本文主要介绍了数学建模中常见的算法(数据处理方法):插值以及拟合
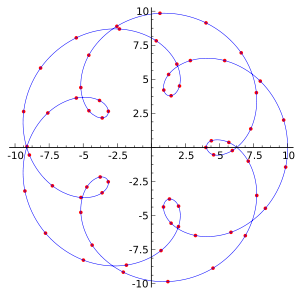
PS:图的含义一组离散数据点在一个外延的插值。曲线中实际已知数据点是红色的;连接它们的蓝色曲线即为插值。
数学建模算法7-一维二维插值以及拟合
严格意义上来说,和前面介绍的各种算法不同,插值和拟合都是数据处理的手段。而由于这个系列介绍的就是数学建模中常用的知识,包括了常用算法、常用问题和常用技巧,因此也一并介绍。
在数学建模的过程中,经常出现的一类操作就是需要对数据进行补全以及外推。例如下面的例子


从表象上来看,第一个例子中,我们需要的数据在已有的数据范围内,而第二个例子中我们需要的数据并不在已有的数据范围内,两个问题分别对应插值问题和拟合问题。其实更一般的,插值寻求得到函数解析式而拟合寻求得到趋势的解析式。之间的规律。
插值和拟合最大的区别在于,插值那就一定得过数据点。拟合,就是要得到最接近的结果,是要看总体效果,因此不一定过所有的数据点。例如下面的图中,左边一列是插值而右边的一列是拟合。

借用知乎上的回答:
最小二乘意义下的拟合,是要求拟合函数与原始数据的均方误差达到极小,是一种整体意义的逼近,对局部性质没有要求。而所谓“插值”,就是要在原有离散数据之间“插入”一些值,这就要求插值函数必须通过所有的离散点,插值函数在离散点之外的那些点都相当于“插入”的值。插值有全局插值,也有局部插值(比如分段线性插值),插值误差通常考虑的是逐点误差或最大模误差,插值的好坏往往通过某些局部的性质来体现,比如龙格现象或吉布斯振荡。
作者:李晓
链接:https://www.zhihu.com/question/24276013/answer/32942153
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
一、插值
先来看看一些插值的问题

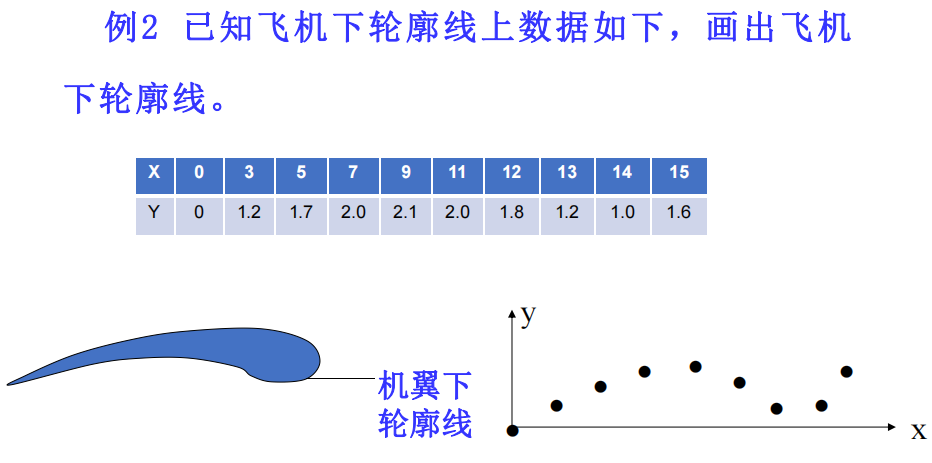

这些问题可归结为:已知函数在某区间 (域)内若干点处的值,求函数在该区间(域)内其它点处的值。这种问题适宜用插值方法解决。
因此,将一维插值问题描述为:
由于泰勒定理,对于一个足够光滑的函数,可以用一个多项式函数来表示。因此一般将$p(x)$取为多项式。
此外,由范德蒙行列式和克莱姆法则可以证明,使得在$x_0,x_1,\cdots,x_n$处取值$y_0,y_1,\cdots,y_n$的多项式存在且唯一。因此插值问题一定有解,因为至少有一个多项式的解。
1. 插值的介绍
关于插值,形象的理解就是在前面所说的,根据已有的数据生成得到已经采集到的数据域内的未采集的数据点。更加严谨的定义见下面百度百科和维基百科的介绍
From BaiduBaike:
在离散数据的基础上补插连续函数,使得这条连续曲线通过全部给定的离散数据点。 插值是离散函数逼近的重要方法,利用它可通过函数在有限个点处的取值状况,估算出函数在其他点处的近似值。
From Wikipedia:
在数学的数值分析领域中,内插,或称插值(英语:Interpolation),是一种通过已知的、离散的数据点,在范围内推求新数据点的过程或方法。求解科学和工程的问题时,通常有许多数据点借由采样、实验等方法获得,这些数据可能代表了有限个数值函数,其中自变量的值。而根据这些数据,我们往往希望得到一个连续的函数(也就是曲线);或者更密集的离散方程与已知数据互相吻合,这个过程叫做拟合。
与插值密切相关的另一个问题是通过简单函数逼近复杂函数。假设给定函数的公式是已知的,但是太复杂以至于不能有效地进行评估。来自原始函数的一些已知数据点,或许会使用较简单的函数来产生插值。当然,若使用一个简单的函数来估计原始数据点时,通常会出现插值误差;然而,取决于该问题领域和所使用的插值方法,以简单函数推得的插值数据,可能会比所导致的精度损失更大。


