本文主要讲解李宏毅ML2021 Spring的Homework1: Covid19 Cases Prediction

李宏毅ML2021-Spring-hw1:Covid19 Cases Prediction
1. Homework Objectives
作业一的目的在于:
- 明白如何使用DNN解决Regression问题
- 掌握基本的DNN训练技术:调参、特征选择、正则化
- 熟悉Pytorch的使用

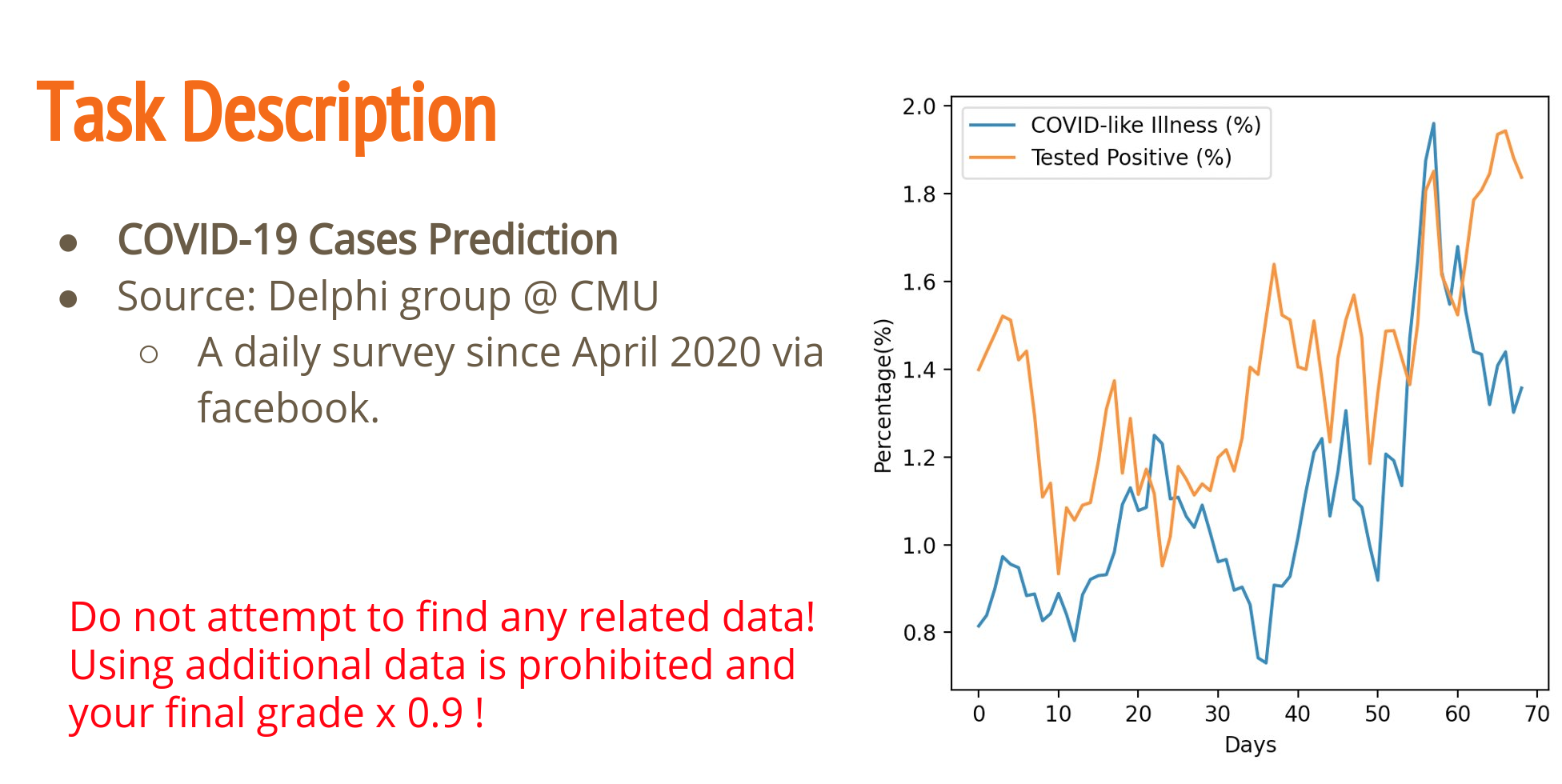
2. Task Description
本次任务要求我们对每日的新冠肺炎的确诊人数进行预测。
1. Survey Methods
数据集的来源是CMU的研究员在社交媒体上发布调查问卷,问卷的内容包括了心理健康状态、流感类似症状疾病患者人数。而后根据受访者居住的地区来监测美国所有州的所有城市的情况。

2. Data Inspection
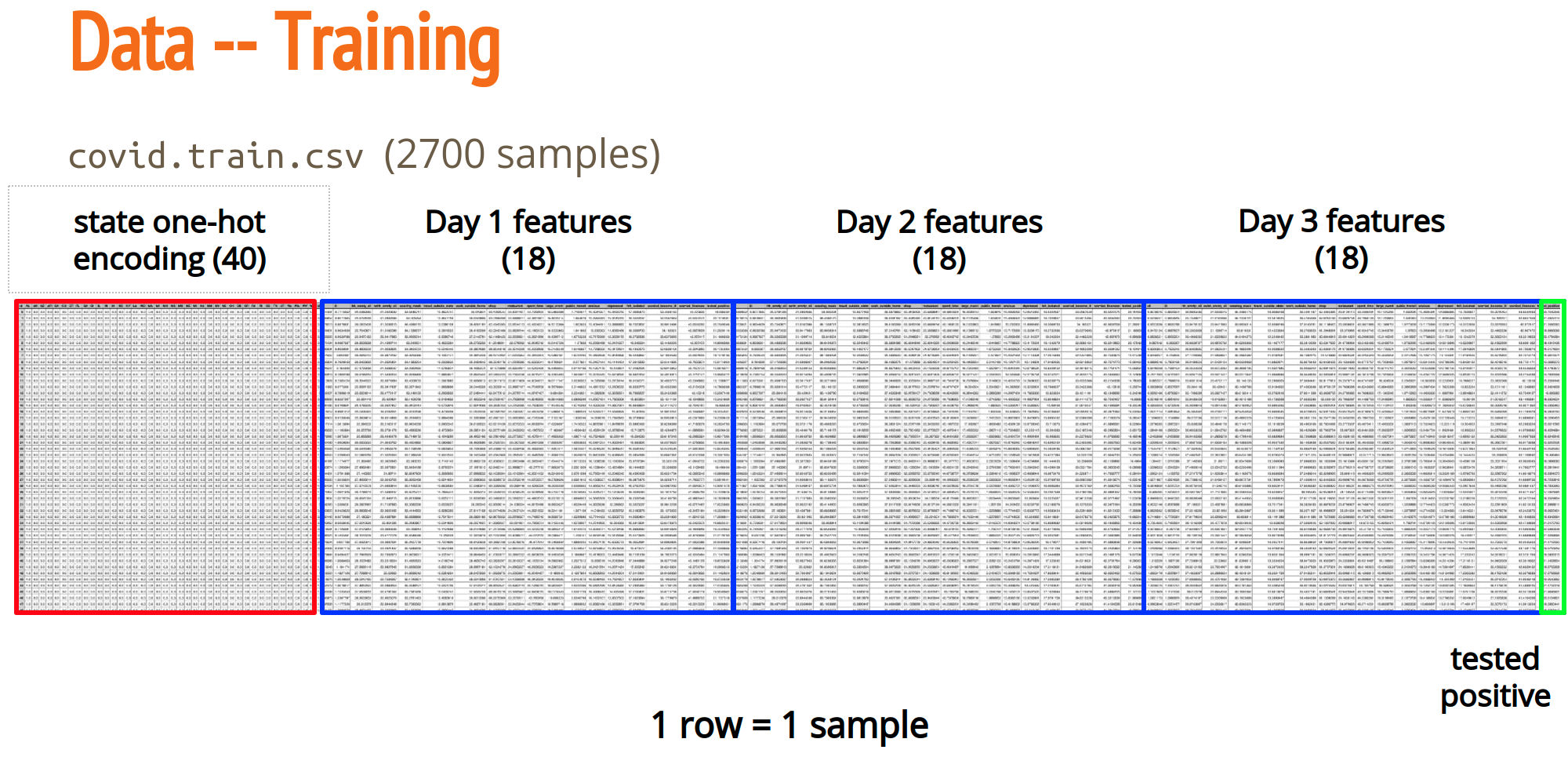
本次任务的数据集是csv文件
在训练数据中,训练数据的csv文件中每一行就是一个example。example的前40维是对于城市的one-hot编码,然后每一个样本会给出来三天的调查情况。
其中,前两天的确诊人数是我们的training的一个feature,而第三天的确诊人数则是我们需要预测的label
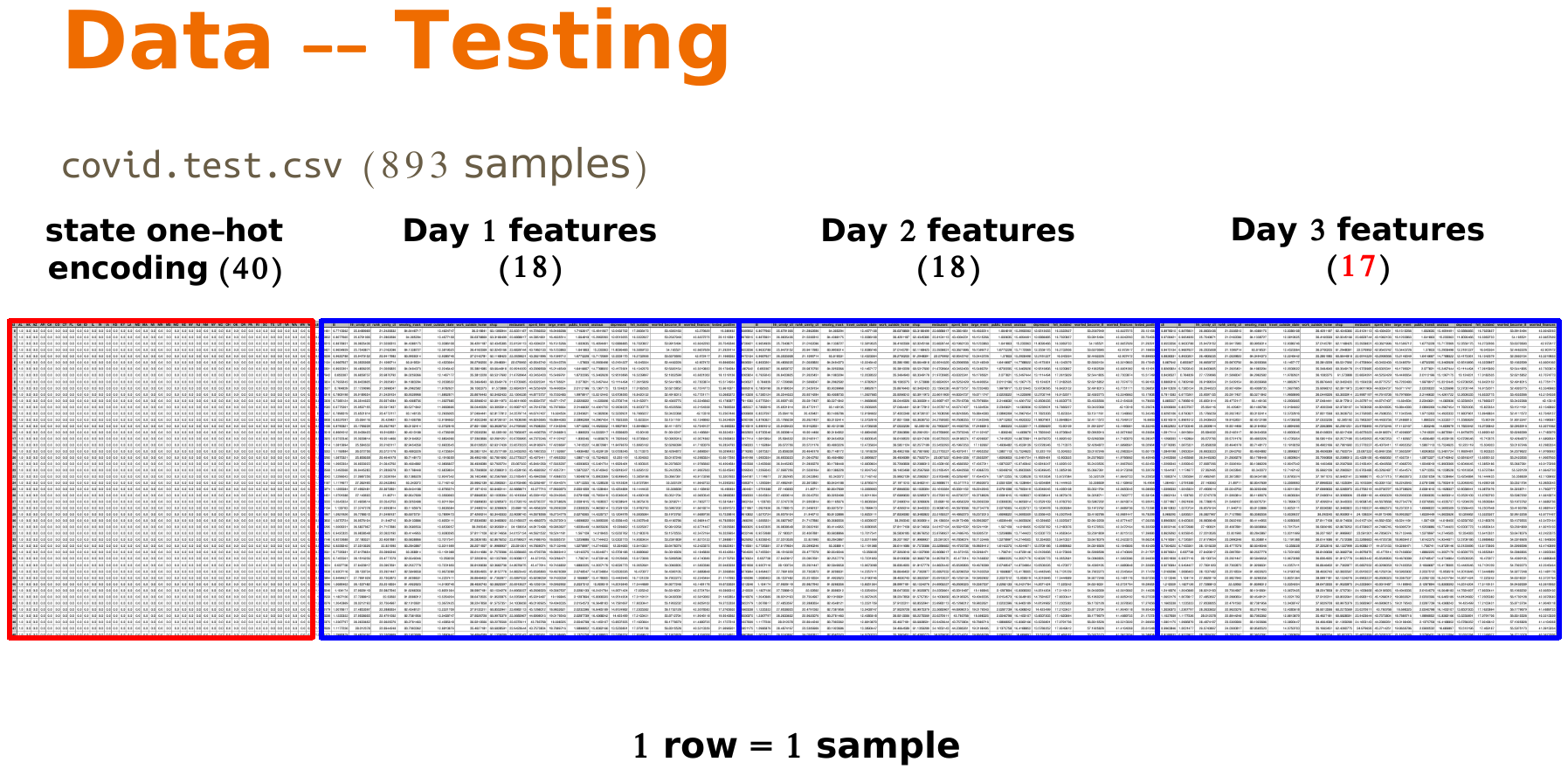
而对于测试数据,则只有前面的feature,没有最后的label,最后我们需要将生成的label以csv文件的形式提交
3. Evaluation Metrics
针对本次任务,使用的衡量标准是Rooted Mean Square Error(RMSE),所以最后在kaggle上得到的分数是越低越好。

