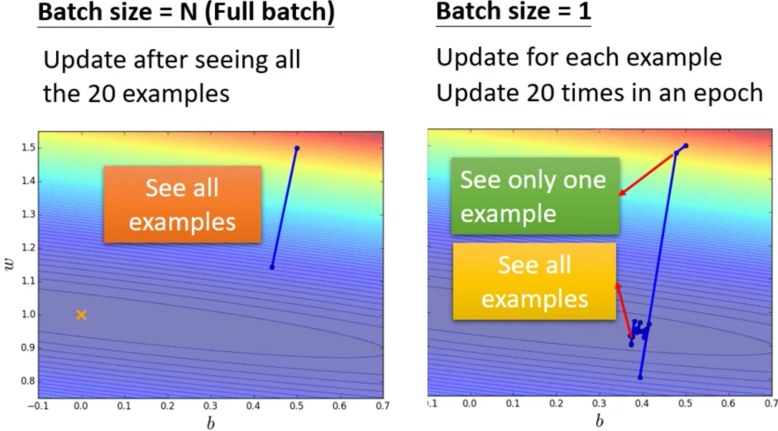
那么我们其实可以看到,对于Large Batch而言,其非常的稳定,而对于Small Batch而言,他的Gradient非常不稳定,因此我们可以看到右边的Small Batch的Gradient指导下的参数的更新路径,非常的曲折。
我们如果从Gradient Update的角度来进行比喻,Large Batch Size就是冷却时间比较长,但是威力比较大的技能,而Small Batch Size就是冷却时间比较短,但是威力比较小的技能。

B. Is larger really slower?
我们上面很自然就会想到,如果是Large Batch Size的话,每次我们因为要计算多个example的值,所以速度会比Smaller的Batch计算的要慢。
那其实,我们如果考虑了GPU的平行计算的话并不一定是越大的Batch计算就越慢。使用英伟达的Tesla V100 GPU对一个Batch进行一个Update需要的时间的实验结果如下图
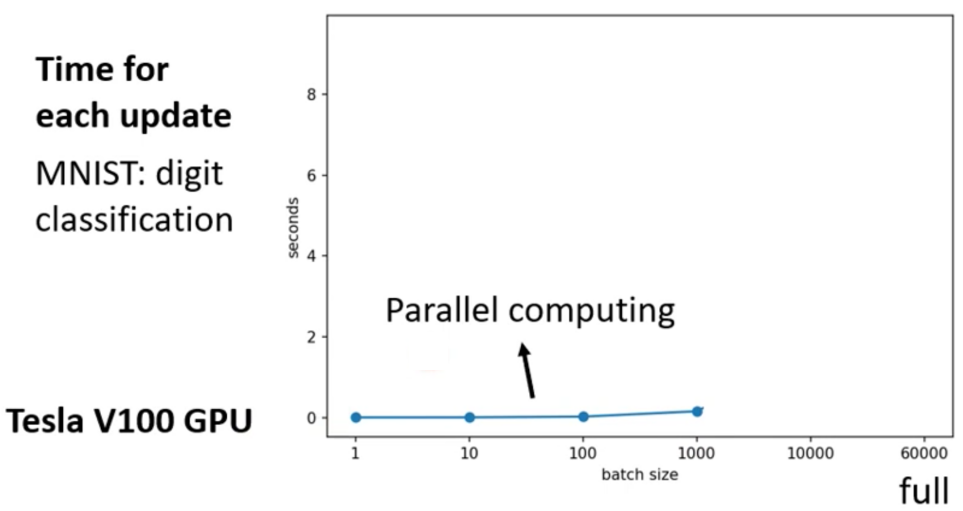
那么我们其实可以看到,在Batch小于1000的时候,其实计算一个Batch花费的时间并没有差很多。这其实就是GPU并行计算带来的提升。
最后,GPU的能力当然不是无穷的,因此,最终当Batch Size大于一定程度之后,计算一个Batch所需要的事件就会很长了。

我们如果从看完整个epoch来说的话,那情况其实就反过来了,小的GPU需要更长的时间跑完一个epoch而大的GPU则需要一个Batch即可

因此我们在综合考虑的情况下,会发现其实我们前面说的两者的区别并不成立。一般来说,总的计算时间会随着Batch的变大而先升高、后降低

C. Is the larger the better?
我们上面说了,对于总时间来说,其实是越大的Batch计算完一个epoch的时间就越短。那么我们考虑到大的Batch的梯度稳定,我们就会想是不是越大的Batch就越好呢?
其实事情也不是这样的。我们下面做一个实验,针对相同的任务,以相同的网络不同的Batch Size来训练,看看最终收敛到的Accuracy是多少。

那么我们其实会发现,大的Batch反而导致最终的精度有所下降。这个就比较神奇了,因为我们用的是同一种Network,这就意味着其实大的Batch和小的Batch训练的网络应该能够表示的Function Set的范围是一样的。可是最终训练得到的结果就是两者不同。
那么为什么小的Batch会要好一点呢?其实一种原因就是如果用Full Batch,那么遇到Critical Point那就真完蛋了。但是对于Small Batch而言,因为每个Batch计算都会由于example的不完全而引入noise,而这个noise可以冲破这个Critical Point,帮助模型进行更多的探索。所以小的Batch会更好一点。
不从引入noise的角度来理解的话,另外一种理解就是我们在计算梯度的时候,其实梯度是依赖于输入的,因此输入的不同,梯度就不同,对应的损失函数反向传播到这里的值就不同,因此我们对于其中一个是Critical Point,但是对其他输入的损失函数来说不一定是Critical Point。那么只要这个Critical Point能够更新就行了。

D. Smaller Batch, Better Generation
我们上面给出的小的batch的性能要更好只是训练阶段的效果,那么我们就会想,看看大的batch和小的batch训练得到的模型在测试集上的表示如何?换而言之,就是大的Batch和小的Batch谁的泛化能力更强。
因此,在进行这个实验的时候就需要排除其他的因素的影响,因此我们需要通过各种方法,例如调参,让大的batch训练得到的网络在测试阶段的性能和小的batch得到的性能近似的时候,然后再在测试数据上测试两种的泛化能力。
那么实验一共对五种网络在几个不同的数据集上进行了测试,发现哪怕是测试集上的表现差不多一样了,在测试集上的表现依旧是小的Batch得到的模型的泛化能力比较强

那么这个现象就非常有意思了,而在上面提出这个现象的文章里的解释是Sharp Minima。
具体来说,如果想让小Batch训练的模型卡在Local Minima上,那么就需要Loss Function在这个点周围的Loss都比较小,这样的才能够Cover掉noise带来的随机的波动。即小的Batch Size训练的网络最后会卡在flat的Local Minia;而Large Batch Size训练出来的网络就没有这样的性质了,容易卡在Sharp的Local Minima。
配合图像来说,我们的Loss Surface上可能有不止一个Local Minima能够达到差不多的Training Loss。如下图

然而,由于Testing的数据和Training的distribution不同或者说我们sample的时候会存在偏差,所以导致了测试数据的Loss Surface会存在一点点的偏差。
那么对于左边的Minima,偏差了一点他的Testing Loss差的不多。而右边的Minima则是偏差了一点可能Testing Loss就会差很多。

而就像前面很多,Flat的Local Minia其实更容易让Small Batch训练得到的网络陷进入。
E. Summary of Batch Size
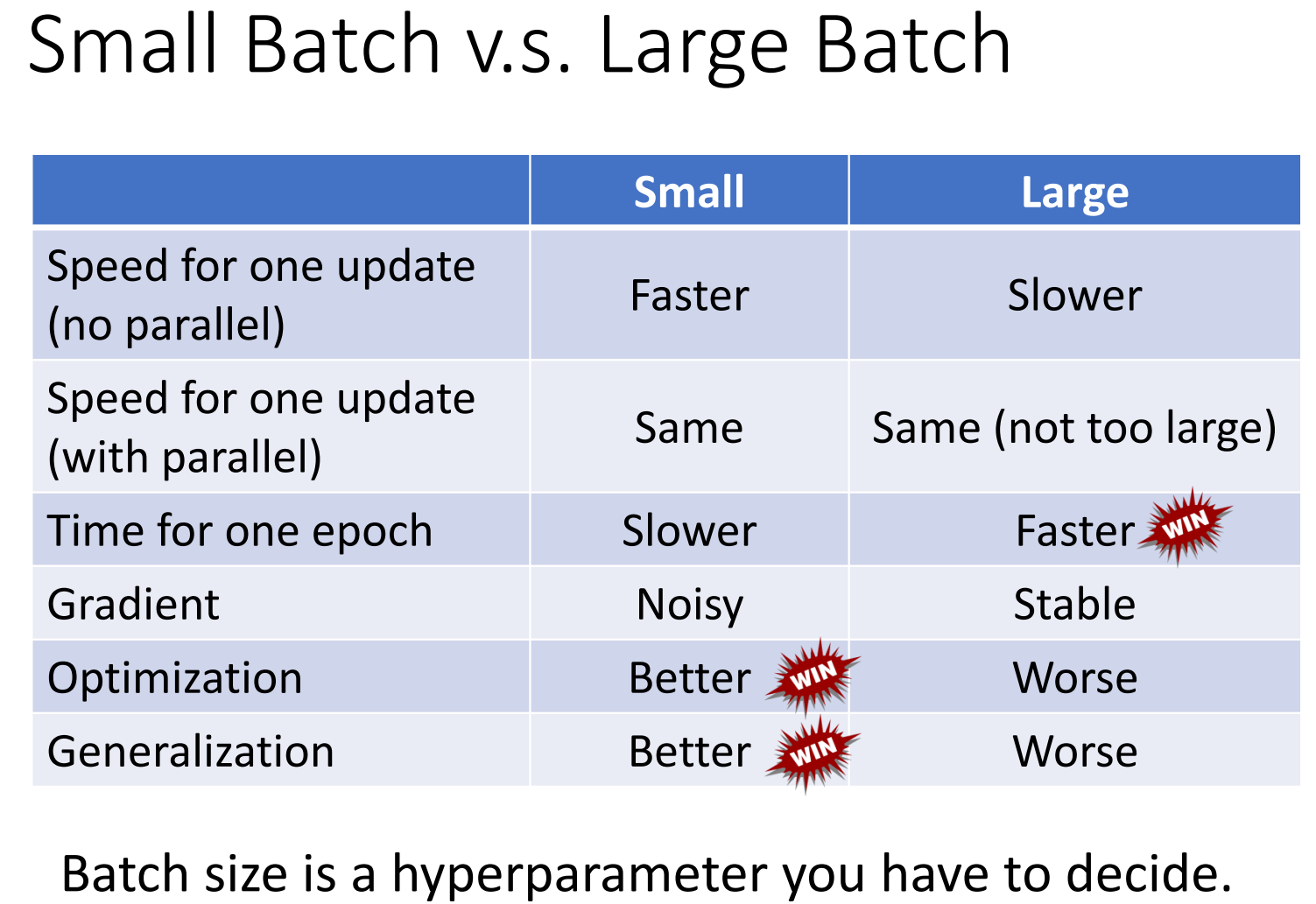
最后我们对不同的大小的Batch Size训练的特点进行一个总结,结果如下
最后是一些进一步讨论Batch Size的文章