2. 常见的插值方法
A. 最邻近插值
最邻近插值即指使用最邻近的已采集的数据的值作为需要的点处的值
B. 线性插值
线性插值通过已知点计算得到一个线性函数,从而通过线性函数来获得未知点的值
C. 样条插值
样条函数指一种特殊的函数,由分段的多项式定义。样条插值即指分区间用多个低次多项式进行拟合
D. 多项式插值
对于$n$个点,选择一个高次的多项式来经过所有点。二次插值、三次差值都是多项式插值的特例。
E. 拉格朗日插值(Lagrange Interpolation)
拉格朗日插值法(Lagrange Interpolation) 指的是在节点上给出节点基函数,然后通过基函数的线性组合,组合系数为节点函数值的一种插值方法。
例如现在需要对下面的三个点进行插值
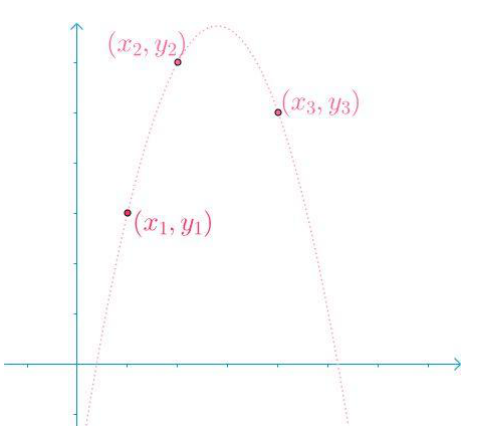
虽然我们可以写一个多项式$f(x)=ax^2+bx+c$,然后去通过$(x_1,y_1),(x_2,y_2),(x_3,y_3)$这三个点获得三个式子,然后求解出来$a,b,c$三个系数即可。
然而这样做比较麻烦,因此拉格朗日插值法找到了分别通过$(x_1,y_1),(x_2,y_2),(x_3,y_3)$三个点的基函数,而基函数在其他点处的值为0。例如,通过$(x_1,y_1)$的基函数$f_1(x)$满足$f_1(x_1)=y\land f_1(x_2)=0 \land f_1(x_3)=0$。然后将三个基函数叠加即可。
在具体实操作上则找的是$f_1(x_1)=1\land f_1(x_2)=0 \land f_1(x_3)=0$,这样就可以设表达式是$f_1(x)=a(x-x_2)(x-x_3)$,然后带入$x_1,y_1)$求出$a$即可。
因此对于上面的例子,找到的基函数分别为下面三个:

那么最终通过插值得到的表达式为
进一步,对于$n$个点进行拉格朗日插值法得到的表达式为
3. 高次差值的Runge现象
在研究插值问题的初期,所有人都想当然地认为(使用多项式插值的时候)插值多项式的次数越高,插值精度越高。然而Runge 通过对一个例子的研究发现, 上述结论仅仅在插值多项式的次数不超过七时成立;插值多项式的次数超过七时, 插值多项式会出现严重的振荡现象,称之为Runge现象。
例如我们下面对$f(x)=\frac 1 {1+25x^2}$从-1到1均匀的采点,然后用一个10次的多项式去拟合的结果。可以看到在中间(-0.2~0.2)拟合的还不错,可是越往两边越离谱,甚至只能保证曲线一定过这个点。

然而若使用多项式插值,那么由于需要插值的点越来越多,多项式的次数一定会越来越高。因此为了解决龙格现象,使用分段的方式进行插值。即将所有的点分成多个区间,每个区间内用低次多项式进行插值,然后在区间的交界处通过二阶导连续等手段使得多个区间得到的多项式之间连续。例如上面介绍的样条插值。一般来说,为了所取得多项式次数最好少于7。
对上面的式子进行样条插值得到的结果如下:

4. Python中的插值
Python中的插值使用SciPy中的interpolate模块完成。
下面的内容主要参考博客:https://zhuanlan.zhihu.com/p/136700122
A. 一维插值
一维插值指的是自变量是一个标量,我们前面举得例子都是一维插值。
一维插值主要使用scipy.interpolate.interp1d类实现,其签名如下
class scipy.interpolate.interp1d(x, y, kind='linear', axis=- 1, copy=True, bounds_error=None, fill_value=nan, assume_sorted=False)
其中,我们需要关注的有:
- x,y:需要插值的x和y的值
- kind:插值方式,所有可选项为:‘linear’, ‘nearest’, ‘nearest-up’, ‘zero’, ‘slinear’, ‘quadratic’, ‘cubic’, ‘previous’, or ‘next’。默认为线性插值
注意,该类实现了call方法,因此直接call即可
import numpy as np
import scipy.interpolate as scinterp
import matplotlib.pyplot as plt
x = np.linspace(0, 3 * np.pi, 11)
y = np.sin(x)
x_a = np.linspace(0, 3 * np.pi, 1000)
f = scinterp.interp1d(x, y)
y_a = f(x_a)
print(type(f))
plt.plot(x, y)
plt.plot(x_a, y_a)
plt.show()
B. 二维插值
二维插值指的是自变量是一个具有两个分量的向量。虽然我们前面讲的都是一维插值的方法,其实对于二维插值,只需要对两个分量分别进行插值即可,即双xxx插值,例如双线性插值。
Python中实现二维插值主要使用scipy.interpolate.interp2d类实现,其签名如下
class scipy.interpolate.interp2d(x, y, z, kind='linear', copy=True, bounds_error=False, fill_value=None)
其中,需要关注的参数为:
- x, y:二维的点,要么是类似MATLAB的mesh一样的网格点,要么是两个等长的Numpy数组表示点的x,y坐标。
- z:二维点对应的值
- kind:插值方法,可选的选项有:‘linear’, ‘cubic’, ‘quintic’
最后,一般来说一维插值用样条插值而二维插值用立方插值
二、拟合
在插值问题中要求得到的函数解析式过所有数据点。然而再很多时候,数据量一大,这个时候插值得到的函数解析式无论怎么样都会很复杂。还有很多时候数据是没有解析式的。而且通过插值得到的函数的龙格现象和吉布斯震荡导致在数值域外的震荡非常大,往往使用插值得到的函数只能确保在数值域内的值可信而对数值域外的值不是非常可信。因此针对这种情况,我们就通过拟合来完成。
拟合的目的在于找出数据间的近似函数,其:
- 拟合函数不一定过所有数据点
- 插值主要求函数值,而拟合主要求函数关系,从而进行进一步的预测
拟合的难点在于两个关键点:
- 拟合曲线的线型选择
- 线型中参数的计算
通常而言,线型的选择依靠专业知识(先验知识)和散点图;而参数的计算,若为线性拟合则用最小二乘法,非线性拟合则用Gauss-Newton迭代法。
1. Python中的拟合
Python中的拟合主要依靠Numpy、Scipy中的函数
A. 多项式拟合
多项式拟合主要使用Numpy中的polyfit函数,其函数签名如下
numpy.polyfit(x, y, deg, rcond=None, full=False, w=None, cov=False)
其中,我们需要关注的为:
- x, y: 需要拟合的数据的x和y的值
- deg:拟合的多项式次数
返回值为Numpy中的ndarray,分比为从高到低次的项的系数
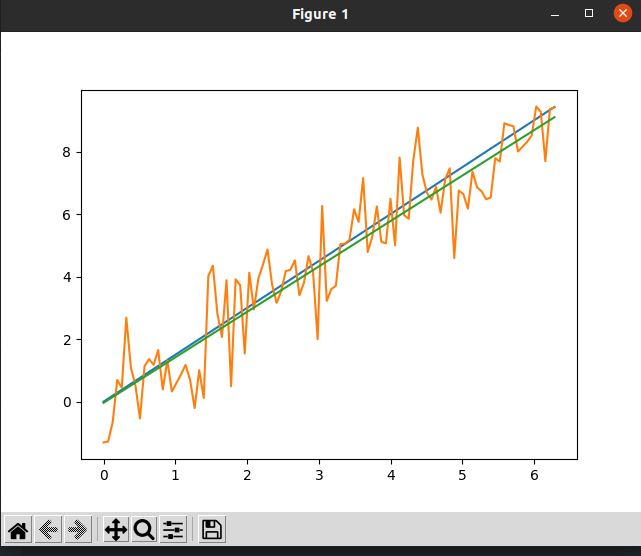
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
x = np.linspace(0, 2 * np.pi, 100)
y = 1.5 * x
y_noise = y + np.array([np.random.randn() for i in range(len(y))])
coeff = np.polyfit(x, y=y_noise, deg=1)
plt.plot(x, y)
plt.plot(x, y_noise)
plt.plot(x, x * coeff[0] + coeff[1])
plt.show()