本文主要介绍了数学建模中常见的评价方法:层次分析法

数学建模算法5-层次分析法
层次分析法是数学建模中非常常用的算法之一,通过层次分析法,我们能够完成对一个复杂的问题的定性与定量分析,并且在分析的同时做出决策。
1. 层次分析法介绍
层次分析法(Analytic Hierarchy Process,AHP)是美国运筹学家匹茨堡大学教授萨蒂(T.L.Santy)于上世纪70年代初,为美国国防部研究《根据各个工业部门对国家福利的贡献大小而进行电力分配》课题时,应用网络系统理论和多目标综合评价方法,提出的一种层次权重决策分析方法。
这种方法的特点是在对复杂的决策问题的本质、影响因素及其内在关系等进行深入分析的基础上,利用较少的定量信息使决策的思维过程数学化,从而为多目标、多准则或无结构特性的复杂决策问题提供简便的决策方法。是对难于完全定量的复杂系统作出决策的模型和方法。
简单的说,其优点在于:
- 可以使用少量的信息(数据)来指导进行决策,相比于以往的其他模型,他们都是完全的定量化的,因此需要大量的数据。
- 层次分析法非常善于对不易于定量的问题进行分析。
人们在对社会、经济以及管理领域的问题进行系统分析时,面临 的经常是一个由相互关联、相互制约的众多因素构成的复杂系统。 层次分析法则为研究这类复杂的系统,提供了一种新的、简洁的、 实用的决策方法。
层次分析法是一种解决多目标的复杂问题的定性与定量相结合的决策分析方法。
该方法将定量分析与定性分析结合起来, 用决策者的经验判断各衡量目标能否实现的标准之间的相对重要程度,并合理地给出每个决策方案的每个标准的权数,利用权数求出各方案的优劣次序,从而比较有效地应用于那些难以用定量方法解决的课题。
层次分析法是社会、经济系统决策中的有效工具。其特征是合理地将定性与定量的决策结合起来,按照思维、心理的规律把决策过程层次化、数量化。是系统科学中常用的一种系统分析 方法。
该方法自1982年被介绍到我国以来,以其定性与定量相结合地 处理各种决策因素的特点,以及其系统灵活简洁的优点,迅速地在我国社会经济各个领域内,如工程计划、资源分配、方案 排序、政策制定、冲突问题、性能评价、能源系统分析、城市 规划、经济管理、科研评价等,得到了广泛的重视和应用。
层次分析法的三大运用:
- 用于最佳方案的选取(选择运动员、选择地址)
- 例如四个远动员A、B、C、D,我们分别从耐力、爆发、敏捷几个因素去评价运动员的好坏
- 例如医院选址,那么对多个不同的地点,可以从低价、人口密度等因素评价医院选址的好坏
- 用于评价类问题(评价水质状况、评价环境)
- 同上
- 用于指标体系的优选(兼顾科学和效率)
- 例如现在有9个指标,要从中选取出来6个指标,那么对指标剔除评价标准,例如科学性和效率性
2. 层次分析法的基本原理
A. 决策
决策是指在面临多种方案时需要依据一定的标准选择某一种方案。 日常生活中有许多决策问题。例如:
- 在海尔、新飞、容声和雪花四个牌号的电冰箱中选购一 种。要考虑品牌的信誉、冰箱的功能、价格和耗电量。
- 在泰山、杭州和承德三处选择一个旅游点。要考虑景点 的景色、居住的环境、饮食的特色、交通便利和旅游的费用。
- 在基础研究、应用研究和数学教育中选择一个领域申报 科研课题。要考虑成果的贡献(实用价值、科学意义),可行性 (难度、周期和经费)和人才培养
- 在小丽、小美、小静中选择一个适合自己的女朋友。要 考虑基本颜值,身材比例、教育程度、家境情况、地域关系等
B. 基本原理