4. Baselines
这次任务有三个BaseLine

3. My Solution
下面是我关于本次任务的理解和更新
1. Thoughs
这个是一个regression的任务,最后的输出是一个数字,所以网络最后一层out_feature是1即可
然后这些特征之间有可能有一些特征是和确诊人数的确相关的,有一些是和确诊人数完全无关的,甚至是random的,所以这一些特征可能会影响最后的判断,所以后面需要进行特征选择或者让模型自己选出来重要的特征,然后给重要的特征大的权重。类似于attention
然后可以试试generative的方法,让模型在训练一段时间之后自己生成,即训练判断模型的基础上再生成一个生成模型。生成模型用GAN去生成数据,然后让判断模型去学习。
最后可以试试不确定性的方法。
2. Updates
2021-12-11:完成了基本框架
- 进展:完成了基本的框架的搭建,明天开始训练。完成的框架包括训练代码,网络的定义,dataset和得到提交文件的代码
(torch) jack@jack-Alienware-m15-R3:/media/jack/JackCode/project/deeplearning/hw1_1-regression$ tree src/
src/
├── dataset.py
├── gen_submission.py
├── networks.py
├── pathconfig.py
└── train.py
2021-12-12 update1:训练时loss不下降😢
问题:开始训练,但是训练的时候遇到了一些问题,训练的时候loss一直没有下降,例如下面这张图
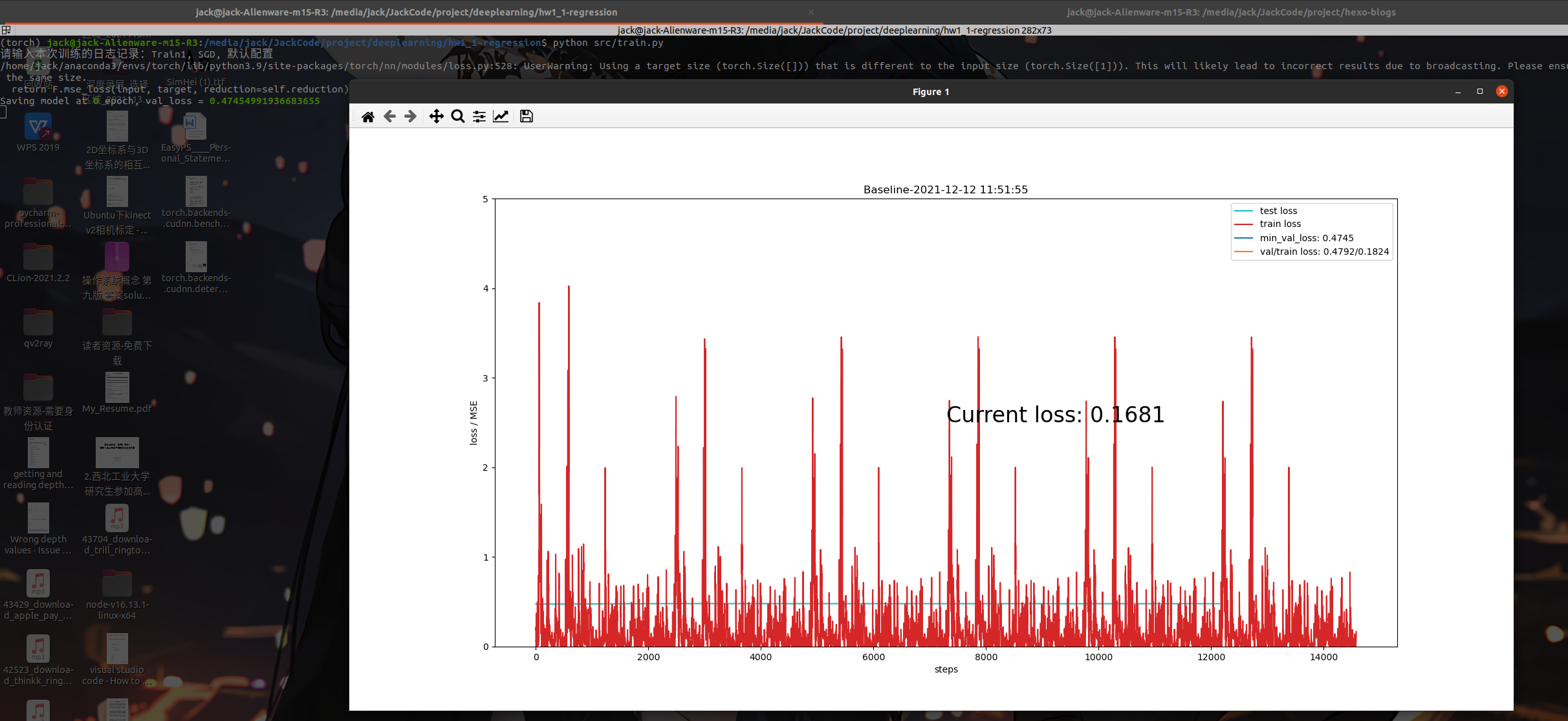
解决办法:最后经过检查,是batchsize的问题,dataloader的忘记设置batchsize和shuffle了,所以出了问题,这个数据集里单个样本随机波动太大,不像图像是比较通用的,随机波动小,单个example也能学到东西。

