本文主要介绍了数学建模中常见的评价算法(模型):模糊综合评价

数学建模算法8-模糊综合评价模型
在数学建模中,很多问题都涉及到评价类问题。而针对评价类问题,我们在前面介绍了层次分析法、灰色综合分析两种用于评价的方法/模型。本文将介绍第三种评价模型:模糊综合评价模型。
层次分析法适合于对指标这类主观性较强、数据量较少的问题进行评价,而灰色综合分析适合于少量数据并且已知标准(参考向量)的这类评价问题。
然而在生活中还有一类评价问题:即评价的等级之间是模糊的这一类评价问题。例如现在对一群人的身高进行评价,那么高和矮就是我们可以给出的评价的等级。然而这样的评价等级是模糊的,例如什么样的身高算高、什么算矮、高矮之间的分界线是什么?
因此针对这类评价等级是模糊的问题,就有了模糊综合评价模型。
1. 模糊数学介绍
现实世界中的许多现象和关系具有不确定性。 这些不确定性的表现形式多种多样,如随机性、 灰色性、模糊性和粗糙性等。
模糊数学正是利用模糊集及其运算研究、处理模糊不确定现象和关系的数学分支学科。许多数学建模问题包括模糊现象和关系,这类 问题往往可以用模糊数学方法处理。
下面是百度百科和维基百科上对其的介绍
From BaiduBaike:
模糊数学又称Fuzzy 数学,是研究和处理模糊性现象的一种数学理论和方法。模糊性数学发展的主流是在它的应用方面。
由于模糊性概念已经找到了模糊集的描述方式,人们运用概念进行判断、评价、推理、决策和控制的过程也可以用模糊性数学的方法来描述。例如模糊聚类分析、模糊模式识别、模糊综合评判、模糊决策与模糊预测、模糊控制、模糊信息处理等。这些方法构成了一种模糊性系统理论,构成了一种思辨数学的雏形,它已经在医学、气象、心理、经济管理、石油、地质、环境、生物、农业、林业、化工、语言、控制、遥感、教育、体育等方面取得具体的研究成果。
From Wikipedia:
模糊数学,亦称弗晰数学或模糊性数学。1965年以后,在模糊集合、模糊逻辑的基础上发展起来的模糊拓扑、模糊测度论等数学领域的统称。是研究现实世界中许多界限不分明甚至是很模糊的问题的数学工具。在模式识别、人工智能等方面有广泛的应用。
正如介绍中所指出的,现代数学是建立在集合论基础之上的。
集合论的重要意义就在于它能将数学的抽象能力延伸到人类认识过程的深处:用集合来描述概念,用集合的关系和运算表达判断和推理,从而将一切现实的理论系统都纳入集合描述的数学框架中。毫无疑问,以经典集合论为基础的精确数学和随机数学在描述自然界多种客观现象的内在规律中,获得了显著的效果。