3. Momentum
我们在前面讲过用Hessian Matrix计算Eigen Vector的方式来对抗Saddle Point,但是这个方法其实是没有人会去用的,因为开销太大了,我们通常的处理就是使用动量来处理。
下面我们就将讲讲Momentum这个技术。
A. Idea of Momentum
动量的这个技术的想法其实是来自于物理。我们想象参数在Loss Surface上的Update其实就可以类比于小球从山顶上滚到山脚下。而对于前面的朴素的Gradient Descent来说,是以跳跃的形式下降的。那么Gradient Descent在Saddle Point就会停下来
可是现实世界中的球并不会在Saddle Point停下来,这是因为现实世界中的球其实是有动量的
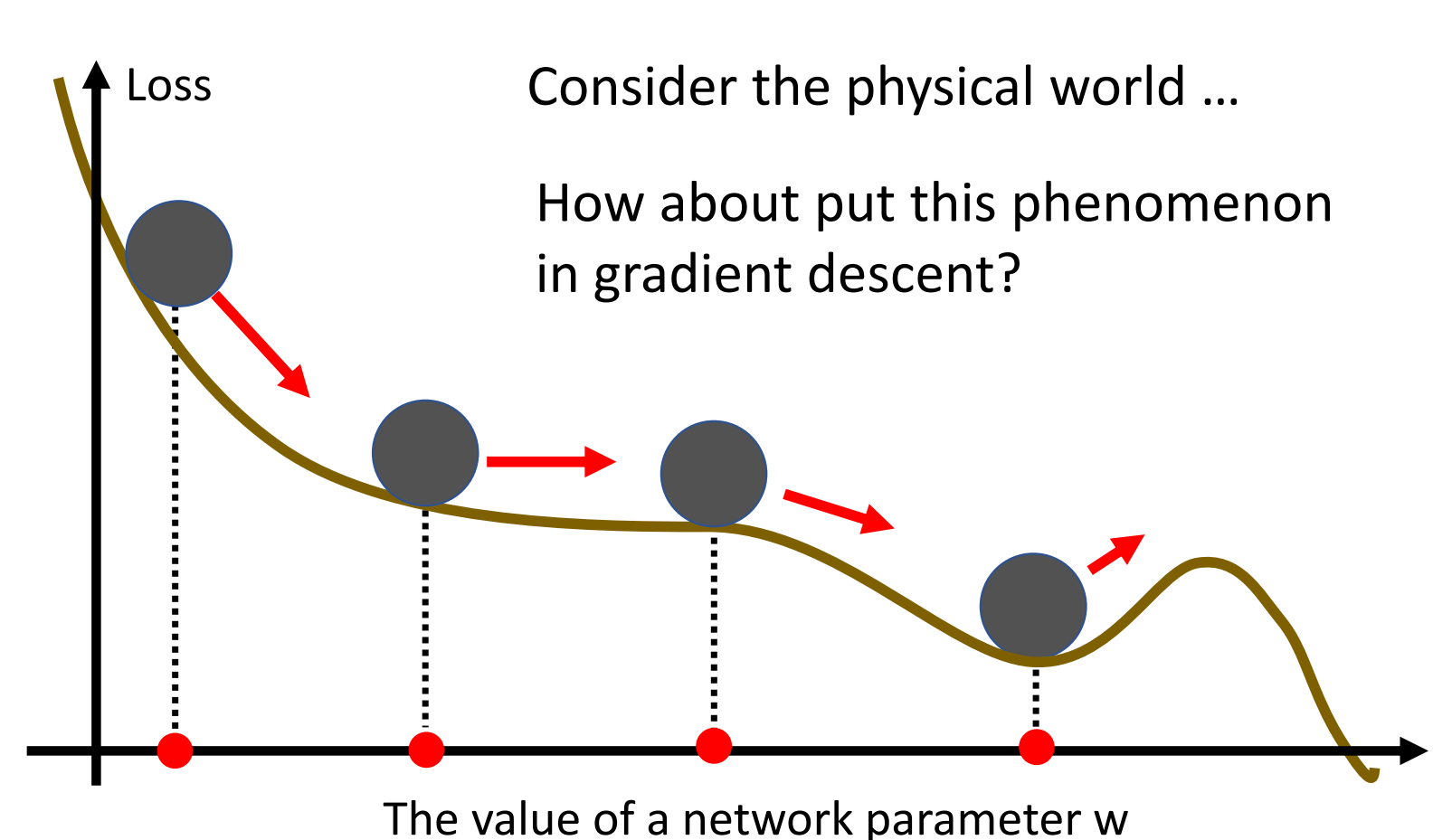
甚至有可能我们的Momentum足够的大,那么这个球就会冲破Local Minima,到更小的地方去。
所以类似的,我们就想在真实的Gradient Descent中实现一下Momentum
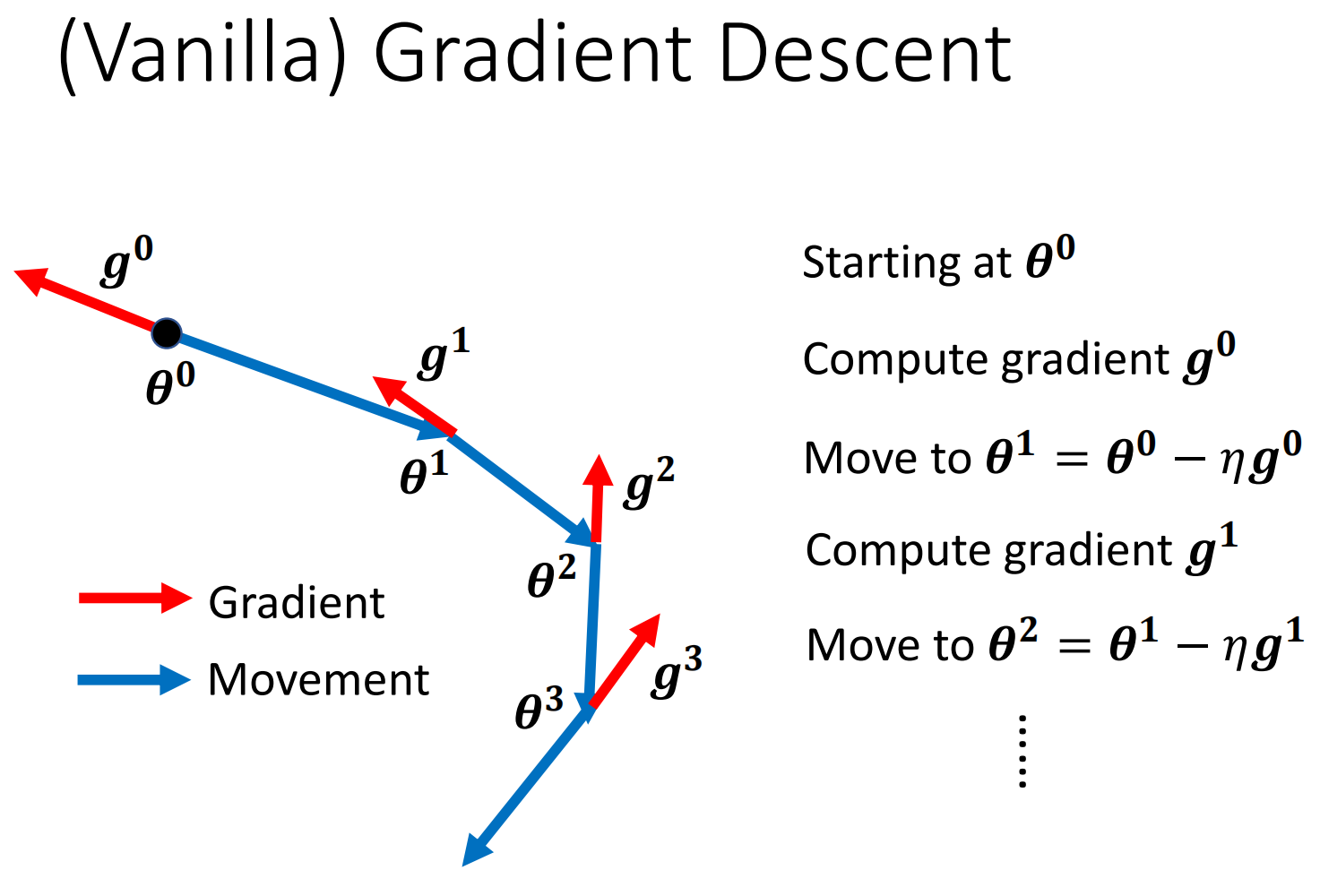
我们先看看Vanilla的Gradient Descent是什么样的。正如下图,Vanilla的Gradient Descent是每算一次Gradient就向反方向Update一次。
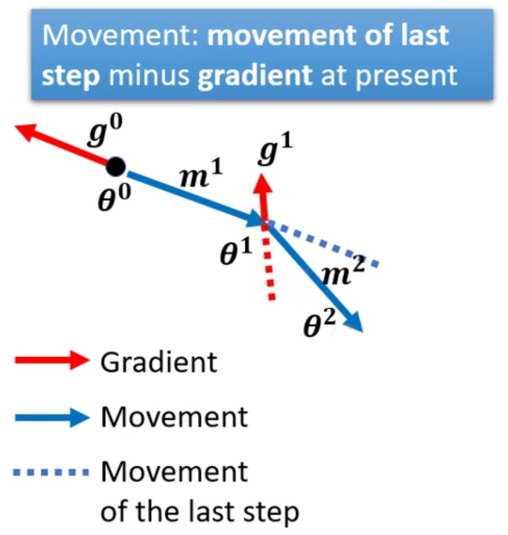
现在我们考虑Momentum的话,Momentum其实可以理解为物体对上一个状态的记忆,因此类似的,我们在进行当前的更新的时候,可以参考一下上一次的Gradient。具体而言,就是我们在这一次的梯度反方向的基础上,稍微偏向一点上一次的梯度方向。在实践上就是上一次的Gradient减去这一次的Gradient。
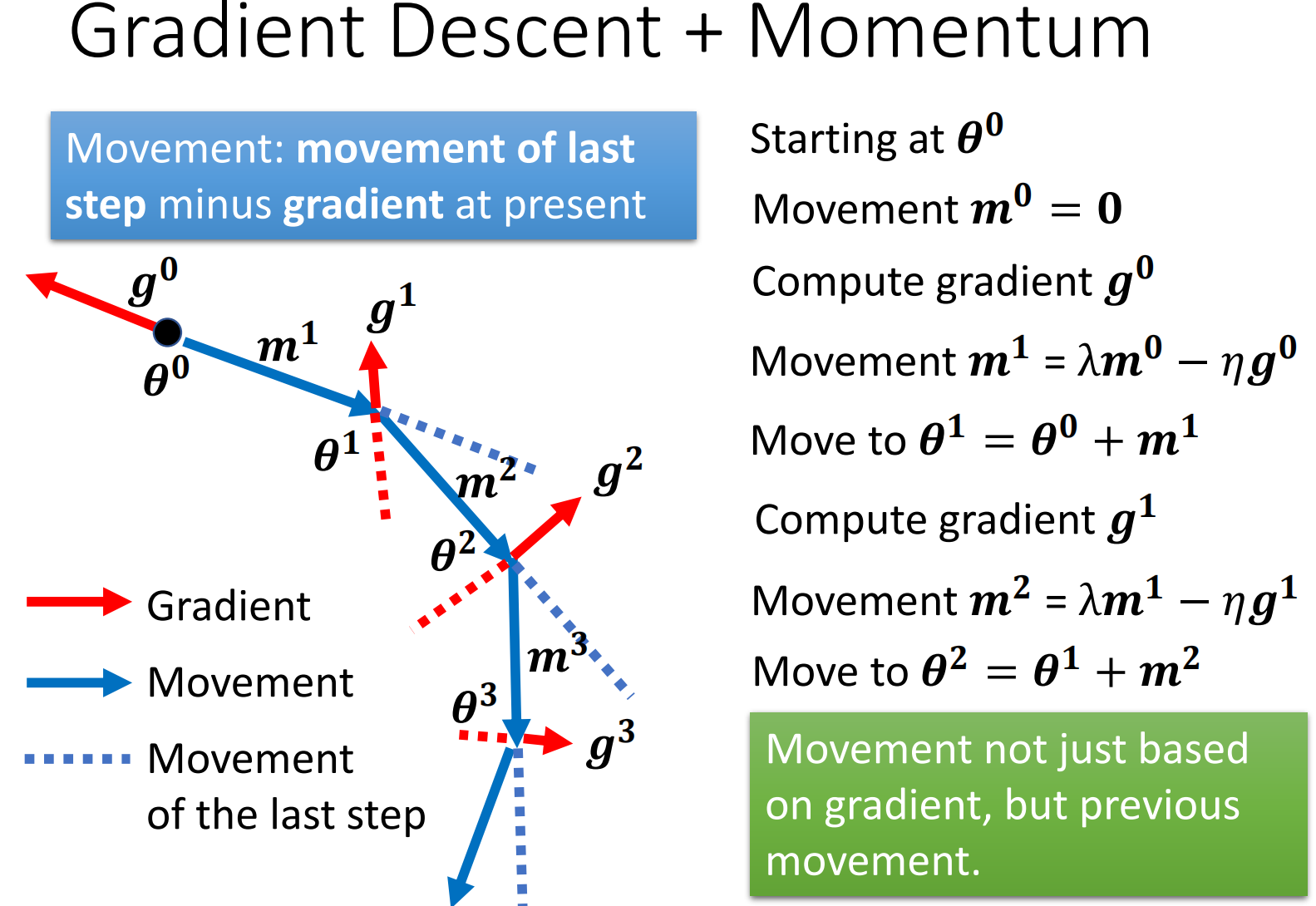
所以此时,最终整个的更新如下
4. Summary
最后我们对上面的内容进行一下总结