层次分析法根据问题的性质和要达到的总目标,将问题分解为不同的组成因素,并按照因素间的相互关联影响以及隶属关系将因素按不同层次聚集组合,形成一个多层次的分析结构模型,从而最终使问题归结为最低层(供决策的方案、措施等)相对于最高层(总目标)的相对重要权值的确定或相对优劣次序的排序。
3. 层析分析法的步骤和方法
运用层次分析法构造系统模型时,大体可以分为以下四个步骤:
- 建立层次结构模型
- 构造判断(成对比较)矩阵
- 层次单排序及其一致性检验
- 层次总排序及其一致性检验
A. 建立层次结构模型
在这一层,我们将决策的目标、考虑的因素(决策准则)和决策对象按它们之间的相互关系分为最高层、中间层和最低层,绘出层次 结构图。一般来说,三层分别是:
- 最高层:决策的目的、要解决的问题。比如去旅游
- 最低层:决策时的备选方案。比如去桂林还是去西安还是去浙江
- 中间层:考虑的因素、决策的准则。预算、想去的景区等等
此外,对于相邻的两层,称高层为目标层,低层为因素层。
举例来说,
大学毕业生就业选择问题:获得大学毕业学位的毕业生,在“双向选择”时,用人单位与毕业生都有各自的选择标准和要求。就毕业生来说选择单位的标准和要求是多方面的,例如:
- 能发挥自己才干作出较好贡献(即工作岗位适合发挥自己的专长)
- 工作收入较好(待遇好)
- 生活环境好(大城市、气候等工作条件等)
- 单位名声好(声誉等)
- 工作环境好(人际关系和谐等)
- 发展晋升机会多(如新单位或前景好)等
那么根据上面的指标,绘制得到的层次结构图为:
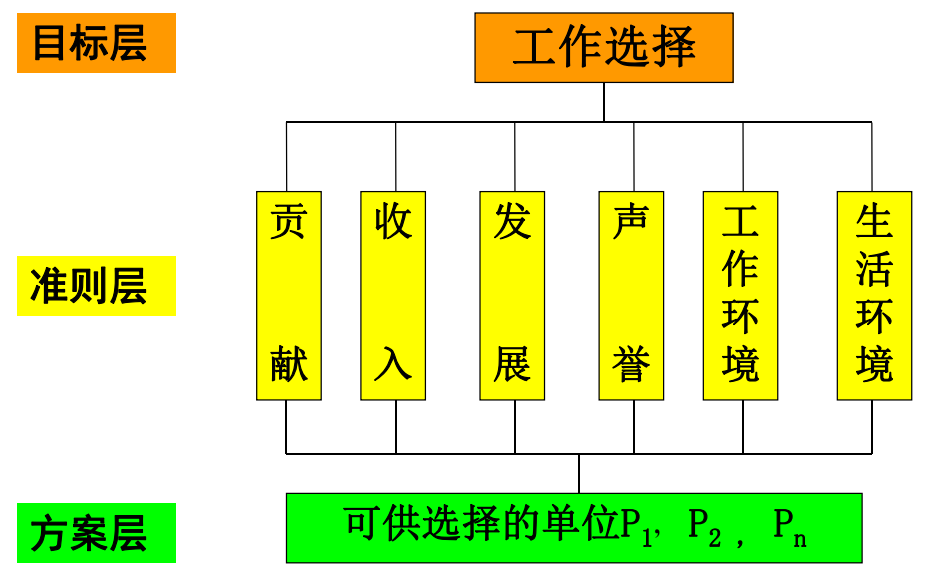
选择旅游目的地:在3个目的地中按照景色、费用、居住条件等因素选择最终前往的城市

因此,第一步建立层次结构模型的整个思维过程的归纳如下:
- 将决策问题分为3个或多个层次
- 最高层:目标层,表示解决问题的目的,即层次分析要达到的总目标。通常只有一个总目标。
- 中间层:准则层、指标层、……。表示采取某种措施、政策、方案等为了实现预定总目标所涉及的中间环节;根据指标的不同,可以是准则层、指标层、 策略层、约束层等。
最低层:方案层。表示将选用的解决问题的各种措施、政策、方 案等。通常有几个方案可选。
每层有若干元素,层间元素的关系用相连直线表示。
- 层次分析法所要解决的问题是关于最低层对最高层的相对权重问题,按此相对权重可以对最低层中的各种方案、措施进行排序,从 而在不同的方案中作出选择或形成选择方案的原则。即我们首先给目标层和准则层之间有一个权重向量,然后方案层中的每一个方案都有一个准则层对应的得分向量。两个向量相乘得到得分,那么我们就可以根据得分进行排序,获得初步的方案
B. 构造判断(成对比较)矩阵
在确定各层次各因素之间的权重时,如果只是定性的结果,则 常常不容易被别人接受,因而Santy等人提出:一致矩阵法,即:
- 不把所有因素放在一起比较,而是两两相互比较。即所有中间层的准则/因素间进行两两比较
- 对此时采用相对尺度,以尽可能减少性质不同的诸因素相互比较的困难,以提高准确度。即使用谁更重要,谁更不重要这样的判断,而非谁比谁好多少,谁比谁好几倍。例如身高的比较,用高一点,高很多这种,而非高1.7厘米
判断矩阵是表示本层所有因素针对上一层某一个因素的相对重要性的比较。判断矩阵的元素$a_{ij}$用Santy的1—9标度方法给出。
注意,心理学家认为成对比较的因素不宜超过9个,即每层不要超过9个因素。
而具体的1-9的标度的具体的含义如下:

此外,指标1对于指标2的标度为5,那么指标2对指标1的标度为$\frac 1 5$。
