本文主要讲解李宏毅ML2021 Spring的Homework2: Phoneme Classification

李宏毅ML2021-Spring-hw2: Phoneme Classification
比较汗颜,上一个作业是在两个月之前了。这段时间发生了挺多的事情:一个是要期末考试了,所以忙于复习;西安出现了疫情封城了一个月;新年回老家过春节;写课程的笔记……
所以就把第二个作业的笔记耽误了,不过现在继续补上
1. Homework Objective
作业二的目的在于:
- Finish a classification task.
- 进一步熟悉基本的DNN训练技术:调参、特征选择、正则化
- 进一步熟悉Pytorch的使用
2. Task Introduction
本次任务要求我们根据一段语音序列,来对一个Phoneme(音位)进行分类。

1. What is Phoneme?
下面是百度百科的介绍
From Baidubaike:
音位(phoneme),是人类某一种语言中能够区别意义的最小语音单位,是音位学分析的基础概念。每种语言都有一套自己的音位系统。
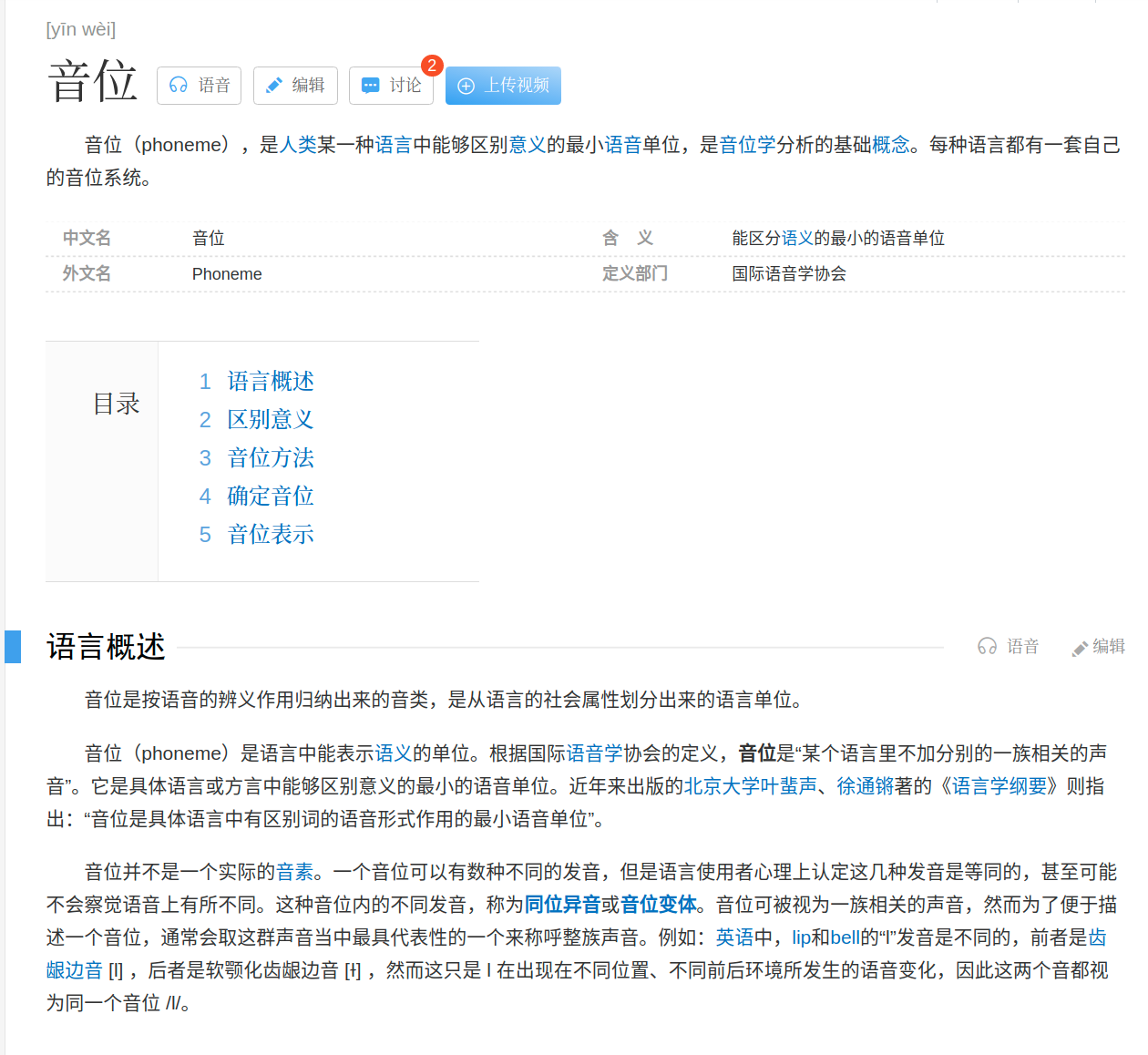
下面是Wikipedia的介绍:
From Wikipedia:
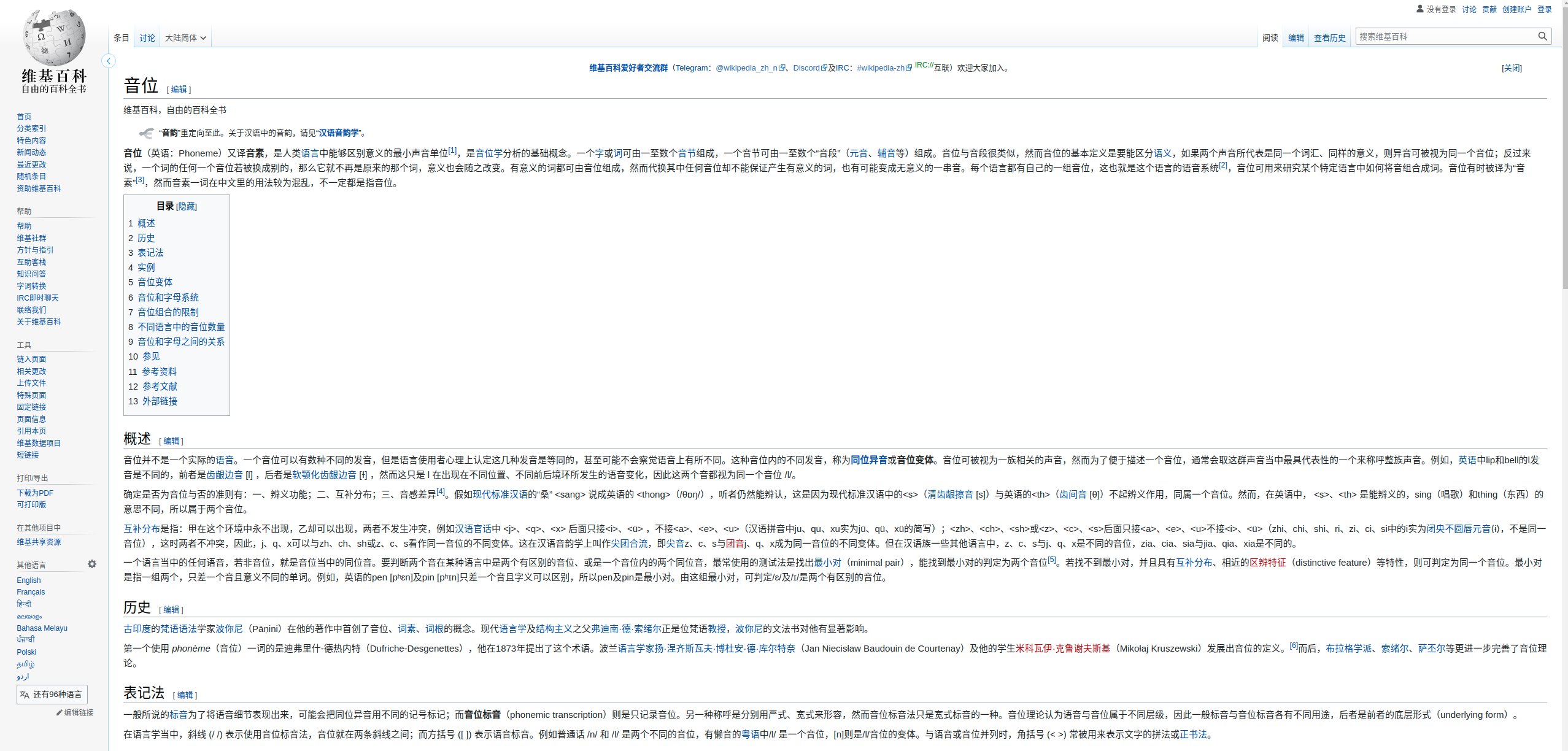
音位(英语:Phoneme)又译音素,是人类语言中能够区别意义的最小声音单位,是音位学分析的基础概念。一个字或词可由一至数个音节组成,一个音节可由一至数个“音段”(元音、辅音等)组成。音位与音段很类似,然而音位的基本定义是要能区分语义,如果两个声音所代表是同一个词汇、同样的意义,则异音可被视为同一个音位;反过来说,一个词的任何一个音位若被换成别的,那么它就不再是原来的那个词,意义也会随之改变。有意义的词都可由音位组成,然而代换其中任何音位却不能保证产生有意义的词,也有可能变成无意义的一串音。每个语言都有自己的一组音位,这也就是这个语言的语音系统,音位可用来研究某个特定语言中如何将音组合成词。音位有时被译为“音素”,然而音素一词在中文里的用法较为混乱,不一定都是指音位。