二、原因二:Rugged Error Surface
前面我们讲了Critical Point可能是导致Optimization失败的原因,那其实还有另外一种可能就是由于崎岖的损失曲面造成的。针对由于崎岖的损失曲面造成Optimization(Naive Gradient Descent)失败的问题,我们可以通过不同的梯度下降的策略来解决。因此,我们下面将:
- 首先讲解Rugged Loss Surface造成的问题
- 然后再讲解处理崎岖的曲面造成的Optimization失败的处理方法,即不同的Optimization
1. What happen when pptimization fail?
A. It’s actually not critical points
我们前面说当模型在Optimization失败的时候,一种可能的情况是卡在了Critical Point上,这个时候Gradient大部分都是0,因此导致无法训练。
但是真的是这样吗?我们做一个实验来看看,当网络最后训练不动的时候,我们来看看参数的梯度的平均值
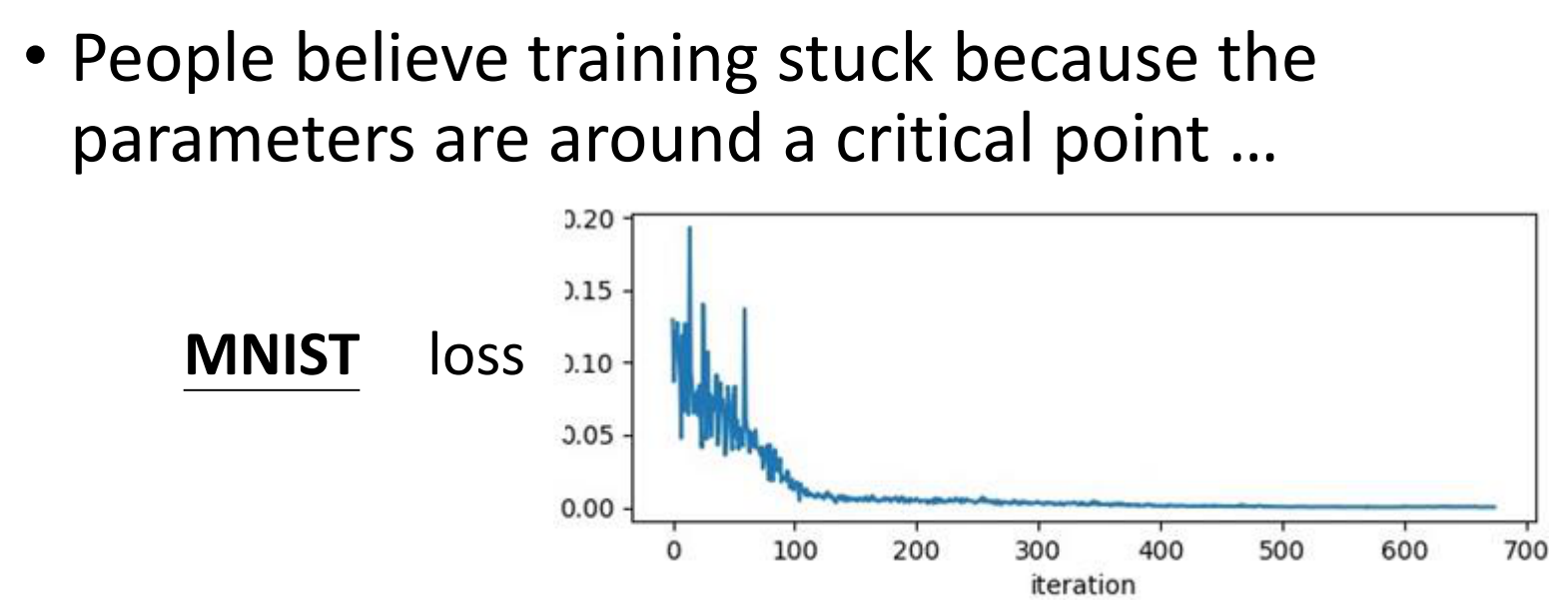
可是Gradient的平均数看下来,每个参数的平均Gradient并不是一直都是零,有的时候还会很大,正如图中圈起来的部分
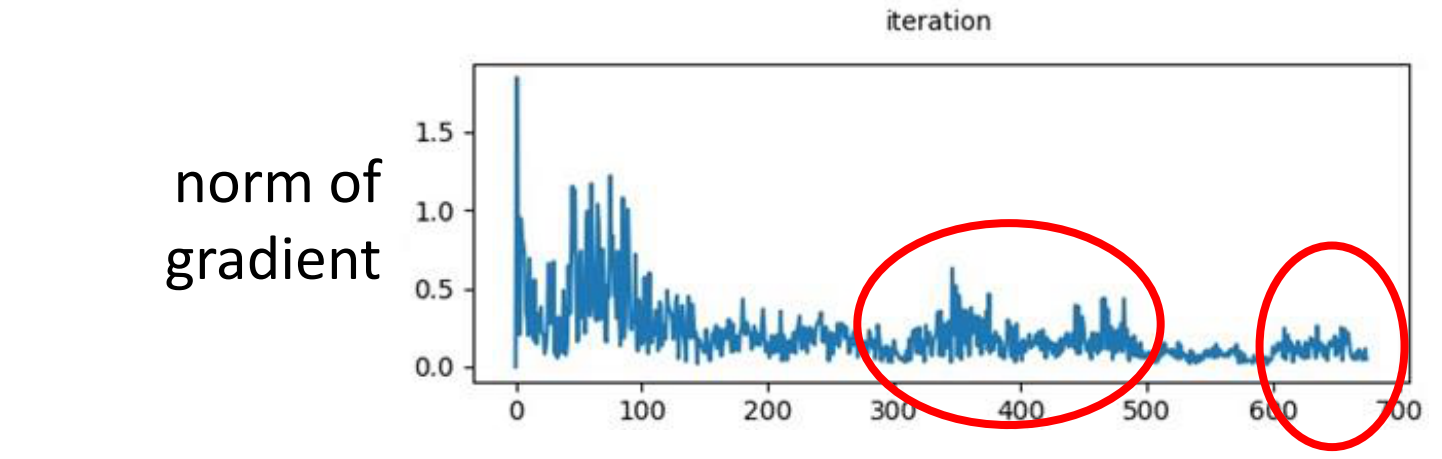
这个时候Gradient有翻天覆地的变化,但是体现在Loss的Curve上,却一直保持不变。
那么这就意味着其实并不是卡在了Local Minima上,一定存在别的原因,这个原因就直接给出来了,就是下面这种,参数一直在山谷间跳跃。

2. Optimizer
针对Rugged Loss Surface,使用原始的Gradient Descent显然就不行了,我们需要对Gradient进行修改,让他带有策略。而(不同的/带有策略的)梯度下降算法又称为Optimizer,
因此,我们可以通过不同的Optimizer来解决上面的在峡谷中跳跃的问题,下面就将讲讲不同的Optimizer
A. What’s the problem of vanilla Gradient Descent?
我们为了更加直观的理解这个问题,举下面的例子
这个例子中,我们的Loss Surface是一个凸的椭圆抛物线,叉叉的地方是最小的地方,我们的模型从黑色的地方开始更新