例如对于旅游目的地选取问题,我们根据前一步的得到的准则层,对其中的准则之间进行两两比较,得到下面的判断矩阵

但其实此时得到的判断矩阵是有问题,例如有$\frac {C_1}{C_2}=\frac 1 2$,而$\frac{C_2}{C_3}=7$,那么$\frac{C_1}{C_3}=\frac 7 2$,但是上述我们给出的$\frac {C_1}{C_3}$却是4,因此是存在不一致问题。
因此,在判断矩阵中,允许不一致,但要确定不一致的允许范围
若矩阵中任意三个相关联的数字是一致的,即$a{ik}\cdot a{kj}=a_{ij}$,那么此时称对比矩阵为一致阵,反之为不一致阵。
一致阵的性质有:
- A的秩为1,A的唯一非零特征根为n,即矩阵的行/列数。($A\vec w=n\vec w$)
- 非零特征根n所对应的特征向量归一化后可作为权向量
而对于不一致(但在允许范围内)的成对比较阵A, Santy等人建议用对应于最大特征根的特征向量作为权向量
而允许范围的判断及界定则由第三步完成
C. 层次单排序以及其一致性检验
注意,如果是一致阵的话,权重向量已经获得,而第三步都是针对不一致阵的。
1) 层次单排序
所谓层次单排序,即指对特征根最大的特征向量中的分量进行归一化操作之后,让各元素的值的和为1的过程。而归一化之后的向量记为$W$。
因为$W$的元素为同一层次因素对于上一层次因素相对重要性的排序权值,这一过程称为层次单排序。
2) 一致性检验
然而我们在这里其实还并不知道我们的不一致阵的不一致程度是否在允许范围内,因此需要对这里层次单排序之后的权向量进行一致性检验。即衡量一个不一致阵的不一致性,然后根绝量化后的不一致性进行判断。衡量不一致性,其实可以用不一致阵和一致阵的偏差来进行描述,因此要借助下面的两个定理:
- 定理一:$n$阶一致阵的唯一非零特征根为$n$
- 定理二:$n$阶正互反阵$A$的最大特征根$\lambda\ge n$, 当且仅当$\lambda=n$时,A为一致阵
因此就可以通过衡量$\lambda$与$n$的关系来描述$A$的不一致性。即由于$\lambda$连续的依赖于$a_{ij}$,则$\lambda$比$n$ 越大,$A$的不一致性越严重。则此时用最大特征值对应的特征向量作为被比较因素对上层某因素影响程度的权向量,其不一致程度越大,引起的判断误差越大。 因而可以用$\lambda-n$数值的大小来衡量$A$的不一致程度。
因此,定义不一致性指标$CI$:
因此,有
- $CI$等于0,有完全的一致性
- $CI$接近于0,有满意的一致性
- $CI$越大,不一致越严重
因此衡量一个不一致阵是否是可以接受的,关键就是看这个不一致阵的$CI$是否在某个范围内。因此关键就在于选取这个范围。又已知$CI=0$表示完全的一致性,因此其实只需要得到一个大于0的上界即可。
为了获得这个上界,那么可以通过和随机构造的随机矩阵的CI的值进行比较,来衡量我们给出的非一致判断阵和随机给出的判断阵之间的关系,从而衡量我们给出的判断阵是否合理,若合理即表示虽然不一致,但是在允许范围内。
因此,引入入随机一致性指标$RI$。$RI$的计算方法如下:
随机构造500个的成对比较矩阵$A1$,$A_2$,……,$A{500}$
对每个大小的矩阵计算$CI$,得到$CI_i,i=1,\cdots,500$
得到$RI$,计算公式如下:
对不同大小的判断镇分别计算RI,得到下表