最后修改掉之后就可以正常训练了,以后一定要注意小batchsize带来的小样本梯度随机波动问题
最后可以正常训练
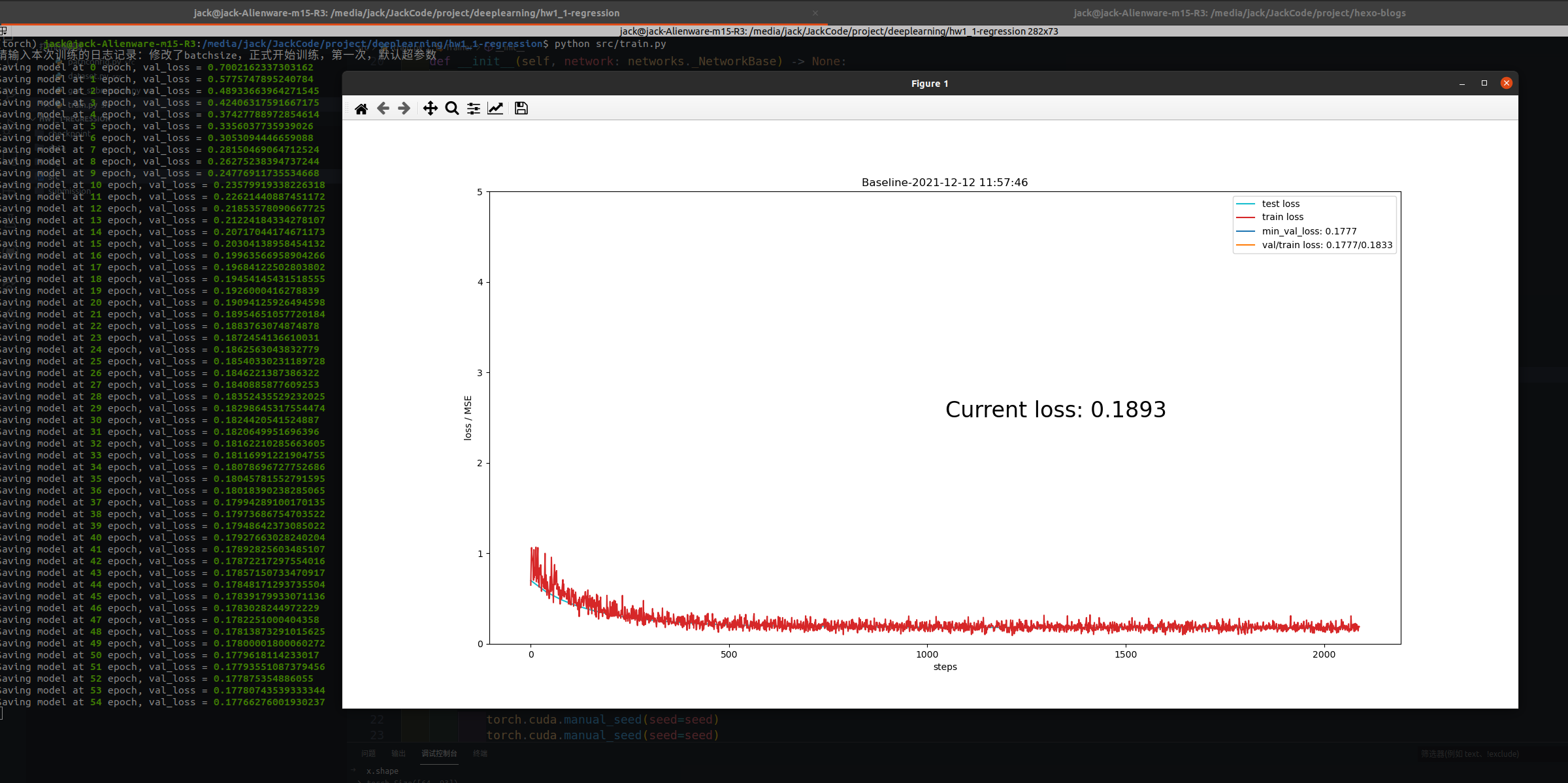
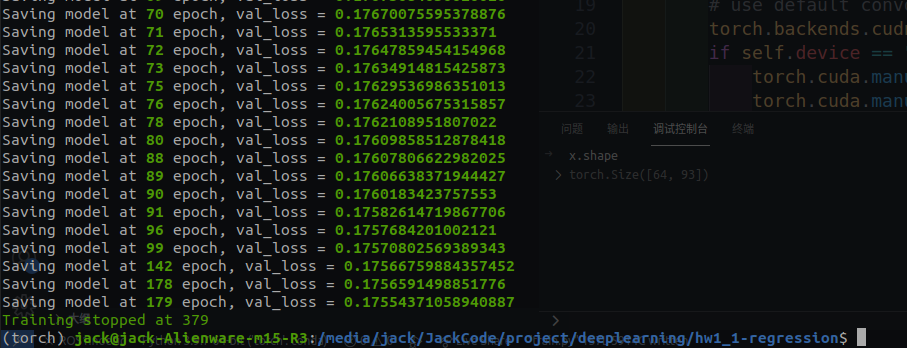
最后在379个epoch时候停下来了,提交一发
2021-12-12 update2: 提交分数起飞💥
问题:接上一个问题,完成了之后提交结果,分数很烂

解决办法:最后经过检查,是网络在训练的时候,对训练数据的feature和label都进行了正则化,使其服从均值为0,标准差为1的分布,这样在训练过程中的梯度的分布也会更加均匀。但是这样做的问题就是网络预测的进过标准化之后的label,所以使用测试数据生成结果的时候得到的也是标准化之后的结果,需要加上label的均值和标准差,但是由于是测试数据,所以没有标准差和均值,而测试数据和训练数据不是独立同分布的。所以不能直接加上测试数据的标准差和方差
修改之后不给label做标准化,再训练一次然后提交

再进行一次训练
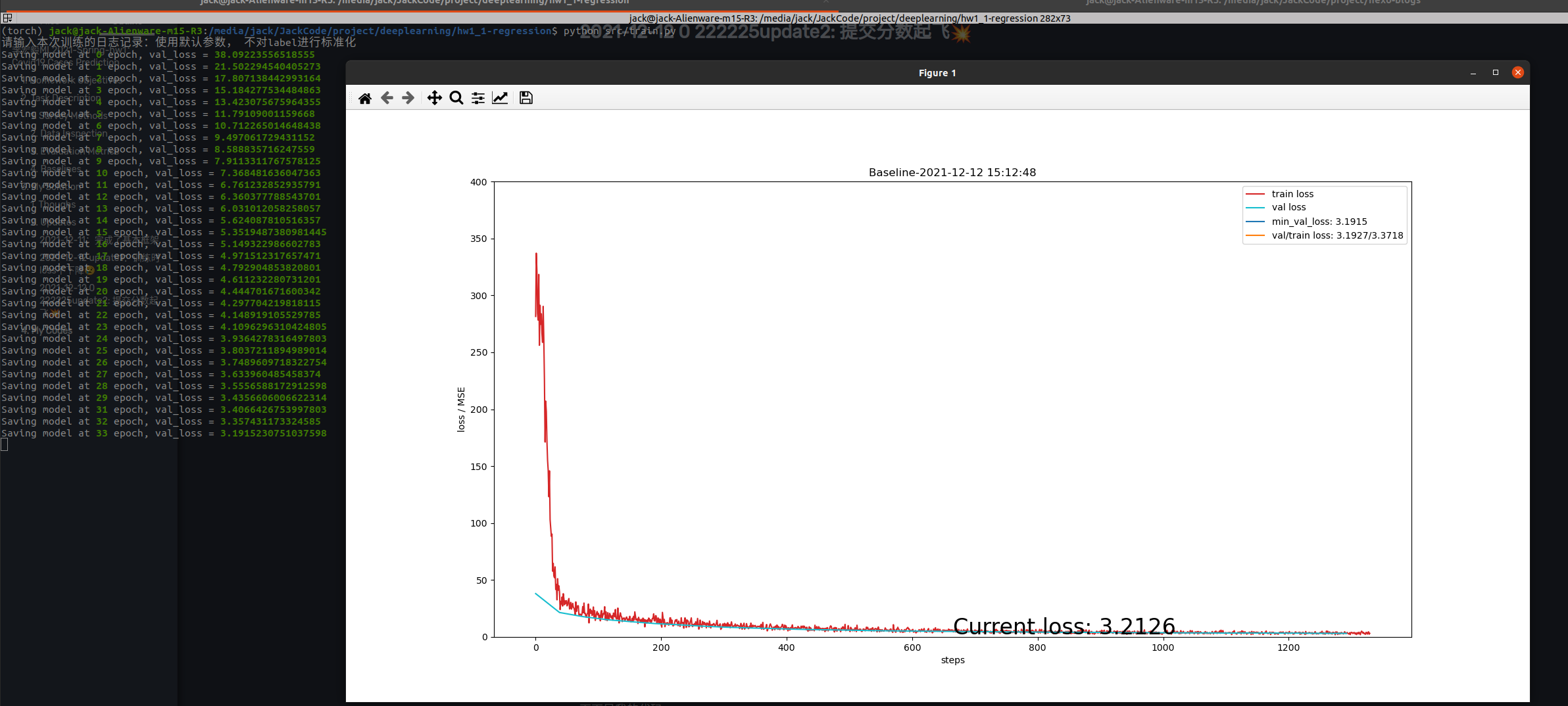
最后提交的结果,相比于一开始有了很大的进步

2021-12-12 update3: Simple baseline🚩
大胜利🎉
思路:尝试了一下仅仅使用前两天的确诊人数作为feature来训练,最后提升巨大,由于我在代码里预留了dim2use,所以直接加上前两的确诊人数的feature和州,一共42个dimension再来一次
所以前面的猜想确实成立,即存在一些和确诊人数完全无关的特征,这些特征会极大地影响模型的表现

效果:

2021-12-12 update4: 特征选择的思考 Medium Baseline 🚩
想法:因为在前面使用了州和前两天,得到的分数非常的高,所以利用了特征选择的手段,试了一下不同的特征,得到的结果如下
使用了州和前两天