但是,和随机现象一样,在自然界和人们的日常生活中普遍存在着大量的模糊现象,如多云、阴灭、小雨、大雨、贫困、温饱等。由于经典集合论只能把自己的表现力限制在那些有明确外延的现象和概念上,它要求元素对集合的隶属关系必须是明确的,不能模棱两可,因而对于那些经典集合无法反映的外延不分明的概念,以前人们都是尽量回避它们。
然而,随着现代科技的发展,我们所面对的系统日益复杂,模糊性总是伴随着复杂性出现;此外人文、社会学科及其他“软科学”的数学化、定量化趋向,也把模糊性的数学处理问题推向中心地位;更重要的是,计算机科学、控制理论、系统科学的迅速发展,要求计算机要像人脑那样具备模糊逻辑思维和形象思维的功能。凡此种种,迫使人们再也无法回避模糊性,必须寻求途径去描述和处理客观现象中非清晰、非绝对化的一面。
1965年,美国控制论专家扎德Zadeh(Lotfi A.Zadeh)教授在Information and Control杂志上发表了题为Fuzzy Sets的论文,提出用“隶属函数”来描述现象差异的中间过渡,从而突破了经典集合论中属于或不属于的绝对关系。Zadeh教授这一开创性的工作,标志着数学的一个新分支——模糊数学的诞生。
2. 基础概念
在介绍模糊综合评价模型前,需要介绍模糊数学中的一些基础概念
A. 模糊集、隶属度、隶属函数
给定论域$U$,定义$U$上的一个模糊集$A$为:
称映射$\mu_A(x)$为模糊集$A$的隶属函数,而函数值$\mu_A(x)$称为元素$x$对模糊集$A$的隶属度。
因此,模糊集就是每个元素都有隶属度的集合。一个模糊集和一个隶属函数相关。
类比于概率,隶属度描述了一个元素属于这个模糊集的程度/概率
例题:
从下列30条线段中选出长线段。设长度从1~30分别为30~1cm
解:由题意得
“长”是模糊概念,因此可以用模糊集来描述。设$A$表示“长线段”的集合,$xi,i=1,\cdots,30$表示第$i$条线段,则论域为$U={x_1,x_2,\cdots,x{30}}$。
则线段$x_i$作为集合$A$的成员的资格即为$x_i$对$A$的隶属度。因此建立集合$A$的一种隶属函数如下:
因为线段越长,则其属于$A$的程度越大,因此线段$A$的长短可以用于作为表示A的隶属度。
从而,令$A(x_1)=1,A(x_2)=0$,作直线:
故得到第$i$条线段$x_i$属于长线段集合$A$的隶属函数为:

B. 隶属函数
隶属函数是将元素映射到隶属度的函数,其建立了元素和模糊评价之间的联系例如,身高175cm和高之间,假设在当前人群中高个子人群构成的模糊集$A$的隶属函数为$\mu_A$,那么若$\mu_A(175)=0.87$,那么我们就可以认为175cm的身高在当前人群中是高的,即175cm的人属于模糊集$A$。我们也可以理解为175cm的身高在当前人群中有87%的概率是高的。