| N | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| RI | 0 | 0 | 0.58 | 0.90 | 1.12 | 1.24 | 1.32 | 1.41 | 1.45 | 1.49 | 1.51 |
然后再定义一致性比率$CR$:
那么当$CR$小于0.1的时候,认为不一致阵A的不一致程度在允许范围内,有满意的一致性,通过了一致性检验,可以使用最大特征值对应的特征向量归一化之后的结果作为权向量。否则重新构造判断矩阵。
继续上面的旅游的例子,我们对其进行一致性检验。
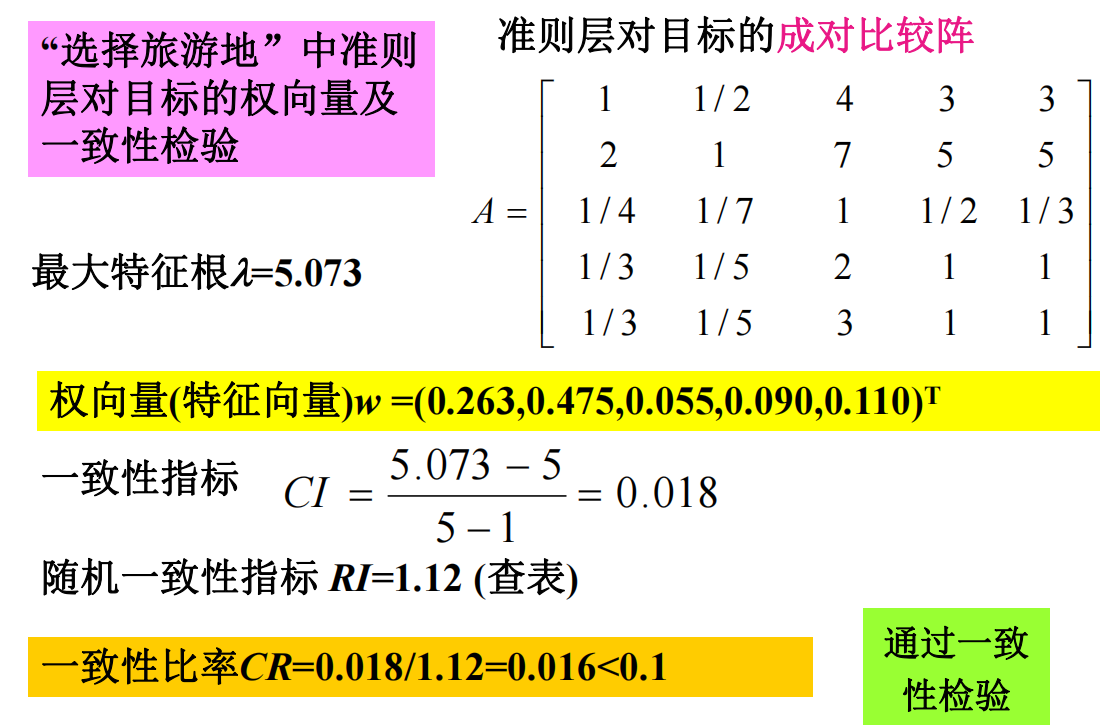
因此,旅游问题中对我们给出的判断矩阵可以得到从我们的观点出发,每个因素的得分向量为:
因此,在我们看来,费用是我们在考虑目的地时候最重要的因素,接下来是景色,最后是旅途、饮食和居住
D. 层次总排序以及其一致性检验
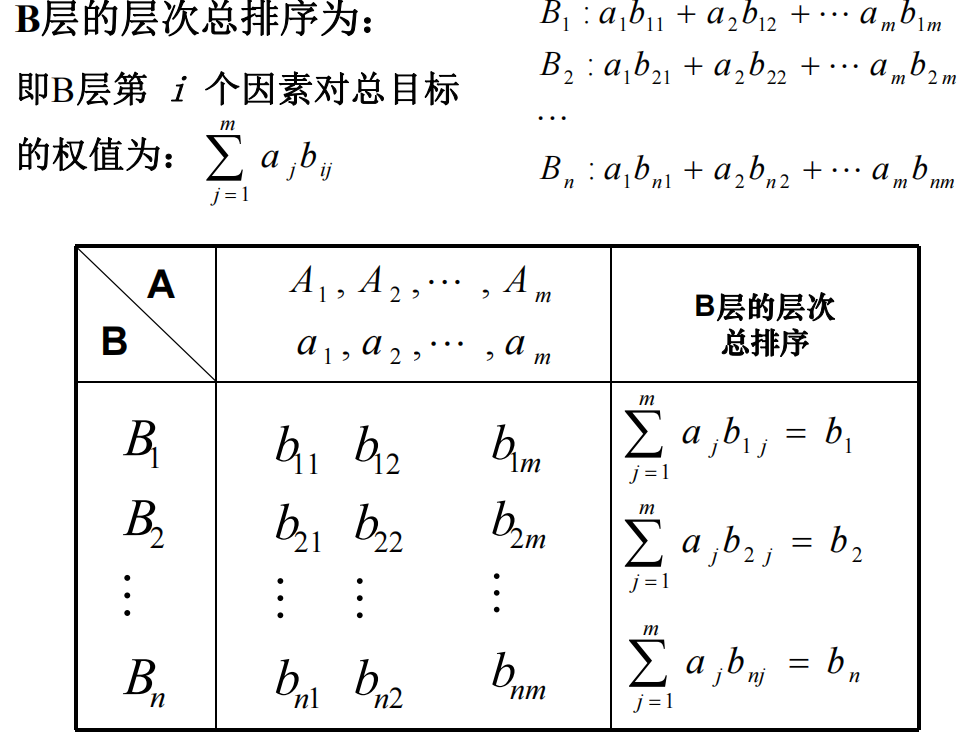
1) 层次总排序
层次总排序指的是计算所有因素相对于总目标的相对重要性的权值的过程
这一过程从最高层到最底层依次进行。
例如前面的旅游目的地选取。
我们通过第三步已经有了准则层,即$C_1,C_2,C_3,C_4,C_5$之间的相对重要性。我们接下来是让方案层中的三个目的地对准则层中的每一个准侧进行比较。即在景色的角度来说,桂林比黄山、北戴河好到哪里去。此时又可以进行第二三步,即构造比较矩阵,进行层次单排序。
由于针对一个指标就可以获得一个层次单排序后的向量,例如对景色会得到一个景色单排序向量,因此最终会得到一个矩阵。
对于上面的旅游选择问题,最后得到的矩阵形状为$5\times3$,记该矩阵为$B$。接下来将准则层的得分向量左乘$B$矩阵,就得到了在方案层的层次总排序
2) 一致性检验
类似的,我们从几个不同的指标对每个方案的打分都是主观的,因此对于单个指标的对比矩阵,会出现不一致的情况。因此还要继续进行一致性检验。
我们对每一个指标$A_j$都可以计算其一致性指标$CI_j$、随机一致性指标$RI_j$,$j=1,2,\cdots,m$,则层次总排序的一致性比率为:
同样,当$CR\leq 0.1$时候,则表示通过层次一致性检验,注意,这里的$A=[a_1,a_2,\cdots,a_n]$是经过归一化之后准则的权重向量值
我们继续上面的旅游的例子,那么有

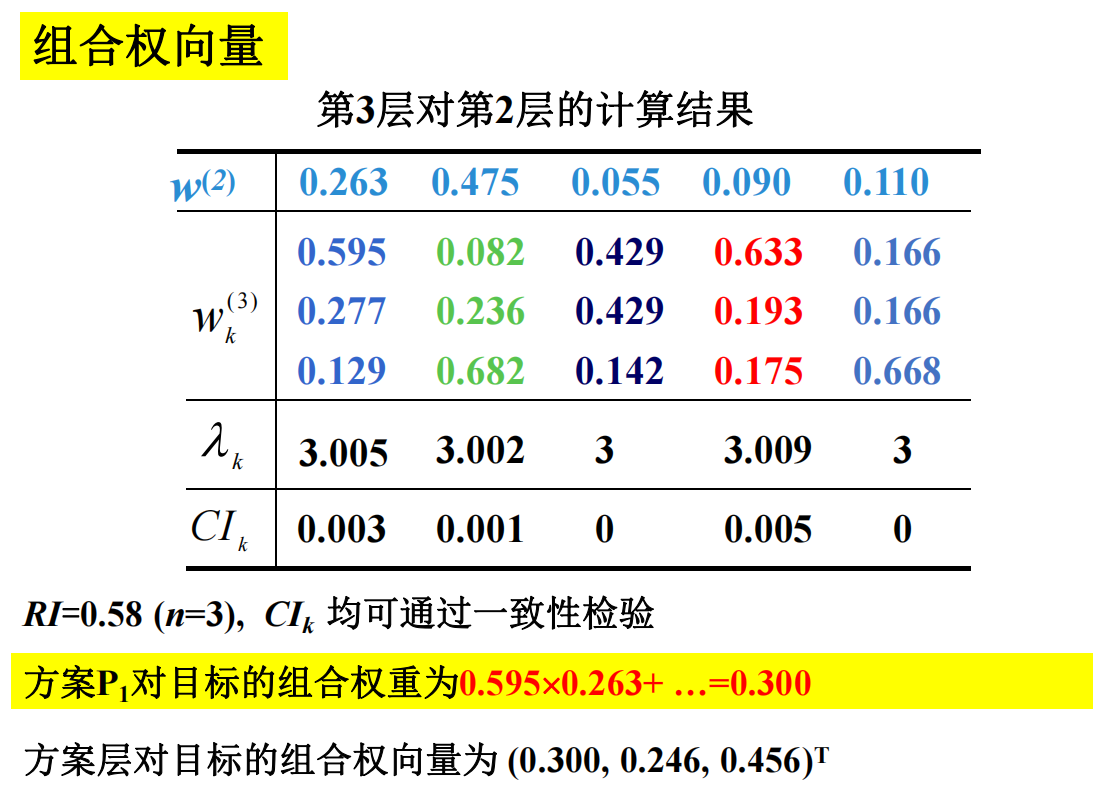
组合权向量即方案最终的得分。计算方法就是用准则层的每个准则得分和某个城市在这几个准则上的得分做内机,最后得到的分数
4. 层次分析法总结
最后,对层次分析法的流程做一个总结
- 建立层次结构模型。该结构图包括目标层,准则层,方案层
- 构造成对比较矩阵。从第二层开始用成对比较矩阵和1-9尺度
- 计算单排序权向量并做一致性检验。对每个成对比较矩阵计算最大特征值及其对应的特征向量,利用一致性指标、随机一致性指标和一致性比率做一致性检验。 若检验通过,特征向量(归一化后)即为权向量;若不通过, 需要重新构造成对比较矩阵
- 计算总排序权向量并做一致性检验。计算最下层对最上层总排序的权向量,利用总排序一致性比率,进行检验。若通过,则可按照总排序权向量表示的结果进 行决策,否则需要重新考虑模型或重新构造那些一致性比率较大的成对比较矩阵
5. 层次分析法Python求解
由于层次分析法全部都是矩阵乘法,因此Numpy和Pandas即可求解,下面的这个只是一个初级版本,实现了层次分析法,但是没有实现从表格中读取,也没有给出GUI的输入,后面等开始大美赛前再完善一下吧