使用了得分前15的特征

使用了得分大于500的特征

只使用前两天得病的人数

而特征选择时候前90个特征的得分如下,可以看到,前两个特征(前两天确诊的人数)的分数是远远大于剩下的特征,也就难怪训练出来最后一个的得分最高
Specs Score 76 tested_positive.1 148069.658278 58 tested_positive 69603.872591 43 hh_cmnty_cli 9235.492094 61 hh_cmnty_cli.1 9209.019558 79 hh_cmnty_cli.2 9097.375172 44 nohh_cmnty_cli 8395.421300 62 nohh_cmnty_cli.1 8343.255927 80 nohh_cmnty_cli.2 8208.176435 41 cli 6388.906849 59 cli.1 6374.548000 77 cli.2 6250.008702 42 ili 5998.922880 60 ili.1 5937.588576 78 ili.2 5796.947672 93 worried_finances.2 833.613191 75 worried_finances.1 811.916460 57 worried_finances 788.076931 88 public_transit.2 686.736539 70 public_transit.1 681.562902 52 public_transit 678.834789 84 shop.2 561.764051 66 shop.1 553.876727 48 shop 546.553395 0 id 328.682311 92 worried_become_ill.2 208.122647 18 MA 205.672603 74 worried_become_ill.1 203.473072 56 worried_become_ill 199.195461 86 spent_time.2 193.926689 68 spent_time.1 188.763751 50 spent_time 183.145229 21 MS 164.450807 30 OK 160.776135 7 CT 146.609540 17 MD 123.546972 5 CA 122.361562 29 OH 92.603763 24 NV 86.480581 10 ID 85.604275 53 anxious 83.532232 22 MO 80.571861 36 UT 76.092379 71 anxious.1 75.073522 3 AZ 72.803676 85 restaurant.2 71.047754 67 restaurant.1 70.086743 23 NE 69.082676 49 restaurant 69.027593 35 TX 68.609347 89 anxious.2 64.587744 2 AK 64.396242 32 PA 63.096093 6 CO 47.446096 15 KY 43.151972 13 IA 42.096600 8 FL 39.976778 27 NY 38.261684 38 WA 35.198775 31 OR 30.424819 82 travel_outside_state.2 29.424808 19 MI 27.611294 64 travel_outside_state.1 27.477274 46 travel_outside_state 25.788251 14 KS 18.699994 55 felt_isolated 18.345728 33 RI 18.223800 73 felt_isolated.1 18.050098 91 felt_isolated.2 17.895720 34 SC 15.174100 45 wearing_mask 13.106862 63 wearing_mask.1 11.660815 20 MN 11.134685 87 large_event.2 10.995323 1 AL 10.915952 81 wearing_mask.2 10.423544 39 WV 9.407003 69 large_event.1 9.131669 25 NJ 8.637824 37 VA 8.328449 51 large_event 7.449227 9 GA 7.300447 83 work_outside_home.2 4.174404 65 work_outside_home.1 3.887156 54 depressed 3.837879 11 IL 3.834123 47 work_outside_home 3.283513 72 depressed.1 2.967971 28 NC 2.877359 4 AR 2.546223 90 depressed.2 2.362492 Int64Index([76, 58, 43, 61, 79, 44, 62, 80, 41, 59, 77, 42, 60, 78, 93, 75, 57, 88, 70, 52, 84, 66, 48, 0, 92, 18, 74, 56, 86, 68, 50, 21, 30, 7, 17, 5, 29, 24, 10, 53, 22, 36, 71, 3, 85, 67, 23, 49, 35, 89, 2, 32, 6, 15, 13, 8, 27, 38, 31, 82, 19, 64, 46, 14, 55, 33, 73, 91, 34, 45, 63, 20, 87, 1, 81, 39, 69, 25, 37, 51, 9, 83, 65, 54, 11, 47, 72, 28, 4, 90], dtype='int64')
2021-12-12 update5: 大进步🎉
思路:因为前面实验了一下使用不同的特征,发现只有前两个特征,所以我感觉特征选择可能走到了头,需要新的思路来进一步提升模型的表现。因此从模型本身下手,更换了网络模型,从助教的baseline换成了残差模型,同样还是只有两个特征
效果:最后的效果的提升还是巨大的

2021-12-12 update6: 关于优化器
思路:前面改了一下网络结构,使得精度有了不错的提升。我在特征选择后面又想到了一个思路,就是换一个优化器,所以在实验完网络结构之后我又实验了一下优化器,看看优化器会不会对训练又帮助,所以把SGD换成了AdamW,AdamW比Adam少了对bias的求导,所以方向避免出错。
换优化器其实我也是实验了不少次,因为使用SGD的时候,不管超参数怎么变,总会在51个epoch的时候出现一次最优值。虽然有的超参数经过比较长的epoch之后会有新的最优值,但是51这个epoch常常会出现,不管我怎么变超参数。
所以我怀疑51个epoch的时候对于SGD优化器,已经到了一个比较wide的谷底,这个时候很难跳出去,所以有的时候会直接在这里停下来。
作为弥补我换了一个优化器,换成了AdamW,因为AdamW跳出saddle point的能力要强不少
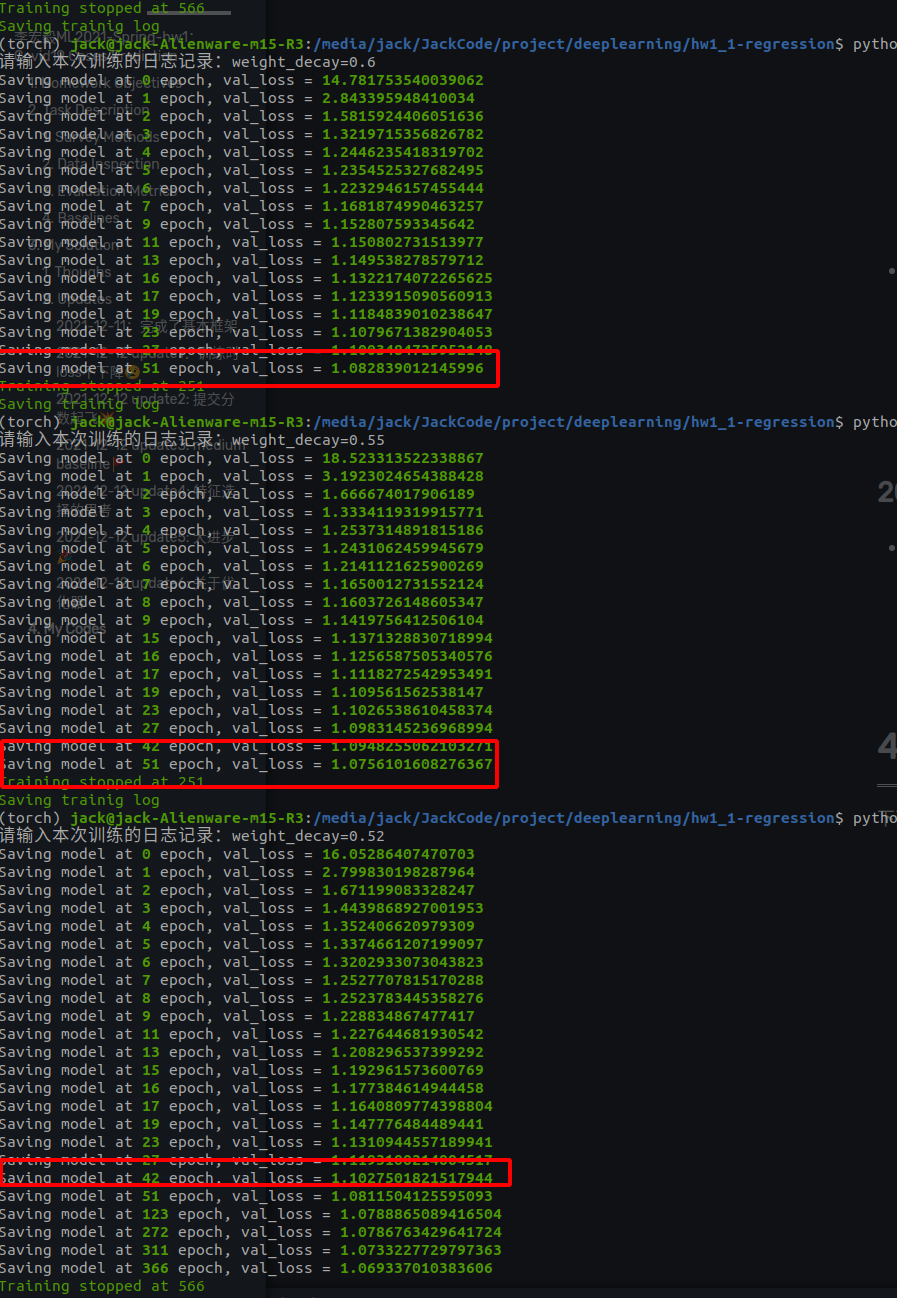
结果:更换优化器之后,训练轮次要长很多,而且最初的十多个epoch会有震荡,还在loss 空间的高处
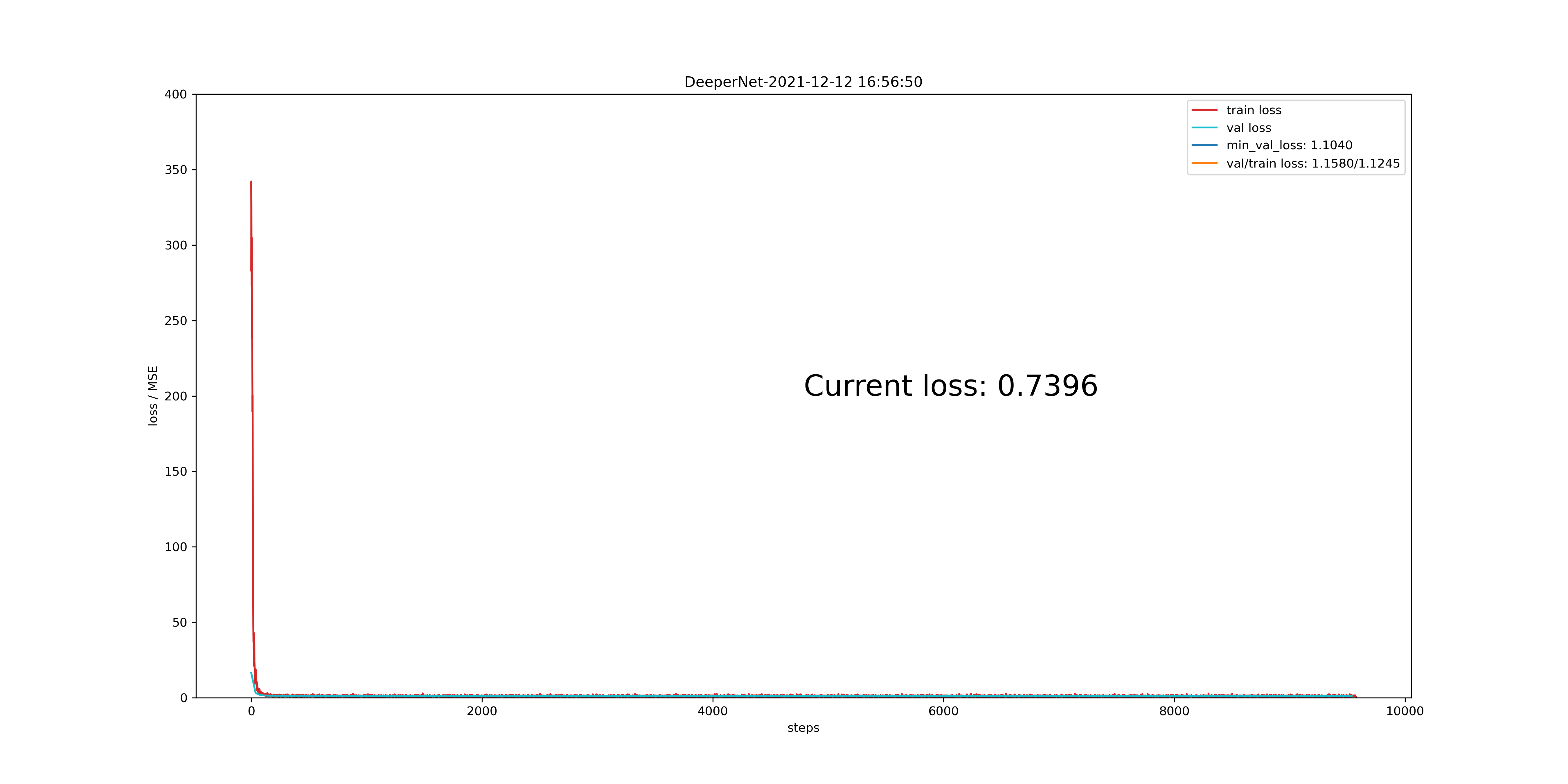
上面的图其实看不太出来,因为横轴30000多个step,但是SGD的训练图在开始部分是直线下冲的