C. 模糊集的运算
由于模糊集中没有元素和集合间的绝对隶属关系,所以模糊集的运算是通过隶属函数完成的。
设集合$A$、$B$为两个模糊集,其隶属函数分别为$\mu_A(x),\mu_B(x)$,则集合$A$与$B$常见的运算为:
- 包含:$A\subseteq B \Leftrightarrow \forall x \in A, \mu_A(x)\leq \mu_B(x)$
- 相等:$A= B \Leftrightarrow \forall x \ in A, \mu_A(x) = \mu_B(x)$
- 交:$C=A\cap B \Leftrightarrow \mu_C(x) = \mu_A(x)\land \mu_B(x)$
- 并:$C=A\cup B \Leftrightarrow \mu_C(x) = \mu_A(x)\lor \mu_B(x)$
- 补:$A^c\Leftrightarrow\mu{A^C}(x)=1-\mu{A}(x)$
- 内积:$A\times B=\lor_{x\in U}(A(x)\land B(x))$
- 外积:$A\otimes B=\land_{x\in U}(A(x)\lor B(x))$
3. 隶属函数的确定
由模糊集的概念可知,模糊数学的基本思想是用隶属度代替绝对的属于还是不属于,所以应用模糊数学方法建立数学模型的关键是建立符合实际的隶属函数。然而,如何确定一个模糊集的隶属函数至今还是尚未完全解决的问题。
目前,确定隶属度的常用方法是模糊分布法。模糊分布法将隶属函数看成一种模糊 分布,首先根据问题性质选取适当的模 糊分布,然后再依据相关数据确定分布中的参数。
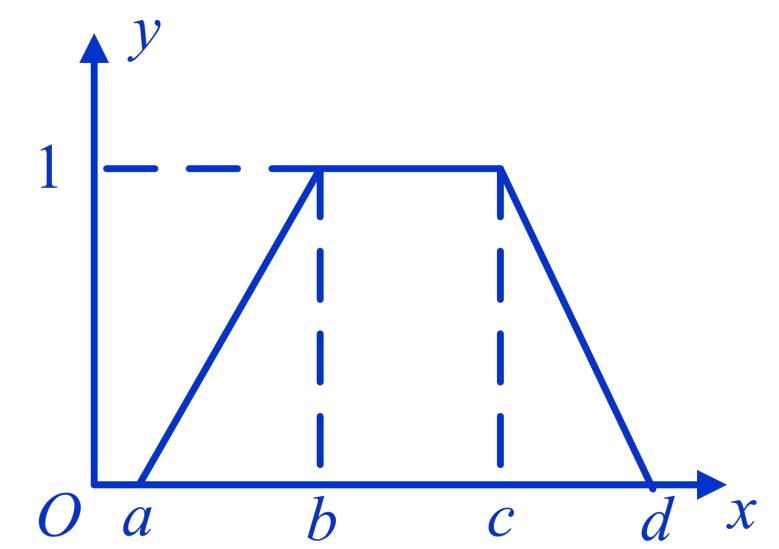
模糊分布中常用的梯形分布如下
A. 偏小型
偏小型指值越小越属于这个模糊集,对应的,其隶属函数如下:

B. 偏大型
偏大型指值越大越属于这个模糊集,对应的,其隶属函数如下

C. 中间型
中间型指值越大和越小都不属于这个模糊集,只有在中间的时候才属于这个模糊集,例如人群中不高不矮的人群。其隶属函数如下
4. 模糊综合评价法
评价是人类社会中经常性的、极为重要的认识活动。 对一个事物的评价通常要涉及多个因素或多个指标,评价是在多因素相互作用下的一种综合评判。
综合评价是数学建模竞赛中较为常见的问题, 如
- 长江水质的评价与预测(2005A)
- 艾滋病疗法的 评价及疗效的预测(2006B)