虽然这个Loss Surface非常的简单,可是即便是这样的Loss Surface用Gradient Descent都不一定能够找到最小值
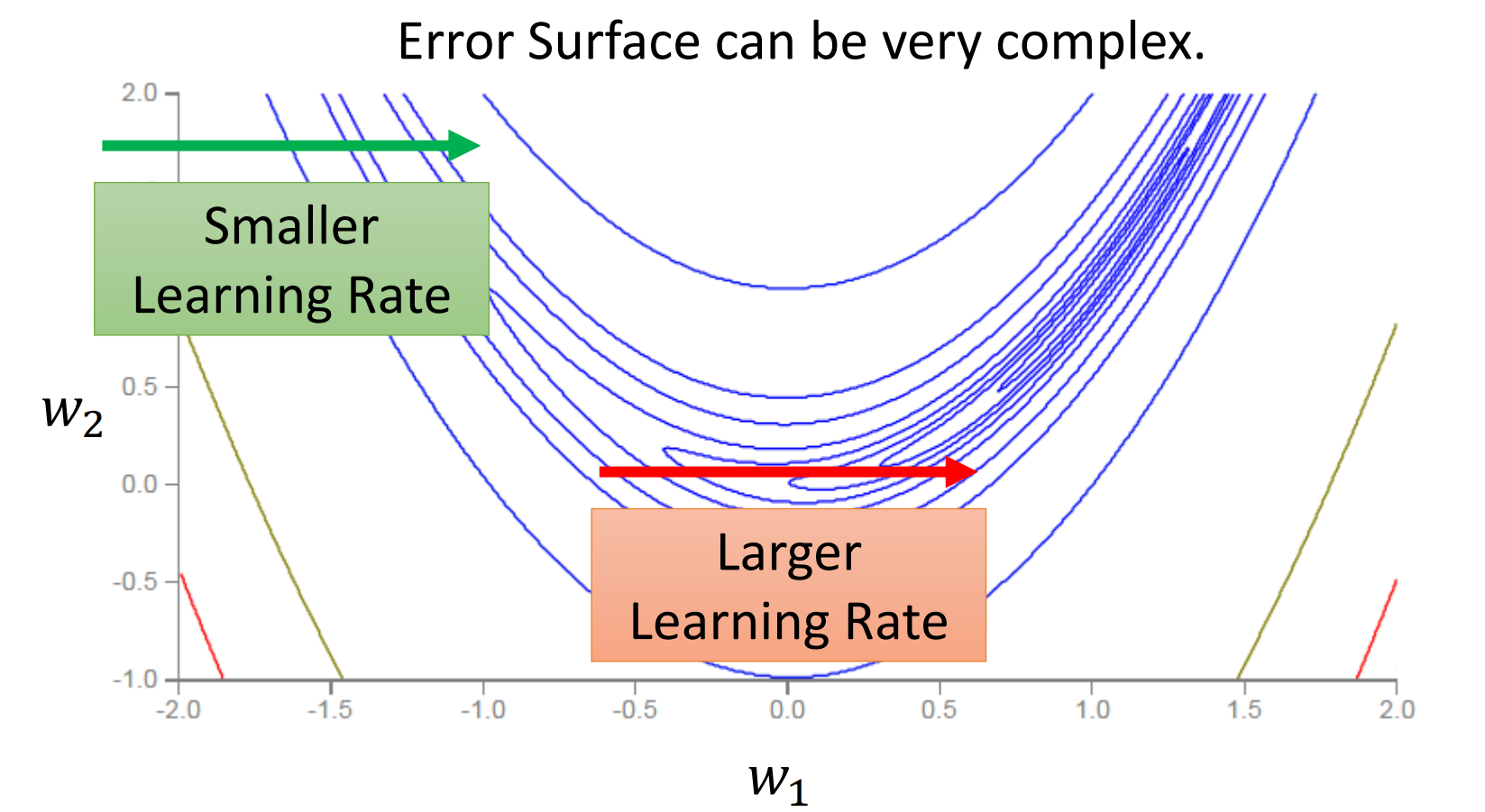
我们第一次把学习率设为0.01,结果模型就一直在山谷两边跳来跳去
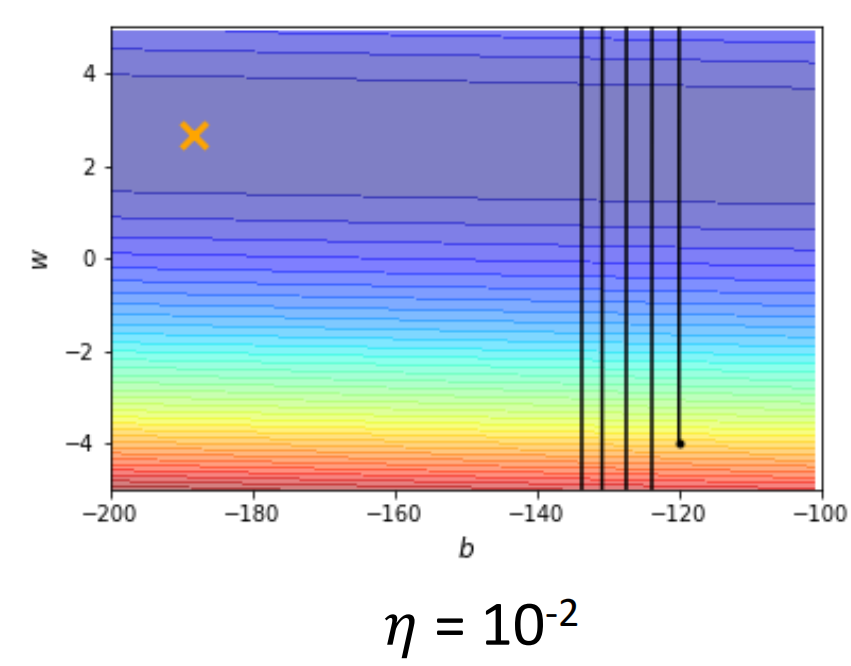
那这个时候有人就会说,是我把学习率设的太大了,我们把学习率设小一点肯定就没问题了。可是事实却是,我们把Learning Rate设小了,还是没有办法学习到全局最优。而且到了后面基本上十万次Update都才只能前进一点点。

我们深究这个问题就会发现,这个其实是由于我们的Learning Rate的锅。
我们每次把Learning Rate设成一样的参数,导致在梯度小的时候难以前进,而在梯度大的时候有前进的过多,所以我们自然就会想,能不能对Learning Rate进行改进,让他不必每次都是一个常数
我们自然而然的就会想让Learning Rate在梯度大的地方比较小而在梯度小的地方比较大
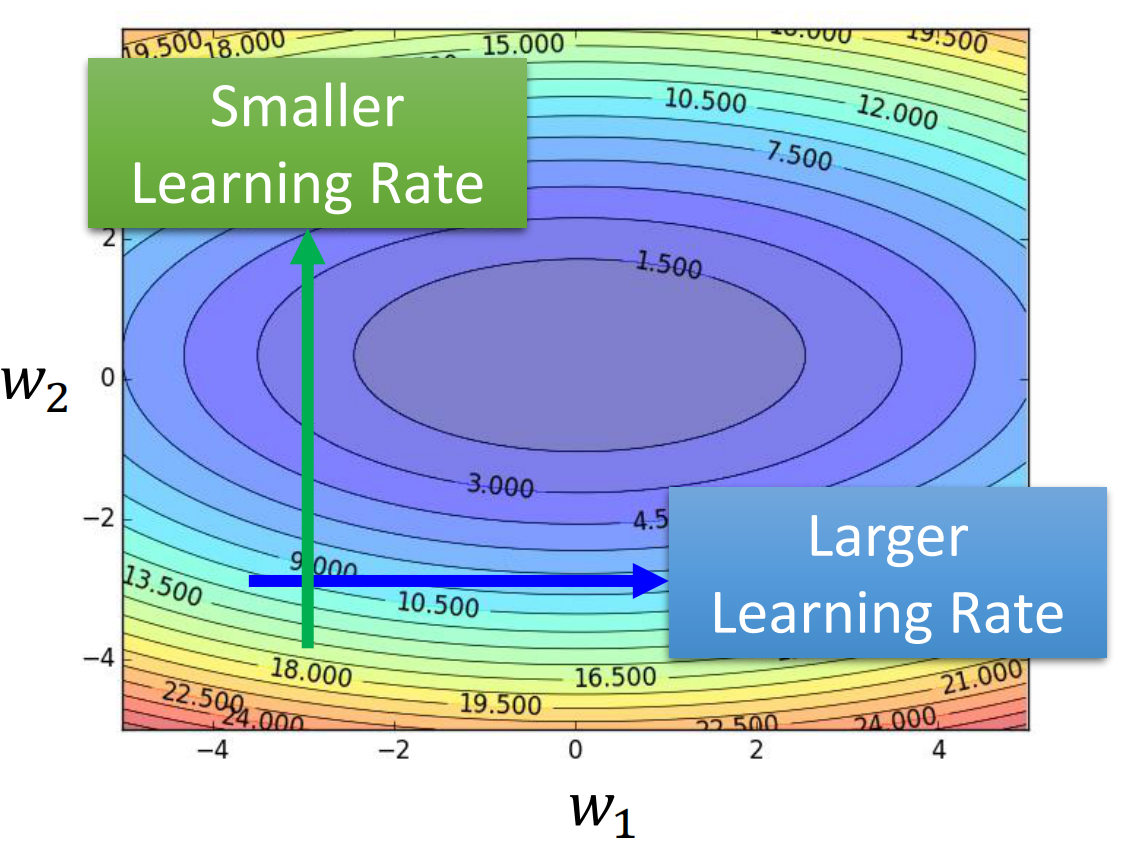
那么为了实现这样的效果,我们就可以再额外的引入一个在真正进行更新时候控制Learning Rate的参数。这个参数是依赖于模型的参数的,此外还依赖于更新的次数,因此我们的记号中会有表示参数和更新次数的符号,即$\sigma_i^t$。