最后的结果是成功冲进了1分以内的误差

2012-12-12 update7: 关于正则化
思路:前面在想的时候其实还想到了第三个思路,就是在网络中加入正则化方法,一个是加入dropout,一个是加入batch normalization,因为目前这两个是公认的不错的的正则化方法。而使用正则化方法能够帮助加速训练、提高收敛精度。然而在训练时候却发现不太对劲。

可以看到,使用batch norm 和 dropout,收敛速度不降反升。这个和大家的公认有所差别,我百思不得其解😕
最后怀疑是AdamW优化器的问题。因为AdamW优化器中有限制梯度的项,而dropout会mask掉一些神经元,导致梯度在这里为0,而batch norm则是炸平梯度空间。所以怀疑问题出在这里,优化器换回SGD,好家伙,这个速度,比纯SGD快多了(下面的图第一个日志写错了,应该是batch norm)
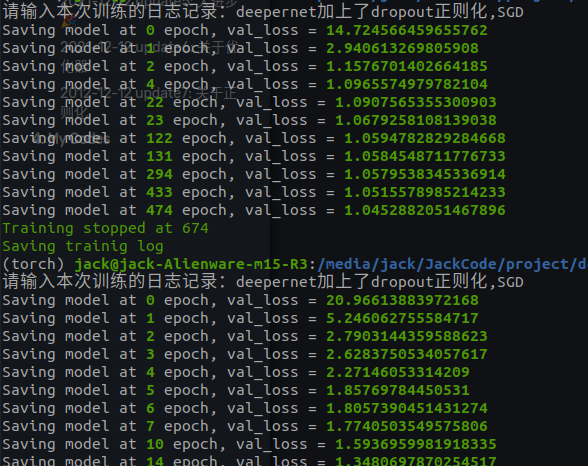
2021-12-13 update1: Strong Network,More Complex data
问题:昨天在最后使用adam优化器和residual模块的配合,训练阶段使用特征选择选出来的前两天的确诊人数,一共2个dimension的feature作为输入进行训练,最后得到的精度0.98左右。昨天的炼丹就到此为止了。昨天晚上在复盘的时候想到,老师上课讲过的模型训练攻略里说的内容。
- 而在复盘的时候想起来,昨天的炼丹过程其实提升最大的有两段,第一段就是在一开始使用助教的baseline的时候,使用特征抽取选取了前两天的特征,loss在training data上的损失就收敛到1.x左右了。可是使用baseline在这之后不管怎么样都始终无法进入到0.x的大关。而关于Optimization中也实验过了正则化、调参、换优化器等等手段。但是模型的表现还是没有下降。
- 第二个阶段就是换了residual的模型,性能立马又有了提升。但是同样的,residual的模型各种optimization的方法都已经试过了,最后还是卡在了0.98左右。
最后想想老师讲的课,突然明白,在一开始的时候,model的能力不够强,所以没有办法学好14个重要特征。因此选择前两天的确诊人数作为feature,性能有了很大的提升。这个时候的问题可能是baseline model 的model bias了,即模型的能力不够强。后来歪打正着换了一个模型,同样的数据和参数下训练,性能立马有了提升,所以确信是baseline模型的问题。
可是后来不管怎么调,residual的模型性能也上不去了。后来其实我也试了一下wide的模型,wide + residual的模型,最后性能都不是很好。这个时候我突然想起来,因为baseline里面是两个feature表现最好,所以我就直接用了两个dimension的feature来train residual的一系列model。后来换model单纯的只是希望能够得到能力更强的model。
但是问题却在于,能力更强的model确实能够得到更好的performance,但是我并不知道residual是否达到了他的上限,即有可能是我只用了前两天的确诊人数,这样的training data对residual太弱了,他完全学有余力。
刚好我也没有像baseline一样进行特征选择的测试,所以我其实并不知道residual的model是否达到他的上限了。所以今天我试着使用了更多的training data,即使用了所有大于5000分的数据,一共14个维度

结果:最后经过训练之后提交,大进步🎉

2021-12-13 update2: temp final
搞到现在,做了一下,现在最优的成绩是下面的,基本上就是残差模块的数量问题,关于伪标签其实我感觉如果用test的data来做的话,就会有过拟合test数据的嫌疑。所以目前想的是等用generative的方法来做,目前暂时就先到这里