- 2010上海世博会影 响力的定量评估(2010B)
综合评价的方法众多,常用的有灰色评价法、 层次分析法、模糊综合评价法、数据包络分析法、 人工神经网络评价法、理想解法等。有时,还可将两种评价方法集成为组合评价方法。
各种评价方法出发点不同,解决问题的思路不同,适用对象不同,各有优缺点。不同的评价方法会产生不同的评价结论,有时甚至结论相左,即综合评价的结果不是唯一的。
而下面就将讲解其中的模糊综合评价法
A. 模糊综合评价法介绍
模糊综合评价作为模糊数学的一种具体应用,最早由我国学者汪培庄提出。基本思想是:以模糊数学为基础, 应用模糊关系合成原理,将一些边界不清、不易定量的因素定量化,从多个因素对被评价事物隶属等级状况进行综合评价。
具体步骤为:
- 首先确定被评价对象的因素集和评价集(例如对成绩进行评价,那么语文、数学、英语就是因素集,而优、良和几个是评价集)
- 然后再分别确定各因素的权重及它们的隶属度向量,获得模糊评价矩阵
- 最后将模糊评价矩阵与因素的权向量进行模糊运算并归一化,从而得到模糊评价综合结果。
模糊综合评价法简单易掌握,对多因素、多层次的复杂问题评价效果较好,很难为其它评价方法所替代。
B. 模糊综合评价法的步骤
1. 确定评价指标和评价等级(因素集和评价集)
设$U={u_1,u_2,\cdots,u_m}$为刻画被评价对象的$m$中因素(评价指标),$V={v_1,v_2,\cdots,v_n}$为刻画所有因素所处的状态的$n$种评语(评价等级)。
这里,$m$为评价因素的个数,通常由具体指标体系决定;$n$为评语的个数, 一般划分为3~5个等级。
某服装厂欲采用模糊综合评价法来了解顾客对某种服装的欢迎程度:
确定评价指标和评价等级
顾客是否喜欢某种服装,通常与这种服装的花色、样式、价格、耐用度和舒适度等因素有关,故确定评价服装的因素集为
综合评价的目的是弄清楚顾客对衣服各方面的欢迎程度,因此每个因素都可能受欢迎、不受欢迎等等。因此,评价集应为
2. 构造模糊综合评价矩阵
在确定了评价指标和评价等级后,接着就要对每个评价指标$u_i(i=1,\cdots,m)$ 逐一进行模糊评价。
具体评价方法是:
对评价指标$ui$给出其能被评为等级$v_j$的隶属度$r{ij}$。$r{ij}$可理解为指标$u_i$对于等级$v_j$的隶属度,通常要将$r{ij}$归一化以便于使用
设指标$ui$的模糊评价为$r_i = ( r{i1} , r{i2} , \cdots, r{in})$,则对所有评价指标$u_i(i=1,\cdots, m)$ 进行的模糊评价构成的矩阵$R$称为各指标的模糊综合评价矩阵。其中,