B. Rooted Mean Square(RMS)/Adagrad
Rooted Mean Square表示的是方均根。而RMS在这里的意思其实就是让这个参数$\sigma$是梯度的方均根即可,即
上面这个式子展开的话,就是下面这样的

RMS被用在了Adagrad这个优化器中
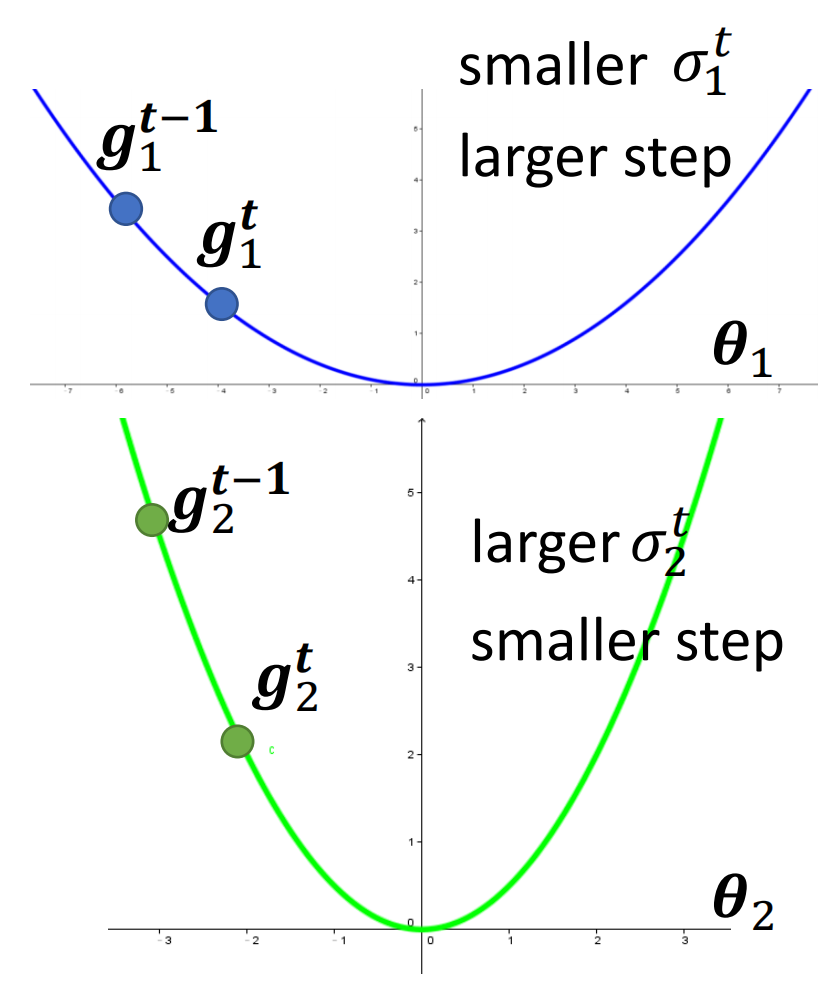
我们不经会问,为什么RMS可以实现我们上面说的,在梯度大的时候控制前进的step小而在梯度小的时候控制前进的step大?这个其实非常好理解,因为方均根的参数$\sigma$是和梯度的大小成正比的,梯度越大Sigma就越大,除下来就越小,反之亦然
C. RMSprop
我们上面将了RMS这个方法,然而RMS这个方法其实有一个问题,就是在计算参数$\sigma$的时候是考虑了之前所有的梯度的。假如说现在在某个方向上更新了1000次,前9000次的得到的梯度都很大,但是到了9000次以后的梯度就很小了。可是如果使用RMS的,9001次及以后都不会更新了,因为计算出来的$\sigma$太大了。
其实造成这个现象的根本原因就在于RMS这个方法是记忆性的,他计算RMS的时候会把所有之前的Gradient拿来用。因此导致了这个问题。所以我们想要进行修改的话其实就让RMS遗忘掉之前的梯度就行了。具体实现遗忘的方法有很多,可以固定只使用前面的几项,也可以给前面的项不同的权重等等。
RMSprop就是一种实现遗忘的方法。
RMSprop的一些故事
其实RMSprop这个方法有一点传奇,因为这个方法是找不到论文的。在很多年以前,大概是十年前,2010年左右,Hinton在Coursera上开过一门Deep Learning的课,在这门课上Hinton讲解了RMSprop这个方法,所以大家要cite的话,其实都是cite那个视频的链接。
RMSprop中实现遗忘的方法就是我们自己设置一个记忆率,决定要把之前的梯度记忆多少到当前的梯度里来

使用RMSprop的好处之一,就是可以实现上面说的,根据局部的梯度来动态调整。RMSprop算法就是RMSprop这个优化器实现的

D. Adam:RMSprop + Momentum
今天其实最常用的Optimizer并不是RMSprop,而是Adam。Adam优化器其实就是RMSprop+Momentum。

3. Learning Rate Scheduling
我们上面介绍了崎岖的曲面导致原始的梯度下降其实是不行的,因此我们又讲解了其他对梯度下降进行修改了的算法,即其他的Optimizer。
但是其实上面的Optimizer本身是有问题的,我们下面会首先通过一个案例来进行讲解,然后再讲解处理这个问题的方法,即Learning Rate Schedule
A. What’s the problem of Optimizers?
我们现在随便从上面的三个优化器取出来一个,因为这个问题对三个Optimizer是共性的,和遗忘、动量都无关,因此我们为了简单起见,就以Adagrad进行讲解
还是上面的例子,我们这次试验一下Adagrad的表现

我们进行时候之后发现,在开始阶段确实Adagrad避免了Vanilla的Gradient Descent的结果,可是到了后面,就会出现暴走。
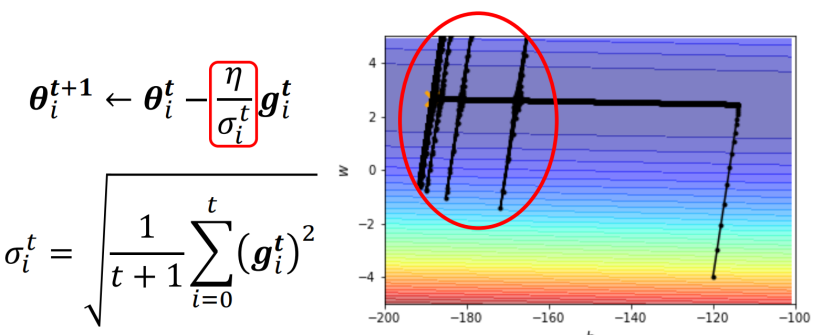
那么这个暴走发生的原因其实是,我们在Optimizer帮助模型完成了竖着走之后,开始横着走了一段时间,在这段时间里竖向的梯度都很小,因此在过了一段时间之后,当更新的次数一多(t一大),那么就导致横向的梯度就很小,所以sigma就会很小。那么就会在这些方向上除完以后,梯度直接起飞。
不过由于梯度下降的原因,虽然横向的梯度起飞导致Loss爆炸了,我们等一会之后其实模型还是会回到正轨,继续向左走,然后再走了一段时间之后继续暴走(同样的原因)。然后如此往复,直到Local Minima(当然如果假设参数的取值只有这些的话,那其实就是Global Minima)。
所以我们其实会发现,使用这些自适应的Optimizer的一个问题就是,我们如果保持在某些方向上的梯度一直都很小,那么在累积一段时间之后就会暴走。
而暴走虽然进行了更多的exploration,但是却浪费了很多的Update。这就是自适应的Optimizer的问题。
B. Learning Rate Decay
我们发现,自适应的Optimizer造成的问题其实是由于$\sigma$在某些情况下会过小,而这个时候$\eta$保持不变,所以除下来的值就很大了。
那么为此,我们想要减轻这个问题,就让$\sigma$变小的同时$\eta$也变小,那么就实现了减小震荡的范围

因为我们这个Learning Rate Scheduling的方式就是让学习率不断减小,因此这种Learning Rate Scheduling的方法其实又称为Learning Rate Decay。
Learning Rate Decay的效果如下,可以看得出来非常不错

C. Warm Up
我们说Learning Rate Decay,就是说要求学习率随着时间下降。而Warm Up则是说要首先从0开始增加学习率然后再减小学习率
这个想法一开始听着可能匪夷所思,但其实也是合理的,因为在初始阶段,一开始求得的梯度是有非常大的偏差的。因为一开始随机初始化的参数表现肯定烂,然而我们又是一个Batch一个Batch的进行训练的,所以一开始计算的时候,模型本身Loss就大,大了还不算什么,我们的Batch又会引入偏差,所以就导致一开始的梯度会有问题。
而在进行了一段时间的学习之后,$\sigma$所表达的过往的梯度其实以及比较平均了,因此这种Variance就会被Cover掉,所以后面给大的权重。而一开始的阶段给小的权重其实就是为了让模型先在Loss Surface上进行一下探索,在探索的比较准确之后再开始迈大步
不过上面的这个说法只是一种可能的解释,目前对Warm Up还并没有一个统一的、公认的解释。

而类似于Warm Up这样的Learning Rate Scheduling的方法其实并不是最近才出现的,在远古时代就已经出现了
例如何凯明2015年的ResNet就已经Reference到了

类似的,其实在Transformer里面也用了Warm Up,只不过是以数学形式表达的形式,这个函数画出来就是Warm Up,先升高后减小

关于Warm Up的更多内容,参考RAdam

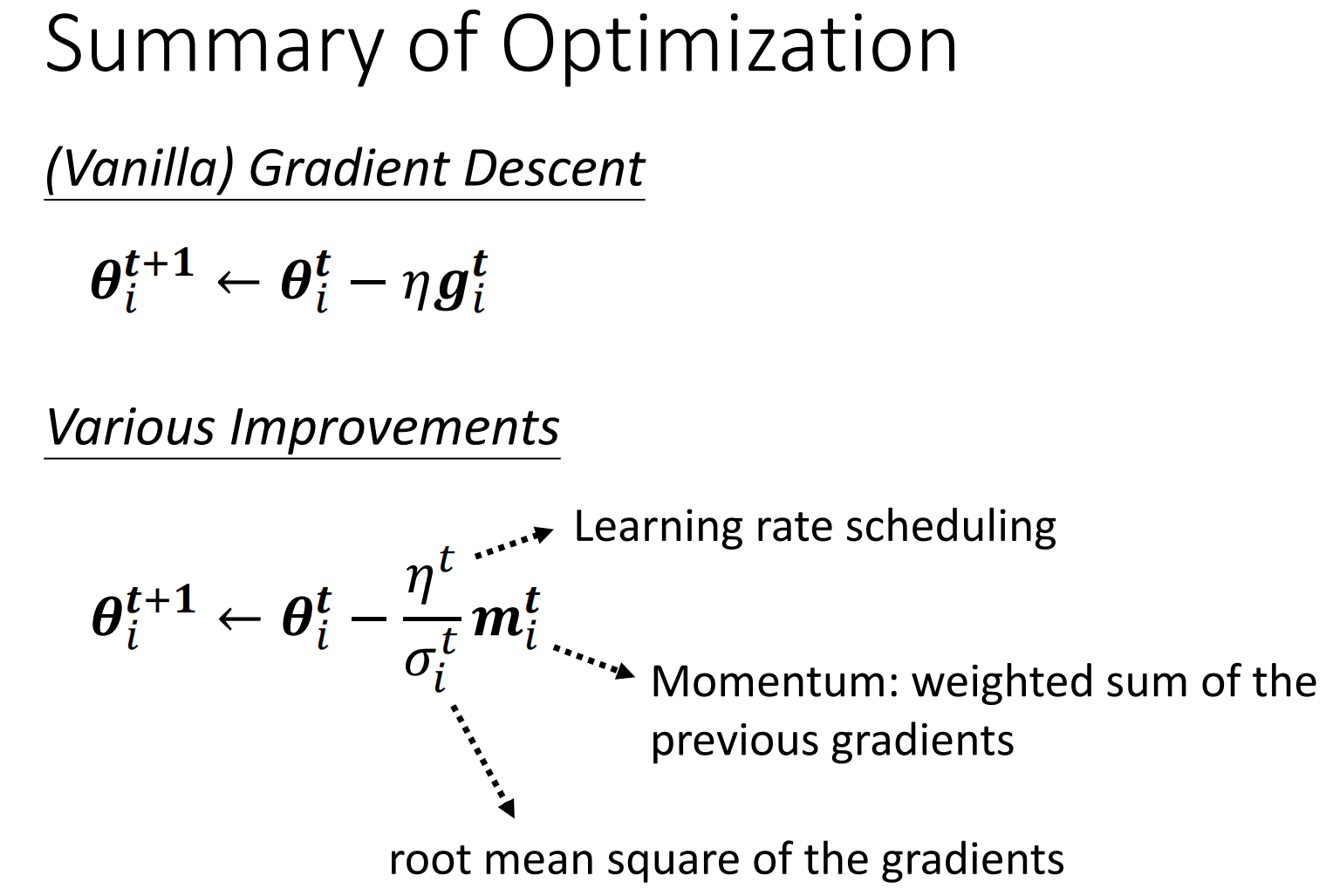
4. Summary of Optimizer
最后我们对Optimizer进行一下总结,我们对原始的梯度下降从两个不同的角度对他进行了提升:方向和幅度
然后针对幅度可能导致的新的问题,我们又讲解了处理这个问题的Optimizer Warm Up
最后就是更多关于Optimizer的内容