4. My Codes
下面是我的代码
1. 代码结构
整个代码的结构如下
(torch) jack@jack-Alienware-m15-R3:/media/jack/JackCode/project/deeplearning/hw1_1-regression$ tree -d -L 2
.
├── checkpoint
│ ├── Baseline
│ ├── DeeperNet
│ ├── DeeperNormalizedNet
│ ├── OtherNet
│ └── WideNet
├── data
├── log
│ ├── Baseline
│ ├── DeeperNet
│ ├── DeeperNormalizedNet
│ ├── OtherNet
│ └── WideNet
├── src
│ ├── config
│ └── __pycache__
└── submission
├── Baseline
├── DeeperNet
├── DeeperNormalizedNet
├── OtherNet
└── WideNet
22 directories
其中:
src里都是源代码
checkpoint、log和submission都如其名
每次进行训练的时候,都会根据模型(网络)名创建一个文件夹,在里面放对应的训练日志、提交结果、参数文件等等。以log为例,每次得到的结果都是根据日期和时间创建的文件夹。只有正确训练结束才会三个文件,分别为训练摘要、训练图像以及训练的过程中的loss。
(torch) jack@jack-Alienware-m15-R3:/media/jack/JackCode/project/deeplearning/hw1_1-regression$ tree log/DeeperNet/ log/DeeperNet/ ├── 2021-12-12 16_52_47 ├── 2021-12-12 16_53_13 ├── 2021-12-12 16_53_38 ├── 2021-12-12 16_54_21 ├── 2021-12-12 16_55_03 │ └── message.txt ├── 2021-12-12 16_56_25 │ └── message.txt ├── 2021-12-12 16_56_50 │ ├── message.txt │ ├── train_log1.png │ └── train_val.loss.pkl ├── 2021-12-12 17_12_44 ├── 2021-12-12 17_12_57 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-12 17_16_00 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-12 17_16_56 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-12 17_17_49 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-12 17_20_12 ├── 2021-12-12 17_20_34 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-12 17_41_30 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-12 18_17_42 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-12 18_21_58 ├── 2021-12-12 18_22_24 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-12 18_28_27 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-12 19_17_44 │ └── message.txt ├── 2021-12-12 19_18_15 │ └── message.txt ├── 2021-12-12 19_18_42 │ └── message.txt ├── 2021-12-12 19_19_12 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-12 19_20_16 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-12 19_25_46 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-12 19_27_36 │ └── message.txt ├── 2021-12-12 19_28_20 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-12 19_33_37 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-12 19_37_51 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-12 19_42_24 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-12 19_48_44 │ └── message.txt ├── 2021-12-12 19_48_59 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-12 19_52_28 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-12 19_56_30 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-12 20_05_07 ├── 2021-12-12 20_05_46 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-12 20_10_02 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-12 20_12_20 │ └── message.txt ├── 2021-12-12 20_13_33 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-12 20_16_43 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-12 20_21_37 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-13 00_46_42 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-13 00_59_08 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-13 01_34_47 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-13 01_39_11 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-13 01_48_12 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl ├── 2021-12-13 01_51_22 │ ├── message.txt │ ├── train_log.png │ └── train_val.loss.pkl └── 2021-12-13 01_55_10 ├── message.txt ├── train_log.png └── train_val.loss.pkl 48 directories, 104 files
- 直接提交submission中生成的文件即可
2. src中文件作用
src中有这些文件
(torch) jack@jack-Alienware-m15-R3:/media/jack/JackCode/project/deeplearning/hw1_1-regression$ tree src/ -L 1
src/
├── config
├── dataset.py
├── feature_selection.py
├── gen_submission.py
├── networks.py
├── pathconfig.py
├── __pycache__
└── train.py
2 directories, 6 files
其中:
- train是训练代码
- gen_submission是生成结果的代码
- networks是所有的网络的代码
- feature_selection 是做特征工程的时候代码
具体的代码在下面给出来
3. data中的数据
data中需要把训练、测试数据放进去就行了
(torch) jack@jack-Alienware-m15-R3:/media/jack/JackCode/project/deeplearning/hw1_1-regression$ tree data/
data/
├── covid.test.csv
├── covid.train.csv
└── sampleSubmission.csv
0 directories, 3 files
其实最后只会用到test 和 train
4. 代码
用的时候要注意,gen_submission要改参数文件的路径。此外自己想写网络的话需要继承_NetworkBase,然后重写dtype
训练网络和生成结果的时候一种网络一个函数即可
1. pathconfig.py
自动决定所有的路径
import sys
from pathlib import Path
from colorama import Fore, Style
if (p:=Path(__file__).resolve().parent).__str__() not in sys.path:
sys.path.append(p.__str__())
def green(s: str):
return f"{Fore.GREEN}{s}{Fore.RESET}"
def red(s: str):
return f"{Fore.RED}{s}{Fore.RESET}"
def yellow(s: str):
return f"{Fore.YELLOW}{s}{Fore.RESET}"
class Paths:
base_path: Path = Path(__file__).resolve().parents[1]
src_path: Path = base_path.joinpath("src")
log_path: Path = base_path.joinpath("log")
data_path: Path = base_path.joinpath("data")
checkpoint_path: Path = base_path.joinpath("checkpoint")
submission_path: Path = base_path.joinpath("submission")
train_path: Path = data_path / "covid.train.csv"
test_path: Path = data_path / "covid.test.csv"
config_path: Path = src_path / "config"
for key, value in Paths.__dict__.items():
if key.endswith("_path") and not value.exists():
value.mkdir(parents=True)
if __name__ == "__main__":
pc = Paths()
print(pc.base_path)
2. feature_selection.py
import numpy as np
import pandas as pd
from sklearn import preprocessing
from sklearn.feature_selection import SelectKBest, f_regression
from pathconfig import Paths
data = pd.read_csv(Paths.train_path)
x, y = data.iloc[:, :-1], data.iloc[:, -1]
x = (x - x.min()) / (x.max() - x.min())
# 根据得分函数计算出来的分数选取前五个
bestfeatures = SelectKBest(score_func=f_regression, k=5)
fit = bestfeatures.fit(x,y)
dfscores = pd.DataFrame(fit.scores_)
dfcolumns = pd.DataFrame(x.columns)
#concat two dataframes for better visualization
featureScores = pd.concat([dfcolumns,dfscores],axis=1)
featureScores.columns = ['Specs','Score'] #naming the dataframe columns
pd.set_option('display.max_rows', None)
print(featureScores.nlargest(90,'Score')) #print 15 best features
print(featureScores.nlargest(90, "Score").index)
print(pd.Series(data.columns))
3. dataset.py
import pickle
import random
import typing
import numpy as np
import pandas as pd
import torch.utils.data as data
from pathconfig import *
class CovidDataset(data.Dataset):
def __init__(self, split="train", dim2use: typing.Iterable[int]=None, val_ratio: float=-1) -> None:
super().__init__()
dim2use = range(93) if dim2use is None else dim2use
assert split in ["train", "test", "val"], red(f"无效的数据集类别:{split}")
assert (t:=(np.array(dim2use) < 93)).all(), red(f"无效的feature dimension, 最大只有 93 维(0-92), dim2use={dim2use[t]} > 92")
# read file
self.split: str = split
if self.split == "test":
raw_csv: np.ndarray = (a:=pd.read_csv(Paths.test_path, header=0, index_col=0, dtype=float)).to_numpy()
else:
raw_csv: np.ndarray = pd.read_csv(Paths.train_path, header=0, index_col=0, dtype=float).to_numpy()
if 0 < val_ratio < 1:
val_idx: typing.List[int] = random.sample(population=range(len(raw_csv)), k=int(val_ratio * len(raw_csv)))
train_idx: typing.List[int] = list(set(range(len(raw_csv))) - set(val_idx))
if Paths.config_path.joinpath("train_val.pkl").exists():
print(yellow("覆盖train_val.pkl"))
with open(Paths.config_path.joinpath("train_val.pkl"), "wb") as f:
pickle.dump(obj={"train":train_idx, "val":val_idx}, file=f)
else:
try:
with open(Paths.config_path.joinpath("train_val.pkl"), "rb") as f:
p = pickle.load(file=f)
train_idx: typing.List[int] = p["train"]
val_idx: typing.List[int] = p["val"]
except FileNotFoundError:
assert False, red(f"不存在train_validation的config文件,请先指定val_ratio生成train_val的config")
if split == "val":
raw_csv = raw_csv[val_idx, :]
else:
raw_csv = raw_csv[train_idx, :]
# standard
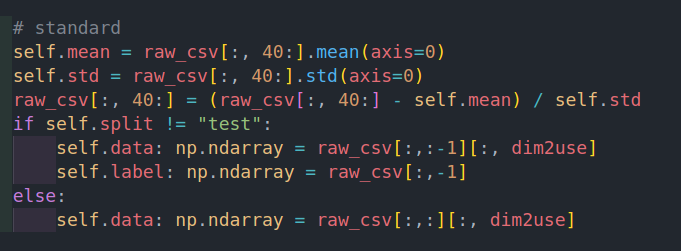
self.mean = raw_csv[:, 40:-1].mean(axis=0)
self.std = raw_csv[:, 40:-1].std(axis=0)
raw_csv[:, 40:-1] = (raw_csv[:, 40:-1] - self.mean) / self.std
if self.split != "test":
self.data: np.ndarray = raw_csv[:,:-1][:, dim2use]
self.label: np.ndarray = raw_csv[:,-1]
else:
self.data: np.ndarray = raw_csv[:,:][:, dim2use]
def __len__(self) -> int:
return len(self.data)
def __getitem__(self, index: int) -> typing.Tuple[np.ndarray]:
if self.split != "test":
return self.data[index], self.label[index]
else:
return self.data[index]
if __name__ == "__main__":