import numpy as np
import pandas as pd
from typing import *
from colorama import Fore, Style
class AnalyticHierarchyProcess(object):
RI = (0, 0, 0.58, 0.9, 1.12, 1.32, 1.41, 1.45, 1.49)
def __init__(self, criteria: Union[List[str], int], plans: Union[List[str], int], method="manual") -> None:
super().__init__()
assert method in ["csv", "manual"]
self.criteria_name = [f"准则{i}" for i in range(criteria)] if isinstance(criteria, int) else criteria
self.criteria = self.get_criteria(criteria_names=self.criteria_name, method=method)
self.plan_names = [f"方案{i}" for i in range(plans)] if isinstance(plans, int) else plans
self.plan_scores = self.get_plan_scores(self.plan_names, self.criteria_name, method=method)
def matrix2str(self, column: List[str], index: List[str]) -> str:
ss = pd.DataFrame(self.criteria, index=index, columns=column)
return ss.__str__()
def run(self):
print("开始层次单排序")
eigvalue, eigvector = np.linalg.eig(self.criteria)
if len(eigvalue) == 1:
print("标准对比矩阵为一致阵")
w = eigvector
else:
print("标准对比矩阵为非一致阵,开始进行一致性检验")
ci = (max(eigvalue) - len(self.criteria)) / (len(self.criteria) - 1)
if (cr := ci/self.RI[len(self.criteria) -1]) < 0.1:
print(f"层次单排序一致性检验一致性比率CR={cr:>.3f},通过检验")
w = eigvector[:, np.argmax(eigvalue)]
else:
print(self.matrix2str(column=self.criteria_name, index=self.criteria_name))
assert False, f"层次单排序一致性检验未通过, CR={cr:>.3f}"
# 归一化处理,softmax
w = w / sum(w)
print("开始层次总排序")
m = []
ci_all = []
ri_all = []