三、Batch Normalization
上面我们说到,当Loss Surface比较崎岖的时候其实就会非常难Train。为此,我们会利用不同的Optimizer和Learning Rate Scheduling来处理这个问题
然而,针对崎岖的Loss Surface带来的问题,另外一种处理思路就是,我们其实没有必要为了陡峭的山峰来设计让模型能够来回绕路的算法,我们能不能用神罗天征直接把山炸平

答案当然是可以的,通过Batch Normalization就可以实现这个效果
1. Rethinking rugged loss surface
我们在上面讲Optimizer的时候说过,Vanilla Gradient Descent其实Optimization的能力是有限的,即便是一些简单的Error Surface都不一定能够Train好

而原始的Gradient Descent在开始变横向移动之后就很难走动了。针对这个问题,我们上面是对Gradient Descent的方法进行了修改。导致这个问题的根本原因是在Loss Surface上,一个方向梯度大,一个方向梯度小。
那么我们就不禁要问问,为什么会导致上面这个问题?
我们从模型入手,产生上面这个Error Surface的模型其实非常简单,就是下面这个模型

而梯度则衡量的是输入的变化对输出的影响,因此为了看看梯度,我们给Loss Surface的两个变量$w_1$和$w_2$进行一下适当的改变
我们现在给$w_1$增加一个$\Delta w_1$,那么$\Delta w_1$对$L$的影响是首先对$y$产生一个影响$\Delta y$,然后$\Delta y$又对$e$产生一个影响$\Delta e$,最后$\Delta e$再对$L$产生影响$\Delta L$。
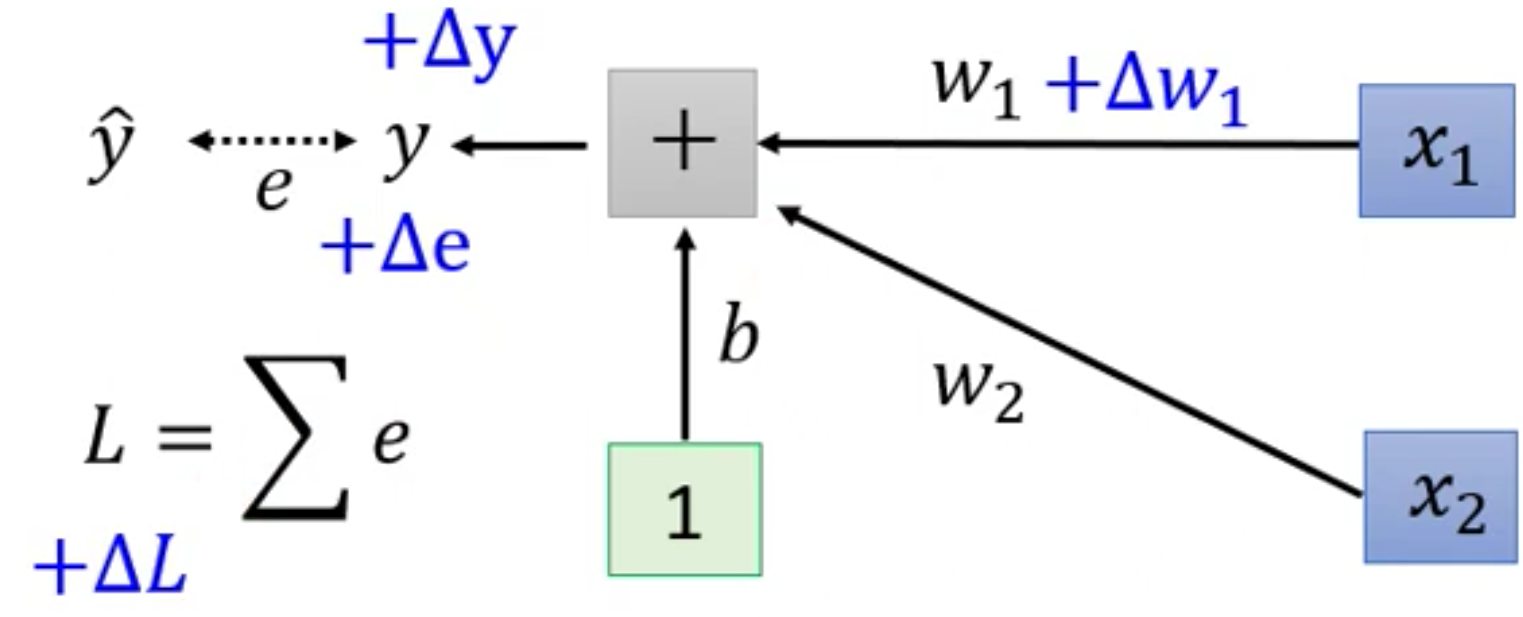
那么在什么时候,$w_1$的变化对$L$的影响(梯度)会很小呢?那么只有当和$w_1$相乘的$x_1$比较小的时候,这个影响才会很小。
原因的解释当然可以从数学的角度出发,给出来上游梯度和局部梯度。不过我们不准备那样讲解,因为太抽象了。
我们想,如果$\Delta w_1$保持不变的话,那么如果$x_1$比较小,乘下来的$y’$就等于
对应的,
因此,在保持$\Delta w_1$不变的情况下,让x$_1$变小就可以对应的,让$\Delta y$变小。同理,这个反应是链式的,因此最终$\Delta L$也会变小
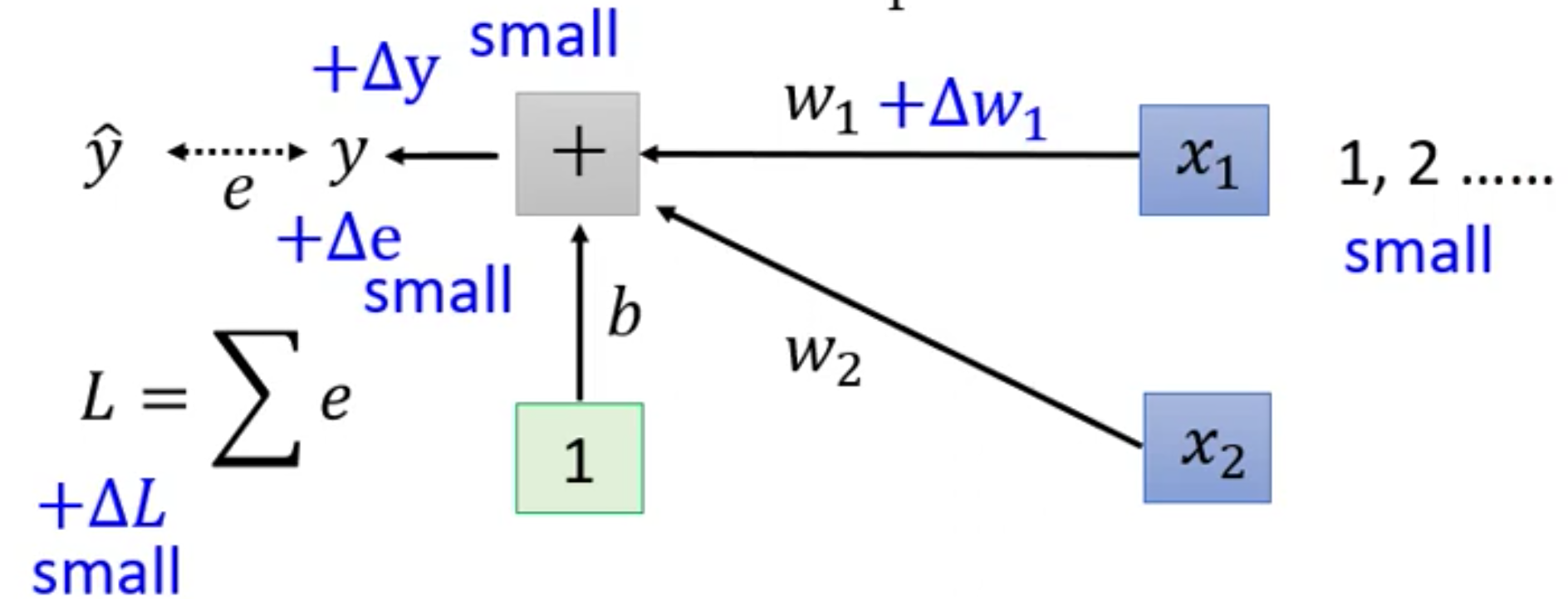
所以这个时候就会出现Loss Surface中在水平方向梯度很小的情况,也就是Loss Surface非常平滑

同理,如果$x_2$很大,那么就会导致在$w_2$方向上的梯度非常陡峭

因此,我们就会想,如果让一个input里不同的feature具有同样的range的话,我们的Error Surface是不是就会平坦很多?
换而言之,我们可以通过对输入输出的范围进行修改,即通过归一化的方式让输入不同的feature的范围到一起去,那么我们的Error Surface就会变的非常平坦,而这个操作其实就是Feature Normalization