# cd = CovidDataset(split="train", val_ratio=0.1)
# cd = CovidDataset(split="val", dim2use=range(10))
# cd = CovidDataset(split="test", dim2use=range(10))
cd = CovidDataset(split="train", dim2use=None)
print(cd.data.shape)
for x, y in cd:
print(x, y)
print(x.shape)
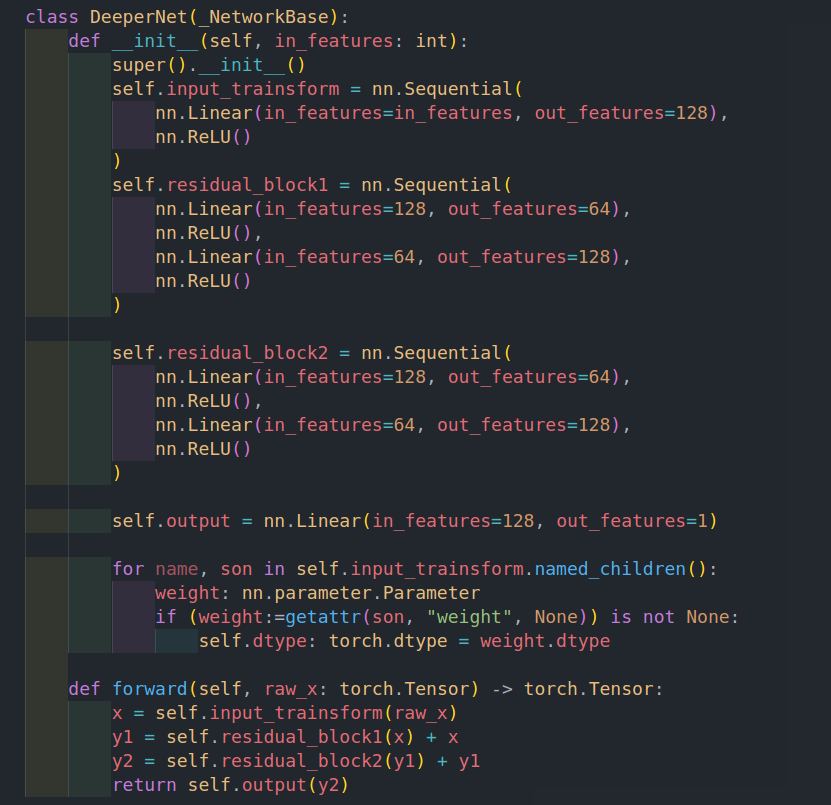
4. networks.py
import torch
import torch.nn as nn
class _NetworkBase(nn.Module):
def __init__(self):
super().__init__()
self.dtype = None
self.net: nn.Module = None
class Baseline(_NetworkBase):
def __init__(self, in_features:int):
super().__init__()
self.net = nn.Sequential(
nn.Linear(in_features=in_features, out_features=64),
nn.ReLU(),
nn.Linear(in_features=64, out_features=1)
)
for name, son in self.net.named_children():
weight: nn.parameter.Parameter
if (weight:=getattr(son, "weight", None)) is not None:
self.dtype: torch.dtype = weight.dtype
def forward(self, x: torch.Tensor):
# x: [batch, channel]
return self.net(x)
class DeeperNet(_NetworkBase):
def __init__(self, in_features: int):
super().__init__()
self.input_trainsform = nn.Sequential(
nn.Linear(in_features=in_features, out_features=64),
nn.LeakyReLU(),
# nn.BatchNorm1d(num_features=128),
# nn.Dropout(),
)
self.residual_block1 = nn.Sequential(
nn.Linear(in_features=64, out_features=32),
nn.LeakyReLU(),
# nn.BatchNorm1d(num_features=64),
# nn.Dropout(),
nn.Linear(in_features=32, out_features=64),
nn.LeakyReLU(),
# nn.BatchNorm1d(num_features=128),
# nn.Dropout(),
)
self.residual_block2 = nn.Sequential(
nn.Linear(in_features=64, out_features=32),
nn.LeakyReLU(),
# nn.BatchNorm1d(num_features=64),
# nn.Dropout(),
nn.Linear(in_features=32, out_features=64),
nn.LeakyReLU(),
# nn.BatchNorm1d(num_features=128),
# nn.Dropout(),
)
self.residual_block3 = nn.Sequential(
nn.Linear(in_features=64, out_features=32),
nn.LeakyReLU(),
# nn.BatchNorm1d(num_features=64),
# nn.Dropout(),
nn.Linear(in_features=32, out_features=64),
nn.LeakyReLU(),
# nn.BatchNorm1d(num_features=128),
# nn.Dropout(),
)
self.residual_block4 = nn.Sequential(
nn.Linear(in_features=64, out_features=32),
nn.LeakyReLU(),
# nn.BatchNorm1d(num_features=64),
# nn.Dropout(),
nn.Linear(in_features=32, out_features=64),
nn.LeakyReLU(),
# nn.BatchNorm1d(num_features=128),
# nn.Dropout(),
)
self.output = nn.Sequential(
nn.Linear(in_features=64, out_features=1),
# nn.LeakyReLU(),
# nn.Linear(in_features=32, out_features=1)
)
for name, son in self.input_trainsform.named_children():
weight: nn.parameter.Parameter
if (weight:=getattr(son, "weight", None)) is not None:
self.dtype: torch.dtype = weight.dtype
def forward(self, raw_x: torch.Tensor) -> torch.Tensor:
x = self.input_trainsform(raw_x)
y1 = self.residual_block1(x) + x
y2 = self.residual_block2(y1) + y1
# y3 = self.residual_block3(y2) + y2
# y4 = self.residual_block4(y3) + y3
return self.output(y2)
class DeeperNormalizedNet(_NetworkBase):
def __init__(self, in_features: int):
super().__init__()
self.input_trainsform = nn.Sequential(
nn.Linear(in_features=in_features, out_features=128),
nn.ReLU()
)
self.residual_block1 = nn.Sequential(
nn.Linear(in_features=128, out_features=64),
nn.ReLU(),
# nn.BatchNorm1d(num_features=64),
# nn.Dropout(),
nn.Linear(in_features=64, out_features=128),
nn.ReLU(),
# nn.BatchNorm1d(num_features=128),
# nn.Dropout(),
)
self.residual_block2 = nn.Sequential(
nn.Linear(in_features=128, out_features=64),
nn.ReLU(),
# nn.BatchNorm1d(num_features=64),
# nn.Dropout(),
nn.Linear(in_features=64, out_features=128),
nn.ReLU(),
# nn.BatchNorm1d(num_features=128),
# nn.Dropout(),
)
self.output = nn.Linear(in_features=128, out_features=1)
for name, son in self.input_trainsform.named_children():
weight: nn.parameter.Parameter
if (weight:=getattr(son, "weight", None)) is not None:
self.dtype: torch.dtype = weight.dtype
def forward(self, raw_x: torch.Tensor) -> torch.Tensor:
x = self.input_trainsform(raw_x)
y1 = self.residual_block1(x) + x
y2 = self.residual_block2(y1) + y1
return self.output(y2)
class WideNet(_NetworkBase):
def __init__(self, in_features: int):
super().__init__()
self.input_trainsform = nn.Sequential(
nn.Linear(in_features=in_features, out_features=128),
nn.ReLU()
)
self.residual_block1 = nn.Sequential(
nn.Linear(in_features=128, out_features=64),
nn.ReLU(),
nn.Linear(in_features=64, out_features=128),
nn.ReLU()
)
self.residual_block2 = nn.Sequential(
nn.Linear(in_features=128, out_features=64),
nn.ReLU(),
nn.Linear(in_features=64, out_features=128),
nn.ReLU()
)
self.residual_block3 = nn.Sequential(
nn.Linear(in_features=128, out_features=64),
nn.ReLU(),
nn.Linear(in_features=64, out_features=128),
nn.ReLU()
)
self.output = nn.Linear(in_features=128, out_features=1)
for name, son in self.input_trainsform.named_children():
weight: nn.parameter.Parameter
if (weight:=getattr(son, "weight", None)) is not None:
self.dtype: torch.dtype = weight.dtype
def forward(self, raw_x: torch.Tensor) -> torch.Tensor:
x = self.input_trainsform(raw_x)
y11 = self.residual_block1(x) + x
y12 = self.residual_block2(x) + x
y1 = (y11 + y12) / 2
y2 = self.residual_block3(y1) + y1
return self.output(y2)
class OtherNet(_NetworkBase):
def __init__(self, in_features: int):
super().__init__()
self.net = nn.Sequential(
nn.Linear(in_features=in_features, out_features=32),
nn.BatchNorm1d(num_features=32),
nn.Dropout(p=0.2),
nn.LeakyReLU(),
nn.Linear(in_features=32, out_features=1)
)
for name, son in self.net.named_children():
weight: nn.parameter.Parameter
if (weight:=getattr(son, "weight", None)) is not None:
self.dtype: torch.dtype = weight.dtype
def forward(self, x: torch.Tensor):
# x: [batch, channel]
return self.net(x)
if __name__ == "__main__":
baseline = Baseline(in_features=93)
x = torch.randn(64, 93).to(dtype=baseline.dtype, device=baseline.device)
baseline(x)
5. train.py
import datetime
import typing
from pathlib import Path
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
from colorama import Fore, Style
from matplotlib.axes import Axes
import torch
import torch.cuda
import torch.backends.cudnn
import torch.optim as optim
import torch.nn as nn
from torch.optim import optimizer
import torch.utils.data as data
import networks
from pathconfig import *
from dataset import *
class Trainer(object):
def __init__(self, network: networks._NetworkBase, dim2use: typing.List[int]=None) -> None:
super().__init__()
self.start_time: str = datetime.datetime.now().__str__().split(".")[0]
self.select_device()
self.reproducibile()
self.network = network.to(device=self.device)
self.suffix: str = self.network.__class__.__name__
self.log_folder: Path = Paths.log_path / self.suffix / self.start_time.replace(":", "_")
self.checkpoint_path: Path = Paths.checkpoint_path / self.suffix / f"{self.start_time}.pt".replace(":", "_")
if not self.checkpoint_path.parent.exists():
self.checkpoint_path.parent.mkdir(parents=True)
if not self.log_folder.exists():
self.log_folder.mkdir(parents=True)
# train
self.train_loader = data.DataLoader(CovidDataset(split="train", dim2use=dim2use), batch_size=64, shuffle=True)
self.val_loader = data.DataLoader(CovidDataset(split="val", dim2use=dim2use), batch_size=64, shuffle=False)
# mse for regression
self.lossfunc = nn.MSELoss(reduction="mean")
# self.lossfunc = nn.(reduction="mean")
# visualize
self.train_loss: typing.List[float] = []
self.val_loss: typing.List[float] = []
self.min_val_loss: float = float("inf")
self.axes: Axes
_, self.axes = plt.subplots(nrows=1, ncols=1, figsize=(18,9))
def select_device(self):
self.device = "cuda" if torch.cuda.is_available() else "cpu"
def reproducibile(self, seed: int=0):
np.random.seed(seed=seed)
torch.manual_seed(seed=seed)
# no optimization for convolution
torch.backends.cudnn.benchmark = False
# use default convolution algorithm
torch.backends.cudnn.deterministic = True
if self.device == "cuda":
torch.cuda.manual_seed(seed=seed)
torch.cuda.manual_seed(seed=seed)
def visualize(self, val_loss: float, train_loss: float):
plt.ion()
self.axes.cla()
self.axes.set_ylim(0.0, 400.0)
self.axes.set_xlabel("steps")
self.axes.set_ylabel("loss / MSE")
self.axes.set_title(f"{self.suffix}-{self.start_time}")
x_train = range(len(self.train_loss))
x_val = x_train[::len(self.train_loss) // len(self.val_loss)]
self.axes.plot(x_train, self.train_loss, c="tab:red", label="train loss")
self.axes.plot(x_val, self.val_loss, c="tab:cyan", label="val loss")
self.axes.plot([],[], label=f"min_val_loss: {self.min_val_loss:>5.4f}")
self.axes.plot([],[], label=f"val/train loss: {val_loss:>5.4f}/{train_loss:>5.4f}")
self.axes.text(x=len(self.train_loss)//2, y=200, s=f"Current loss: {self.train_loss[-1]:>5.4f}", fontsize=24)