for c_name, c_score in zip(self.criteria_name, self.plan_scores):
print(f"针对 {Fore.GREEN}{c_name}{Style.RESET_ALL} 进行层次单排序")
eigvalue, eigvector = np.linalg.eig(c_score)
if len(eigvalue) == 1:
print(f"{Fore.GREEN}{c_name}{Style.RESET_ALL} 的对比矩阵为一致阵")
m.append(eigvector / sum(eigvector))
else:
print(f"{Fore.GREEN}{c_name}{Style.RESET_ALL} 的对比矩阵为非一致阵")
ci = (max(eigvalue) - len(c_score)) / (len(c_score) - 1)
if (cr := ci/self.RI[len(c_score) -1]) < 0.1:
print(f"{Fore.YELLOW}{c_name}{Style.RESET_ALL}层次单排序一致性检验一致性比率CR={cr:>.3f},通过检验")
e = eigvector[:, np.argmax(eigvalue)]
m.append(e / sum(e))
else:
print(self.matrix2str(self.plan_names, self.plan_names))
assert False, f"{Fore.YELLOW}{c_name}{Style.RESET_ALL}层次单排序一致性检验未通过, CR={cr:>.3f}"
ci_all.append(ci)
ri_all.append(self.RI[len(c_score)-1])
assert (cr:=(np.array(ci_all) @ w) / (np.array(ri_all) @ w)) < 0.1, f"层次总排序一致性检验未通过,CR={cr:>.3f}"
m = np.array(m)
final_score = w @ m
print(f"最终得分:{final_score}")
@staticmethod
def get_criteria(criteria_names: List[str], method: str) -> np.ndarray:
if method == "manual":
criteria = np.eye(N=(l:=len(criteria_names)))
print("="*200)
print("请输入评价标准之间的相对重要性(1-9,1,3,5,7,9分别表示标准A比标准B:同等重要、稍微重要、比较重要、很重要、绝对重要,2,4,6,8分别为中位数)")
print("若标准A不如标准B重要,则输入1/标准B比标准A的相对重要性,例如标准A不如标准B重要,而标准B比标准A为3,那么标准A比标准B为1/3")
print("+"*200)
for i in range(l):
for j in range(i+1, l):
if "/" not in (inp:=input(f"请输入 {Fore.GREEN}{criteria_names[i]}{Style.RESET_ALL} 对 {Fore.GREEN}{criteria_names[j]}{Style.RESET_ALL} 的相对重要性:")):
criteria[i, j] = int(inp)