一般在真实问题中,隶属度$r_{ij}$可以通过频率法确定
某服装厂欲采用模糊综合评价法来了解顾客对某种服装的欢迎程度:
构造模糊综合评价矩阵
服装厂通过问卷调查,对该服装的花色进行调查,众多被调查者中有20%认为“很欢迎”, 50%认为“欢迎”,30%认为“一般” , 没有人认为“不欢迎”,则$u_1=花色$的评价向量为$R_1=(0.2, 0.5, 0.3, 0)$。同理,得到$R_2,R_3,R_4,R_5$,那么得到的模糊综合评价矩阵为
3. 评价指标权重的确定
确定了模糊综合评价矩阵,尚不足以对事物做出评价。原因在于,各评价指标在评价目标中有不同的地位和作用,即各评价指标在综合评价中占有不同的权重。
为此,通常引入一个模糊向量$A=(a_1 , a_2 ,\cdots,a_n)$ 来表示各评价指标在目标中所占权重,称之为$权重向量$。其中$a_i$为$u_i$的权重,$\sum a_i=1, a_i\ge 0$。
确定权重通常有主观和客观两类方法:
- 主观法的代表是层次分析法,即通过因素(层次分析法中的指标)的比较矩阵判断得出来一个权重向量
- 客观法是根据各指标间的联系,利用数学方法计算出各指标的权重,如质量分数法、变异系数法等。
变异系数法
变异系数法的设计原理是:若某项指标的数值差异较大,能明确区分开各被评价对象,说明该指标的分辨信息丰富,因而应给该指标以较大的权重;反之,若各个被评价对象在某项指标上的数值差异较小,那么这项指标区分各评价对象的能力较弱,因而应给该指标较小的权重
因为方差可以描述取值的离散程度,即某指标的方差反映了该指标的的分辨能力, 所以可用方差定义指标的权重。由于方差的大小是相对的,还需考虑指标取值的大小、量级,故指标的分辨能力可定义为
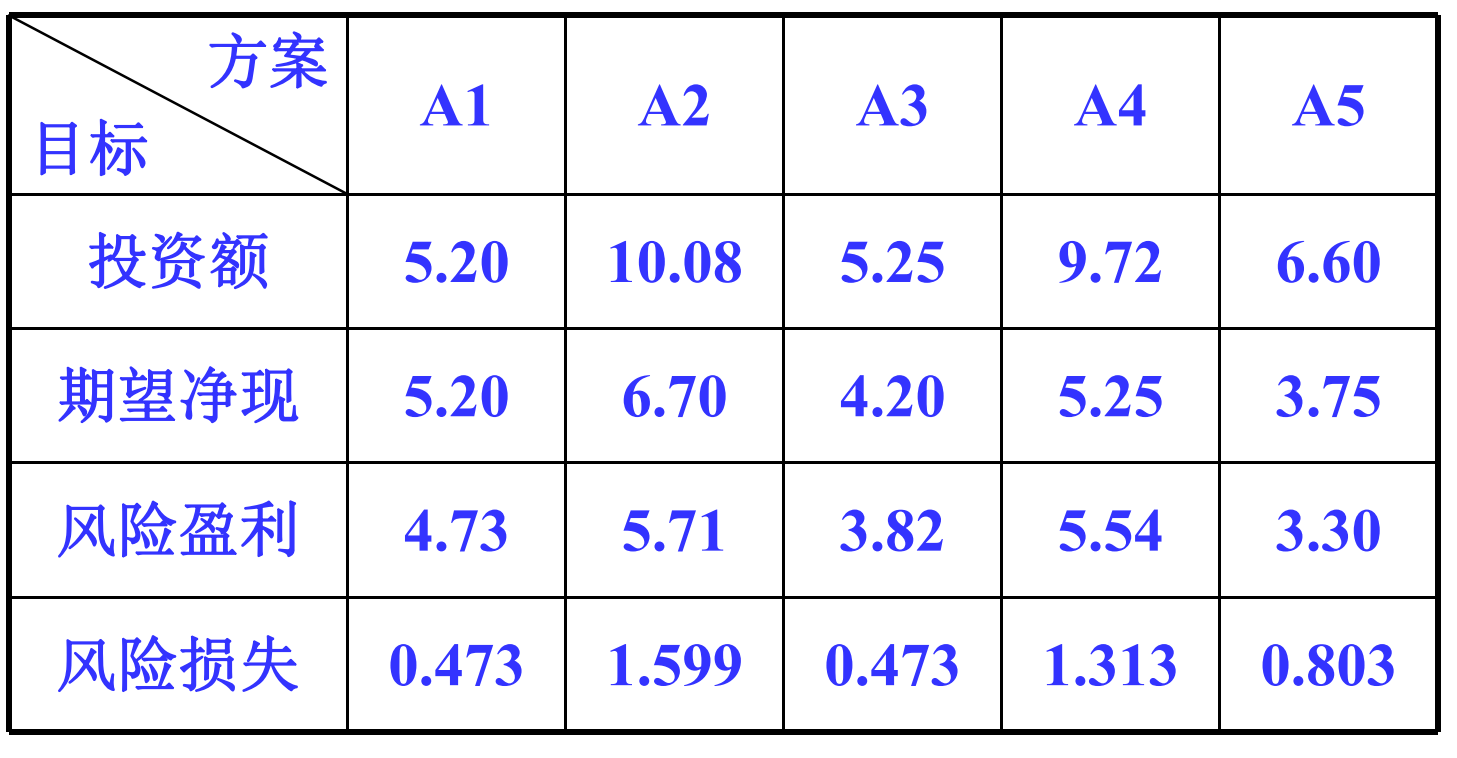
例:已知5个投资方案如下表,试确定4个评价指标的权重
解:根据变异系数法,可按照下列步骤 确定各指标的权重
计算第$i$项指标的均值与方差:
计算每个指标的分辨能力,取归一化后的分辨能力为各指标的权重
最终解得,四个指标的权重为:$w=(0.244, 0.172, 0.173, 0.412)$
需要指出的是,用变异系数法求出的某指标的权重与该指标在评价体系中的重要性是两个概念,变异系数法的作用只是提高指标的分辨能力,利于排序。因为变异系数法的权重计算是根据指标的分辨能力计算的。
其实,使用变异系数法的前提恰恰是所有指标在评价体系中的重要性相当。 也就是说,当指标在评价体系中的重要性相差较大时,使用变异系数法确定权重并不一定合适
4. 模糊合成与综合评价