2. Feature Normalization (For Single Layer)
我们基于前面Rethinking得到的结果,下面就将更加具体的讲讲Feature Normalization的方法
假设我们现在有下面这么多的训练数据
上图中每一个橘黄色的圆圈表示一个Feature。那么Feature Normalization的步骤是首先把不同个example的同一个Dimension(假设是第$i$个Dimension)的Feature取出来计算他的mean,得到$m_i$。然后我们计算这些Feature的Standard Deviation得到$\sigma_i$
然后我们对其中每一个example的这一个Dimension的Feature进行下面的计算,即减去均值除以标准差。最后就得到了Normalize之后的结果
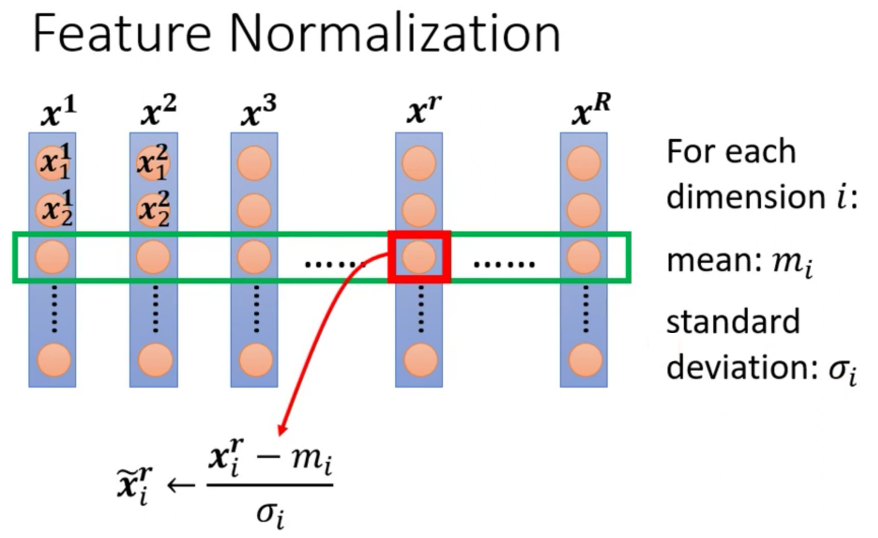
这样,当我们在昨晚Feature Normalization之后,对于每一个Feature,他的Mean是0而Variance是1。这样其实就会比较好Train

3. Normalization For Deep Learning
我们上面讲解的Feature Normalization其实是针对一层的模型,我们下面来讨论一下在深度网络中Feature Normalization是怎么实现的
首先对于第一层输入层来说,我们可以直接对每个输入数据$x$的每一个Feature 进行Normalization之后得到$\tilde x$,然后后面接$W^1$,Activation Function得到这一层的输出,然后后面继续想接几层就看我们自己。

可是,我们仔细想想的话,就会发现有一个问题,就是对于第二层$W^2$来说,它的输入是a。而我们知道给向量(每个example就是一个向量)乘以矩阵$W^1$其实就是对这个向量进行线性变换。在进行线性变换之后,输出的$z$的值不一定是均值为0,标准差为1的了。然后通过了一个非线性的激活函数,那么就更不知道了。
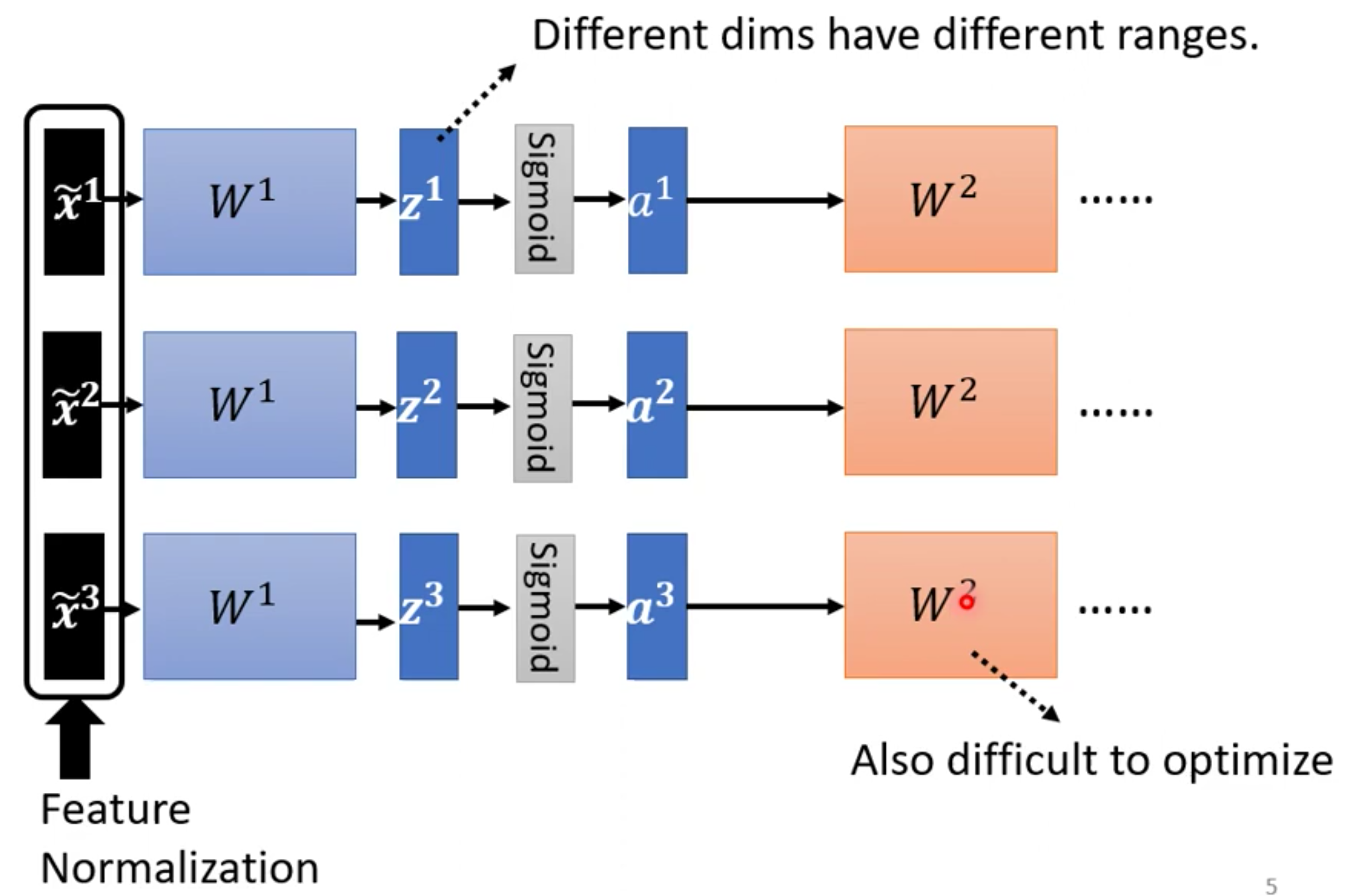
因此在进过$W^1$进行变换之后,进入到下一个层的$W^2$之前,我们还需要再进行一次Feature Normalization

而进行Feature Normalization的位置的话在激活函数前还是激活函数后其实都可以,因为在实践上两者是差不多的。我们这里的讲解以对z进行Feature Normalization为例,具体的计算步骤如下
首先计算出来一个均值向量和方差向量

然后让每个example和均值向量相减之后除以方差向量(按位计算)
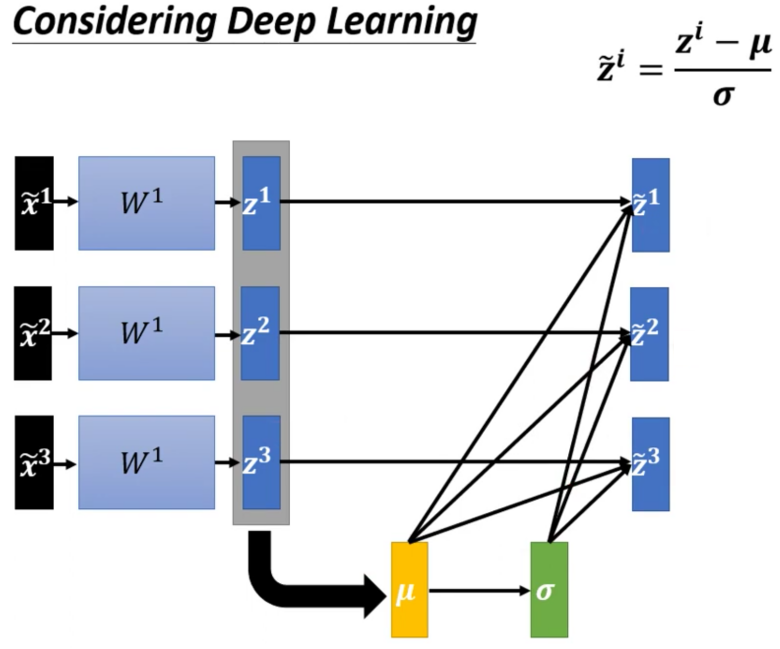
然后继续把结果丢给后面的网络即可

然而,正是因为我们在做Normalization的过程中需要计算均值和方差,因此我们现在网络其实一次是要吃一批example进去的。所以站着输入的角度上来看,现在的Network变大了,成为了一个同时接受N的输入的大网络,这个大网络中不同的输入是共享同一套参数的
从另外一个角度来理解为什么成了一个大网络的话,我们如果给$\tilde x^1$一个扰动的话,那么对应的$z^1$就会产生一个$\Delta$,进而会影响$\mu$和$\sigma$,最后反过来,影响所有的$\tilde z^i$。所以这一批输入其实是作为一个整体,只要有一个变化其他的全部都会变化,因此我们就会看到,网络变成了一个非常大的网络