else:
upper, lower = [int(j) for j in inp.split("/")]
criteria[i, j] = upper / lower
if i+1 < l:
print("+"*200)
position = np.where(criteria==0)
criteria[position] = 1 / criteria.transpose()[position]
print("输入的评价标准之间的对比矩阵为:")
print(criteria)
print("="*200)
elif method == "csv":
pass
return criteria
@staticmethod
def get_plan_scores(plan_names: List[str], criteria_names: List[str], method: str) -> np.ndarray:
if method == "manual":
plan_scores = np.repeat(np.eye(N=len(plan_names)).reshape(1, len(plan_names), len(plan_names)), repeats=len(criteria_names), axis=0)
print("="*200)
print("请输入不同方案之间就某一个标准的的相对重要性(1-9,1,3,5,7,9分别表示标准A比标准B:同等重要、稍微重要、比较重要、很重要、绝对重要,2,4,6,8分别为中位数)")
print("若就标准X,方案A不如方案B重要,则输入1/方案B比方案A的相对重要性,例如就标准X,方案A不如方案B重要,而方案B比方案A为3,那么方案A比方案B为1/3")
for i in range(len(criteria_names)):
print(f"就 {Fore.YELLOW}{criteria_names[i]}{Style.RESET_ALL} 对方案之间的得分进行比较".center(200, "+"))
for j in range(l := len(plan_names)):
for k in range(j+1, l):
if "/" not in (inp:=input(f"请从 {Fore.YELLOW}{criteria_names[i]}{Style.RESET_ALL} 的角度,输入 {Fore.GREEN}{plan_names[j]}{Style.RESET_ALL} 对 {Fore.GREEN}{plan_names[k]}{Style.RESET_ALL} 的相对重要性:")):
plan_scores[i, j, k] = int(inp)
else:
upper, lower = [int(j) for j in inp.split("/")]
plan_scores[i, j, k] = upper / lower
position = np.where(plan_scores[i] == 0)
plan_scores[i, position[0], position[1]] = 1 / plan_scores[i].transpose()[position]
print("输入的不同评价标准下方案间的对比矩阵为:")
for c, s in zip(criteria_names, plan_scores):
print(c)
print(s)