模糊综合评价矩阵R中的不同行反映了被评价事物从不同的指标评价对各等级的隶属程度。用权向量A将不同的行进行综合,就可得到被评价事物从总体上对各等级的隶属程度,即模糊综合评价结果。
通常采用所谓的模糊合成来实现上述的综合。
模糊合成的基本思想是:对评价矩阵$R$和权向量$A$进行某种适当的模糊运算, 将两者合成为一个模糊向量$B={b_1,b_2,\cdots,b_n}$, 即$B=A M R$,$M$为模糊合成算子然后对B按照一定法则进行综合分析后即可得出最终的模糊综合评价结果。
常见的模糊合成算子有:
- 主因素突出型:$M(\land, \lor):bj=\lor{i=1}^m(ai\land r{ij})$
- 主因素突出型:$M(\cdot, \lor):bj=\lor{i=1}^m(ai\cdot r{ij})$
- 加权平均型:$M(\land, \oplus):bj=\sum{i=1}^m(ai\land r{ij})$
- 加权平均型:$M(\cdot, \oplus):bj=\sum{i=1}^m(ai\cdot r{ij})$
注意,算子是对矩阵沿列计算的,相当于A右乘R,同时使用算子。即np.apply_along_axis(axis=1)
上述模糊合成算子的特点如下:
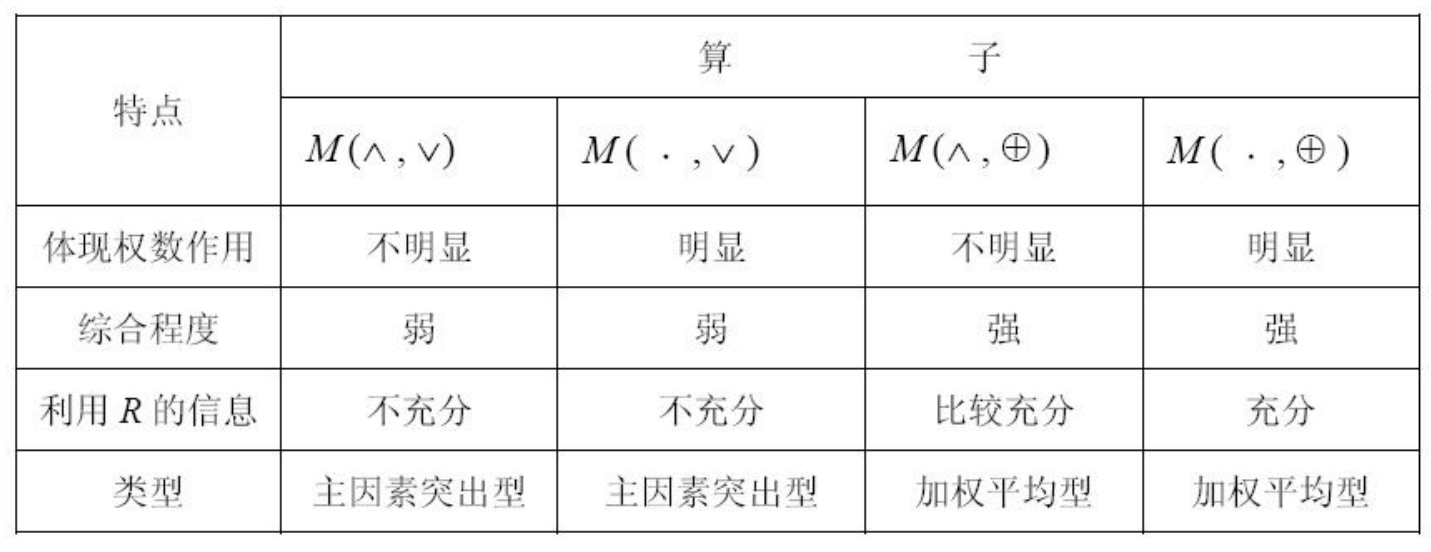
此外,也可以取M为普通的矩阵乘法, 此时合成即为加权平均。至于到底取何种算子取决于问题的性质和算子的特点。
通常而言,采用主因素突出型和加权平均型算法的结果大同小异。但在实际中还是要注意这两类算法的特点:
- 主因素突出型适用于模糊矩阵中数据相差很悬殊的情形
- 加权平均型则常用于因素很多的情形,可以避免信息丢失
此外,上面的$B$全称为模糊综合评价向量,满足$0\leq b_j \leq 1$,且$b_j$需要进行归一化。$b_j$可以理解为被评价对象对第$j$等级的隶属度。
对$B$分析处理后即可获得综合评价结果。分析处理$B$的常用方法有:
最大隶属度法:即认定被评价对象的等级为最大隶属度对应的等级, 适用于某隶属度明显大于其它隶属度的情形
加权平均法:具体方法是,给定评价集$V={v_1 ,v_2 ,\cdots,v_n}$中的各等级赋以适当的分值$C={c_1,c_2,\cdots,c_n}$,用归一化的综合评价向量$B={b_1,b_2,\cdots,b_n}$对C的加权平均,得到的值就是模糊综合评价的结果,即:
例如, 设评价等级集为${很好, 好, 一 般, 差}$,综合评价向量$B=[0.4, 0.3, 0.2, 0 . 1 ]$。