4. Batch Normalization
我们需要计算均值和方差,因此我们就需要把example读入到内存中去,然而由于GPU的显存通常是有限的,因此一次只能读取一些example,即读入一个batch。而我们每次也就是对这个batch计算均值和方差。
所以我们上面讲的Normalization这招其实叫做Batch Normalization
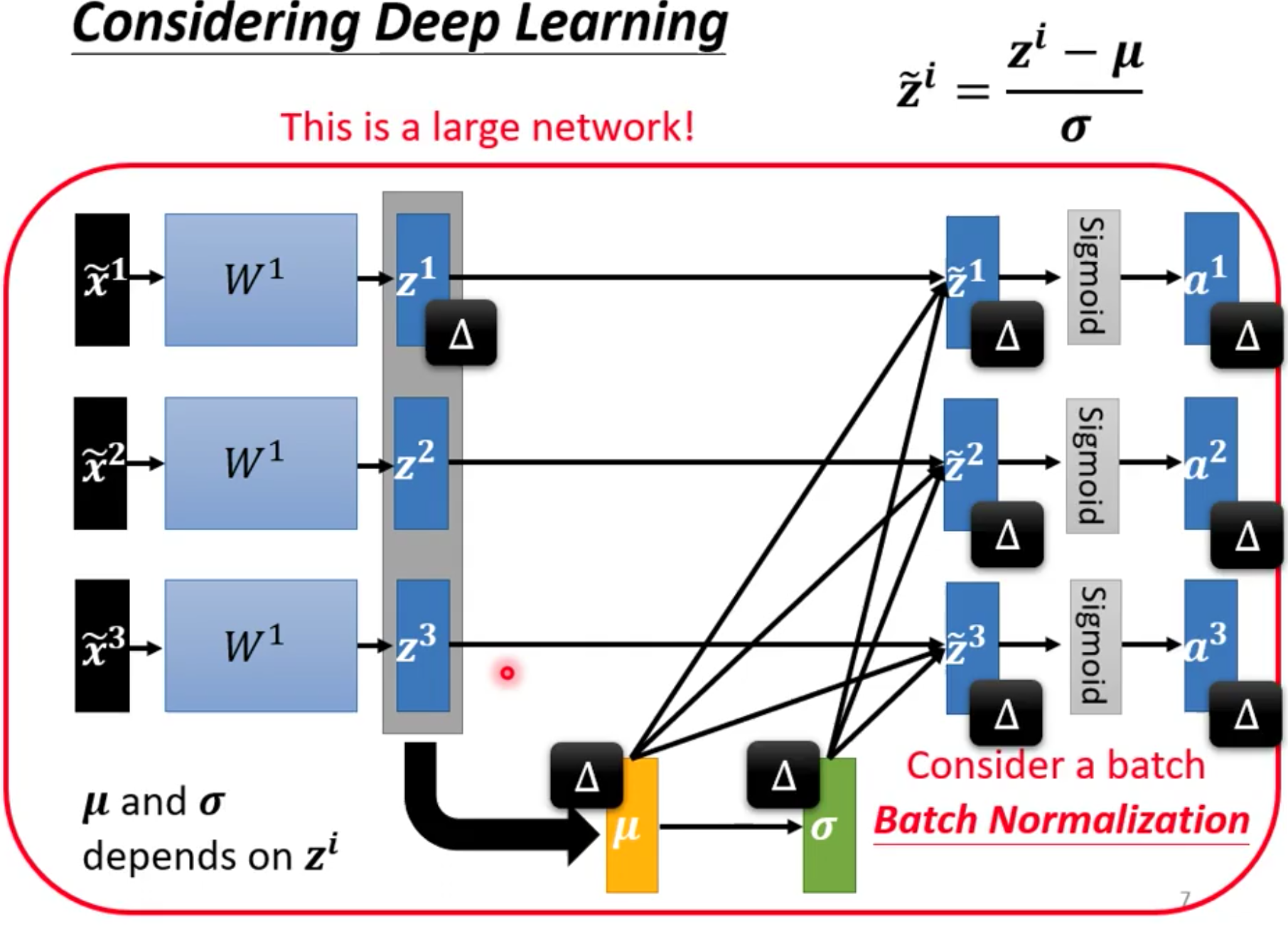
此外,关于Batch Normalization有一个问题就是我们在实践中其实还是让计算得到的$\tilde z$和一个向量$\gamma$进行哈达玛积,然后再加上另外一个向量$\beta$。
这样做的原因就是我们进行Batch Normalization的话其实是强制让输入的均值和方差变成了0和1,对应的,这就有可能给网络的训练带来限制,因此我们乘以一个$\gamma$再加上一个$\beta$,让网络自己去学一下这个需要的均值和方差

5. Batch Normalization for Testing
接下来我们就要讲一讲在测试阶段的Batch Normalization了
Batch Normalization在Testing的时候有一个问题。就是我们上面说的,因为要计算均值,所以我们是需要有一个Batch的数据才能计算。
可是在测试场景中,我们其实是没有办法一次获得一个Batch的,我们一次获得一个Batch的测试数据只是在测试集的基础上的。当模型真正上线之后数据往往是流式的

因此在实践中是不能用$\mu$和$\sigma$的,得用别的计算方法来近似这里的均值和方差。而在Pytorch中,均值和方差是用Moving Average来估计的。具体来说,就是在训练的时候每一个Batch都会计算自己的平均数和方差。然后利用每一个Batch的平均数和方差都会更新移动平均数。$p$是一个超参数,在Pytorch中取0.1

我们在计算了移动平均数之后,在测试阶段,我们就用移动平均数来代替均值和方差

6. Effectiveness of Batch Normalization
最后是关于Batch Normalization的效果。下面是在原论文中的图片
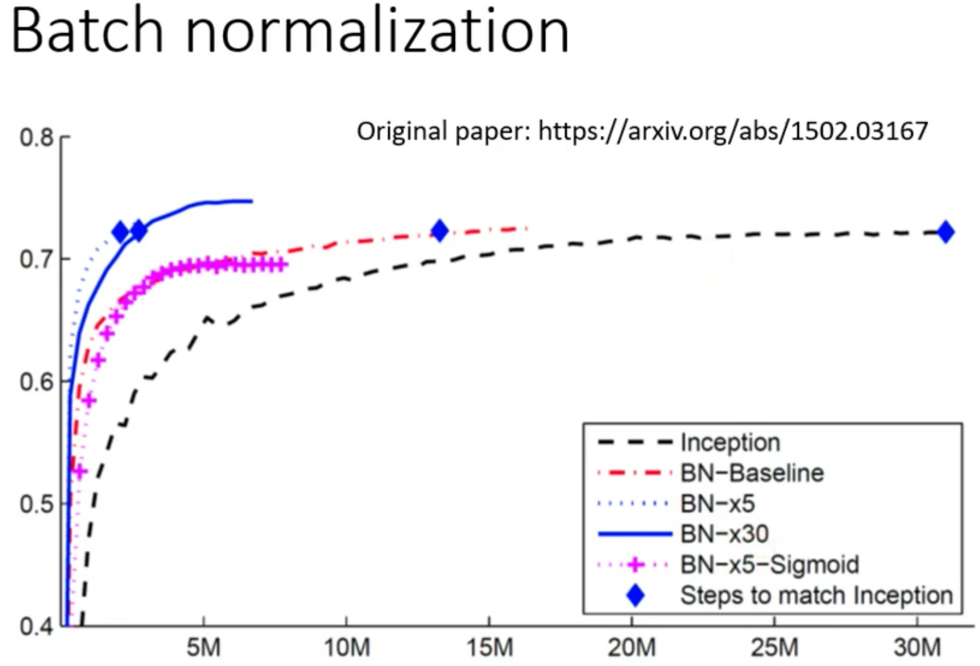
这个图横轴表示更新次数,纵轴表示accuracy。图例中的Inception是Baseline的模型,而BN表示使用了BN,$\times*$表示学习率放大几倍,蓝菱形表示达到Baseline需要的更新的次数。
那么从图里其实可以看出来,要达到相同的准确度,使用了Batch Normalization之后需要更新的次数远少于没有用Batch Normalization的次数
然而关于放大了学习率反而导致性能更好,论文里作者说他们也没有搞懂为什么,不过对于DL来说有的时候就是会有这种怪怪的、不知道该怎么解释的现象。但是因为实验的严谨性,因此在论文里还是要呈现原始的数据
7. Internal Covariate Shift?
Covariate Shift这个概念本来说的是测试集的数据分布和训练集的数据分布不同,这种分布的漂移导致了模型的Generalization能力不行的问题。这个概念其实最早是出现在Machine Learning中的。
而对于Batch Normalization来说,原作者认为Batch Normalization解决了模型内部的数据漂移问题,即Internal Covariate Shift。
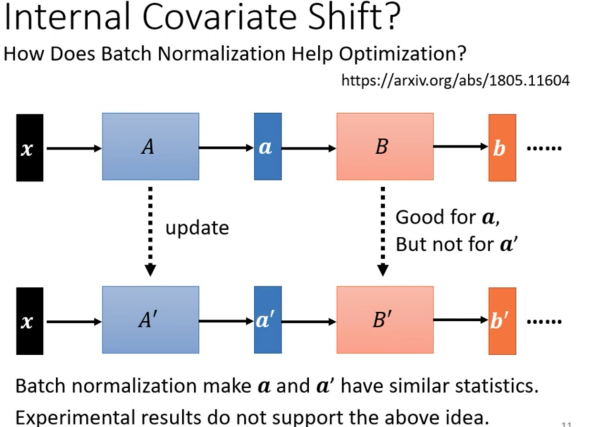
Internal Covariate Shift指的是下面图中的这个问题,就是一开始针对一批example,$A$对$x$计算得到了一个$a$,并且稍后通过反向传播得到了一个Gradient。同理,$B$对$a$计算得到了一个$b$然后计算得到了一个Gradient。
可是问题是,现在在利用从第一个$x$上计算得到的Gradient去更新$A$和$B$之后,$A$和$B$都是更加适应了第一批example。因此针对第二批$x$,通过$A’$之后计算得到的是$a’$,因为第一次层变了,因此第二层的输入的分布也变了,可是第二层的Gradient适应的是$a$,即原先的数据分布而非更新后新的分布,因此$B$又会耗费大量的开销去适应由$A$的更新所导致的中间的Feature Map的漂移
因此在Batch Normalization的论文中,原作者创造了一个词Internal Covariate Shift来描述这个现象

而Batch Normalization能够让前面的层变化了之后的输出还是保持类似的分布,因此能够加快训练。这个就是原作者认为的Batch Normalization的作用。
那Batch Normalization效果好真的是因为这样的吗?答案是否定的,因为后面有一篇文章,设计了各种各样的实验来反驳原作者认为的解释
首先,这篇文章首先说明了Internal Covariate Shift不一定是Training Neural Network时候的一个问题,然后又说了Batch Normalization比较好不一定是Internal Covariate Shift的问题。
具体来说,这个文章里研究了不同的step下$a$的分布的变化,发现分布的变化其实并不大。然后又通过巧妙地构造,让$a$的分布变化很大,发现分布差别很大对Training并没有很大的伤害。最后又研究了一下分布差别很大的$a$和$a’$,发现方向都差不多。
所以这篇文章最后就打脸了原作者的这个观点,指出Internal Covariate Shift不一定是Train网络时候的主要问题,Batch Normalization也不一定是Batch Normalization解决的问题
最后,打脸原文的文章中从数学上和理论上给出了证明,Batch Normalization是通过改变了损失曲边,让其变得更加光滑从而加速了训练。并且从平滑损失曲面来说,作者还设计了其他的几种方法。并且发现这些方法的表现和Batch Normalization差不多,有的表现甚至更好。
因此在最后作者感叹说Batch Normalization的巨大的效果的的发现是非常偶然(serendipitous)的,就像发现青霉素一样

8. More About Batch Normalization
最后,关于Normalization的方法其实有一大把,不同的Batch Normalization的方法的效果也不同。具体参考这些文章。