print("="*200)
elif method == "csv":
pass
return plan_scores
if __name__ == "__main__":
ahp = AnalyticHierarchyProcess(criteria=["景色", "费用", "居住", "饮食", "旅途"], plans=["苏杭", "北戴河", "桂林"])
ahp.run()
运行结果

6. 层次分析法例题
A. 队员选拔问题
A. 问题
设某学校数学建模教练组根据实际需要,拟从报名参赛的20名队员中选出15名优秀队员代表学校参赛。 表1给出了20名队员的基本条件的量化情况。 请根据这些条件对20名队员进行综合评价,从中选出15名综合素质较高的优秀队员

B. 问题分析
这是一个半定性与半定量、多因素的综合选优排序问题. 鉴于数学建模竞赛不仅要考查学生的学科知识、还要考查学生的 作能力、计算机应用能力、团结协助能力等多方面的因素,要 从20名队员中选拔出优秀参赛队员,就要对表1中所列的六个因素进行比较分析,综合排序选优,从而选取前几名学生。
C. 假设
- 题目中所确定的考评条件是合理的,能够反映出参选队员的建模能力
- 各参选队员的量化得分是按统一的量化标准得出的
- 对参选队员的量化打分是公平的,所有参选队员对打分结果无异议
- 选拔队员所考虑的六个因素在选拔优秀队员中所起的作用依次为学科知识竞赛成绩、思维敏捷度、知识面宽广度、写作能力、计算机应用能力、团结协助能力,并且相邻两个因素的影响程度之差基本相同
D. 模型建立
根绝题目要求和分析与假设,建立如下的层次结构图
- 第一层为目标层:选拔优秀参赛队员
- 第二层为准则层:选拔优秀队员时所考虑的6个因素,依次为学科知识竞赛成绩、思维敏捷度、知识面宽广度、写作能力、计 算机应用能力、协助能力
- 第三层为方案层:参选的20名队员
结构图如下:

E. 模型求解
确定准则层对目标层的权重向量:根据假设,构造准则层$C$的准则间的比较矩阵

确定方案层对准则层的权重向量:根据表1和模型假设,构造方案层$P$中20个队员对准则层$C$中各因素$C_k$的两两比较矩阵。构造方式为分数的两两比较
求解:结果如下

F. 模型分析
- 由表1,20名队员六项条件互有强弱,利用层次分析法 得到了一种合理的综合排序方案,结果选出了综合实力较强的 15名队员
- 第13号队员各项条件总体较强,排在了第一位
- 第9号和第10号队员各项条件总体较弱,排在后两位
7. 层次分析法的综合评价
最后,给出层次分析法的整体上的一个评价
首先是优点:
- 系统性:把所研究的问题看成一个系统,按照分解、比较判断、 综合分析的思维方式进行决策分析,也是实际中继机理分析方法、统 计分析方法之后发展起来的又一个重要的系统分析工具.
- 实用性:把定性与定量方法结合起来,能处理许多传统的优化 方法无法处理的实际问题,应用范围广.而且将决策者和决策分析者 联系起来,体现了决策者的主观意见,决策者可以直接应用它进行决 策分析,增加了决策的有效性和实用性.
- 简洁性:具有中等文化程度的人都可以学习掌握层次分析法的基 本原理和步骤,计算也比较简便,所得结果简单明确,容易被决策者 了解和掌握.
然后是其缺点:
- 局限性是粗略、主观.首先是它的比较、判断及结果都是粗糙的, 不适于精度要求很高的问题
- 其次是从建立层次结构图到给出两两比较矩阵,人的主观因素作用 很大,使决策结果较大程度地依赖于决策人的主观意志,可能难以为 众人所接受