- 按最大隶属度法,评价等级为 “很好”。
- 若给评价集分别赋值$[4, 3, 2, 1]$,则加权平均值为4 * 0.4 + 3 * 0.3 + 2 * 0.2 + 1 * 0.1 = 3.0,评价为好
C. 模糊综合评价法的案例
教师教学评价
在教学过程的综合评价中,取因素集$U={清楚易懂, 教材熟悉, 生动有趣, 板书整齐清晰}$,评价集 $V={很好, 较好, 一般,不好}$。设某班学生对教师的教学评价矩阵为
若考虑评价集的权重$A=(0.5, 0.2, 0.2, 0.1)$,试求学生对这位教师的综合评价。
解:
根据A和R,利用四种合成算子, 编程计算得
可以看出,第二列较大而第三列较小,因此就认为老师0.3左右是很好的老师,0.4左右是较好的老师,0.2左右是不好的老师,0.06左右是不好的老师


D. 模糊综合评价矩阵的获得
上面举得例子简单明了,然而上面的例子实在是太过于简单,因为不仅给出了模糊综合评价矩阵$R$,而且还直接给出了权重向量$A$。实际问题往往只提供了一系列的评价对象以及每个对象的若干评价指标,并且这些指标可能数值差异很大,性质也不同。
此时,不仅指标的权重向量$A$需要根据适当的方法确定,就连评价矩阵$R$也要按照某种方法对评价指标进行处理后才能获得。
- 确定权重向量$A$的常用方法是前面介绍的变异系数法
- 而处理评价指标获取评价矩阵$R$的常用方法除了前面的评论法以外,还有:相对偏差法和相对优属度法
1. 相对偏差模糊矩阵评价法
相对偏差模糊矩阵评价法与灰色关联分析有点类似。首先虚拟一个理想方案$u$,然后按照某种方法建立各方案与$u$的偏差矩阵$R$,再确定各评价指标的权重$A$,最后用$A$对$R$加权平均得各方案与$u$的综合距离$F$,则根据$F$即可对方案进行排序即可。
相对偏差法评价法的基本步骤如下:
虚拟理想方案:
其中,即越多越好的取最大值,越少越好的取最小值
建立相对偏差模糊矩阵$R$
其中,$a_{ij}$为收集得到的数值
确定各评价指标权重$w_i$
对各方案的偏差加权平均
根据$F_j$值进行综合评价:若$F_t$<$F_s$,则第$t$个方案排在第$s$个方案之前
技术方案评价
现有下列5个农业技术经济方案,试评价各方案的优劣。
解:
上述评价指标中,产量、肥力是效益型,而其余均为成本型。
理想方案为:
根据前述方法求出相对偏差模糊矩阵
由变异系数法求出指标权重
得到指标权重为
求加权平均偏差并排序
故方案的优劣次序为1、3、2、4、5。



2. 相对优属度模糊矩阵评价法