self.axes.legend()
plt.pause(0.05)
plt.ioff()
def save(self, epoch: int):
print(f"Saving model at {Fore.GREEN}{Style.BRIGHT}{epoch}{Style.RESET_ALL} epoch, val_loss = {Fore.GREEN}{Style.BRIGHT}{self.min_val_loss}{Style.RESET_ALL}")
torch.save(self.network.state_dict(), f=self.checkpoint_path)
def lossfunc_l2(self, target, pred) -> torch.Tensor:
loss = self.lossfunc(target, pred)
norm_loss = 0
for param in self.network.parameters():
norm_loss += torch.sum(param**2)
return loss + norm_loss * 0.00075
@torch.no_grad()
def validation(self):
loss = 0
x: torch.Tensor
y: torch.Tensor
self.network.eval()
for x, y in self.val_loader:
x, y = x.to(device=self.device, dtype=self.network.dtype), y.to(device=self.device, dtype=self.network.dtype)
y_pred: torch.Tensor = self.network(x)
# loss += self.lossfunc(y, y_pred.squeeze()).sqrt()
# loss = self.lossfunc_l2(y, y_pred.squeeze())
loss += self.lossfunc(y, y_pred.squeeze())
l: torch.Tensor
self.val_loss.append(l:=(loss/len(self.val_loader)).cpu().item())
return l
def train(self, lr: float=1e-4, wd: float=0.9, n_epoch: int=3000, momentum=0.9, early_stop: int=200):
msg: str = input("请输入本次训练的日志记录:")
# optimizer = optim.SGD(self.network.parameters(), lr=lr, weight_decay=wd, momentum=momentum)
optimizer = optim.AdamW(self.network.parameters(), lr=lr, weight_decay=wd)
with open(self.log_folder.joinpath("message.txt"), "w") as f:
f.write(msg+"\n")
f.write(f"epoch: {n_epoch}, lr: {lr}, wd: {wd}, early_stop: {early_stop}, optimizer: {optimizer.__class__.__name__}\n")
early_stop_cnt = 0
for epoch in range(n_epoch):
x: torch.Tensor
y: torch.Tensor
self.network.train()
train_loss: float = 0
for x, y in self.train_loader:
optimizer.zero_grad()
x, y = x.to(device=self.device, dtype=self.network.dtype), y.to(device=self.device, dtype=self.network.dtype)
y_pred: torch.Tensor = self.network(x)
loss: torch.Tensor = self.lossfunc(y, y_pred.squeeze())
# loss = self.lossfunc_l2(y, y_pred.squeeze())
# loss = loss.sqrt()
loss.backward()
optimizer.step()
train_loss += loss.clone().detach().cpu().squeeze().item()
self.train_loss.append(loss.clone().detach().cpu().squeeze().item())
train_loss = (train_loss / len(self.train_loader))
val_loss = self.validation()
if val_loss < self.min_val_loss:
self.min_val_loss = val_loss
early_stop_cnt = 0
self.save(epoch=epoch)
else:
early_stop_cnt += 1
self.visualize(val_loss=val_loss, train_loss=train_loss)
if early_stop_cnt >= early_stop:
break
print(green(f"Training stopped at {epoch}"))
print(green("Saving trainig log"))
with open(self.log_folder.joinpath("train_val.loss.pkl"), "wb") as f:
pickle.dump(
{
"val": self.val_loss,
"train": self.train_loss,
"min_val": self.min_val_loss
}, file=f
)
plt.savefig(self.log_folder.joinpath("train_log.png").__str__(), dpi=300)
# @torch.no_grad()
# def get_presudo
def baseline():
b = networks.Baseline(in_features=93)
t = Trainer(network=b)
t.train(wd=0.5)
def previous2day():
dim2use = list(range(40))
dim2use.extend([57, 75])
b = networks.Baseline(in_features=42)
t = Trainer(network=b, dim2use=dim2use)
t.train()
def selected_feature():
dim2use = np.array([76, 58]) - 1
b = networks.Baseline(in_features=len(dim2use))
t = Trainer(network=b, dim2use=dim2use)
t.train()
def residual():
# dim2use = np.array([76, 58]) - 1
dim2use = np.array([75, 57, 42, 60, 78, 43, 61, 79, 40, 58, 76, 41, 59, 77])
# dim2use = np.array([76, 58, 43, 61, 79, 44, 62, 80, 41, 59, 77, 42, 60, 78, 93, 75, 57, 88, 70, 52, 84, 66, 48]) - 1
# dim2use = np.array([75, 57, 61, 79, 43, 78, 60, 42, 91, 73, 83, 80, 68, 62, 40, 86, 65, 77, 85, 67, 55, 49])
d = networks.DeeperNet(in_features=len(dim2use))
t = Trainer(network=d, dim2use=dim2use)
t.train(wd=0.5, lr=1e-3)
def normalized():
dim2use = np.array([76, 58]) - 1
d = networks.DeeperNormalizedNet(in_features=2)
t = Trainer(network=d, dim2use=dim2use)
t.train(wd=0.5)
def wider():
dim2use = np.array([76, 58]) - 1
w = networks.WideNet(in_features=2)
t = Trainer(network=w, dim2use=dim2use)
t.train(wd=0.5, lr=1e-4)
def other():
dim2use = np.array([75, 57, 42, 60, 78, 43, 61, 79, 40, 58, 76, 41, 59, 77])
o = networks.OtherNet(in_features=len(dim2use))
t = Trainer(network=o, dim2use=dim2use)
t.train(wd=0.5, lr=1e-4)
if __name__ == "__main__":
# baseline()
# previous2day()
# selected_feature()
residual()
# other()
# normalized()
# wider()
6. gen_submission.py
import typing
import numpy as np
import pandas as pd
import torch
import torch.utils.data as data
from dataset import CovidDataset
import networks
from pathconfig import *
@torch.no_grad()
def gen_submission(network:networks._NetworkBase, dim2use=None, save_path: Path=None):
test_loader = data.DataLoader(dataset=CovidDataset(split="test", dim2use=dim2use), batch_size=64)
result = []
x: torch.Tensor
for x in test_loader:
x = x.to(device="cuda", dtype=network.dtype)
y_pred: torch.Tensor = network(x)
result.extend(y_pred.cpu().squeeze().tolist())
if not save_path.parent.exists():
save_path.parent.mkdir(parents=True)
result = np.array(result)
with open(save_path, "w") as f:
print(save_path)
f.write("id,tested_positive\n")
for id, r in enumerate(result):
f.write(f"{id},{r}\n")
def gen_baseline():
net = networks.Baseline(in_features=93).cuda()
net.load_state_dict(torch.load(s:=Paths.checkpoint_path.joinpath("../checkpoint/Baseline/2021-12-12 15_29_31.pt")))
gen_submission(network=net, dim2use=None, save_path=Paths.submission_path.joinpath(net.__class__.__name__, s.stem.split(".")[0] + ".csv"))
def gen2day():
net = networks.Baseline(in_features=42).cuda()
net.load_state_dict(torch.load(s:=Paths.checkpoint_path.joinpath("../checkpoint/Baseline/2021-12-12 15_40_58.pt")))
dim2use = list(range(40))
dim2use.extend([57, 75])
gen_submission(network=net, dim2use=dim2use, save_path=Paths.submission_path.joinpath(net.__class__.__name__, s.stem.split(".")[0] + ".csv"))
def feature_selection():
# dim2use = np.array([76, 58, 43, 61, 79, 44, 62, 80, 41, 59, 77, 42, 60, 78, 93]) - 1
dim2use = np.array([76, 58]) - 1
net = networks.Baseline(in_features=len(dim2use)).cuda()
net.load_state_dict(torch.load(s:=Paths.checkpoint_path.joinpath("../checkpoint/Baseline/2021-12-12 16_33_04.pt")))
gen_submission(network=net, dim2use=dim2use, save_path=Paths.submission_path.joinpath(net.__class__.__name__, s.stem.split(".")[0] + ".csv"))
def residual():
# dim2use = np.array([76, 58, 43, 61, 79, 44, 62, 80, 41, 59, 77, 42, 60, 78, 93]) - 1
# dim2use = np.array([76, 58]) - 1
dim2use = np.array([75, 57, 42, 60, 78, 43, 61, 79, 40, 58, 76, 41, 59, 77])
# dim2use = np.array([75, 57, 61, 79, 43, 78, 60, 42, 91, 73, 83, 80, 68, 62, 40, 86, 65, 77, 85, 67, 55, 49])
# dim2use = np.array([76, 58, 43, 61, 79, 44, 62, 80, 41, 59, 77, 42, 60, 78, 93, 75, 57, 88, 70, 52, 84, 66, 48]) - 1
# dim2use = np.array([75, 57])
net = networks.DeeperNet(in_features=len(dim2use)).cuda()
net.load_state_dict(torch.load(s:=Paths.checkpoint_path.joinpath("../checkpoint/DeeperNet/2021-12-13 01_55_10.pt")))
gen_submission(network=net, dim2use=dim2use, save_path=Paths.submission_path.joinpath(net.__class__.__name__, s.stem.split(".")[0] + ".csv"))
def normalize():
# dim2use = np.array([76, 58, 43, 61, 79, 44, 62, 80, 41, 59, 77, 42, 60, 78, 93]) - 1
dim2use = np.array([76, 58]) - 1
net = networks.DeeperNormalizedNet(in_features=len(dim2use)).cuda()
net.load_state_dict(torch.load(s:=Paths.checkpoint_path.joinpath("../checkpoint/DeeperNormalizedNet/2021-12-12 17_55_08.pt")))
gen_submission(network=net, dim2use=dim2use, save_path=Paths.submission_path.joinpath(net.__class__.__name__, s.stem.split(".")[0] + ".csv"))
def wider():
dim2use = np.array([76, 58]) - 1
net = networks.WideNet(in_features=len(dim2use)).cuda()
net.load_state_dict(torch.load(s:=Paths.checkpoint_path.joinpath("../checkpoint/WideNet/2021-12-12 18_12_38.pt")))
gen_submission(network=net, dim2use=dim2use, save_path=Paths.submission_path.joinpath(net.__class__.__name__, s.stem.split(".")[0] + ".csv"))
def other():
dim2use = np.array([75, 57, 42, 60, 78, 43, 61, 79, 40, 58, 76, 41, 59, 77])
net = networks.OtherNet(in_features=len(dim2use)).cuda()
net.load_state_dict(torch.load(s:=Paths.checkpoint_path.joinpath("../checkpoint/OtherNet/2021-12-13 00_49_48.pt")))
gen_submission(network=net, dim2use=dim2use, save_path=Paths.submission_path.joinpath(net.__class__.__name__, s.stem.split(".")[0] + ".csv"))
if __name__ == "__main__":
# gen_baseline()
# gen2day()
# feature_selection()
# other()
residual()
# normalize()
# wider()