相对偏差法的评价依据是各方案与理想方案的偏差,而相对优属度评价法的基本思想是:首先用适当的方法将所有指标(效益型、 成本型、固定型)转化为效益型(成本型),得到优属度矩阵$R$,再确定各评价指标的权重$A$,最后用$A$对$R$加权平均得各方案的综合优属度$F$, 则根据$F$即可对方案进行排序
相对优属度评价法步骤如下:
建立模糊效益矩阵$R_{ij}$ ,其中$\alpha_j$是第$j$个指标的适度值
确定各评价指标权重$w_i$
对各方案的偏差加权平均
根据$F_j$值进行综合评价:若$F_t>F_s$,则第$t$个方案排在第$s$个方案之前
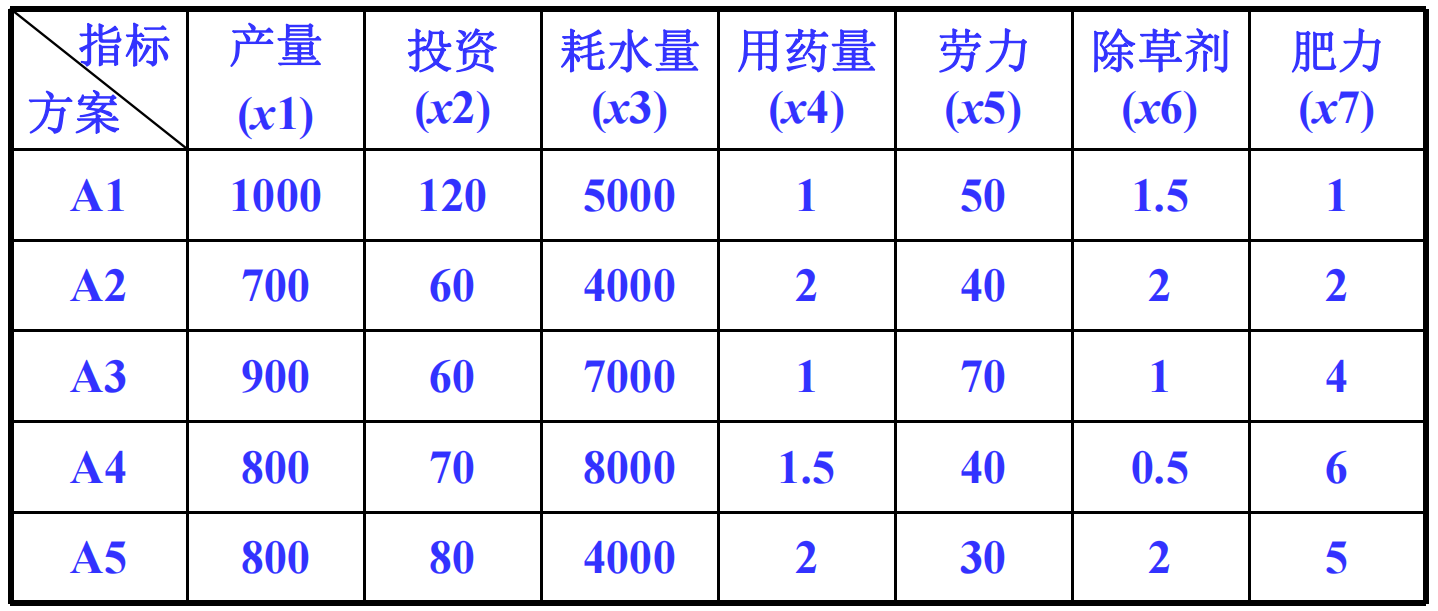
投资方案评价
已知5个投资方案如下表,试确定4个评价指标的权重
解:
4个指标中,投资额、风险损失为成本型,期望净现值、风险盈利值为效益型
按前述方法建立相对优属度模糊矩阵
由变异系数法求出指标权重
各方案的加权平均优属度
故方案排序为1, 3, 5, 2, 4



5. 灰色关联分析、相对偏差法以及相对优属度法的讨论
我们在前面介绍了灰色关联分析,这里又介绍了相对偏差法和相对优属度法。三者尽管具体的步骤不同,但是其核心思想都是一致的,即:找出当前评价体系下最优的方案,然后将现有的方案和最优的方案进行比较,以偏差最小的方案作为最佳方案。
因此,我们自然就会有一个问题:这三种方法评价同一问题的结论完全一致吗?
针对上面的投资方案
- 相对偏差法的方案排序为:1、3、5、4、2
- 相对优属度法的排序为:1、3、5、2、4
- 灰色关联分析:1、3、2、4、5
针对上面的农业技术方案:
- 相对偏差法的方案排序为:1、4、2、3、5
- 相对优属度法的排序为:1、3、2、4、5
- 灰色关联分析:1、3、2、5、4
对于相对偏差法和相对优属度法而言,两者的因素(指标)的权重的计算是依靠变异系数法求得的,而灰色关联分析中我们最后实际上没有乘以权重矩阵,而是把每个指标当做同等重要对待,因此会存在不同
此外,三者中间得到评价矩阵的方式不同,灰色关联分析是用最大和最小的偏差来描述的,而相对偏差则是偏差,相对优属度法通过函数(等效优属度)。
因此上述两个原因就是导致三个方法排序得到的指标并不相同的结果,因此:
- 灰色关联分析法、相对偏差法和相对优属度法对同一问题的评价、排序结果不尽相同;
- 当各指标在评价体系重要性相当时,用变异系数法确定指标权重,可提高上述方法排序的分辨率
- 当各指标在评价体系重要性差异较大时,可考虑用层次分析法确定指 标权重
- 在实际中, 对于评价类问题,应同时应用上述几种方法进行综合评价, 以提高评价的可靠性