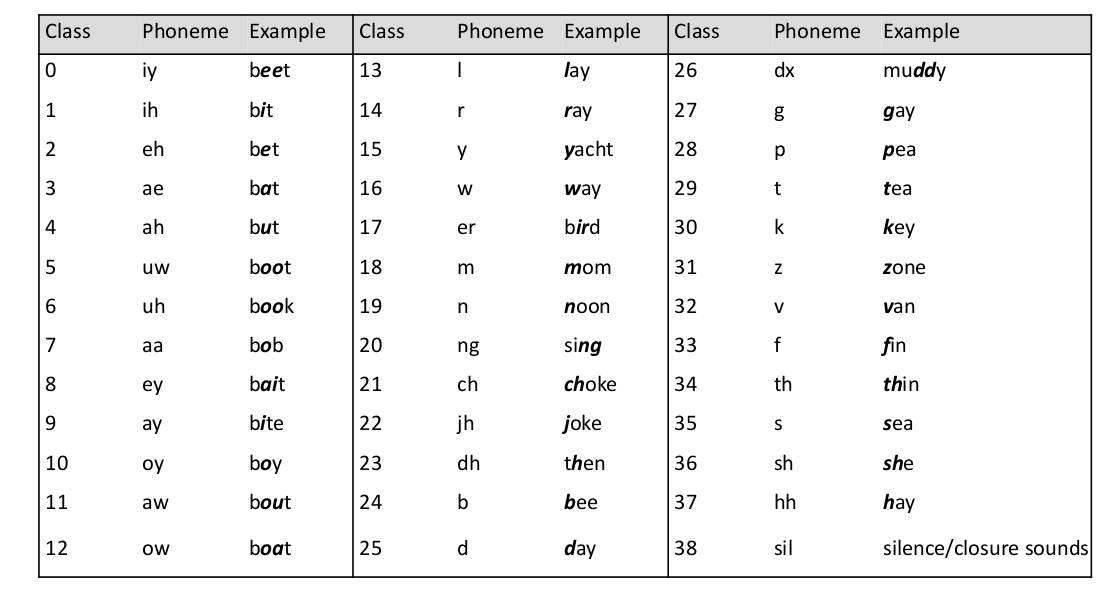
简单的来说,Phoneme就是发音中的最小单元。例如下面这张图

由于不同的语言有不同的Phoneme System,而本次作业是针对英语进行Phoneme Classification。
英语中Phoneme有最基本的39个Phoneme Unit,所以我们这次的任务是一个39 class 的 Classification任务
2. Data Description
本次作业的所有的数据都是从 TIMIT Acoustic-Phonetic Continuous Speech Corpus,这个语音的数据集中抽取来的。数据集的官网为:https://catalog.ldc.upenn.edu/LDC93S1
然而声音在计算机中的表示是通过采集设备,对连续的声音数据进行离散化,以位深、采样率等手段转换成离散的数据存储在计算机中。因此我们直接从可以播放的声音信号直接去做分类对我们来说太难了一点。所以助教首先对数据进行了Preprocess,将声音处理成Vector,从而使得我们可以进行训练。
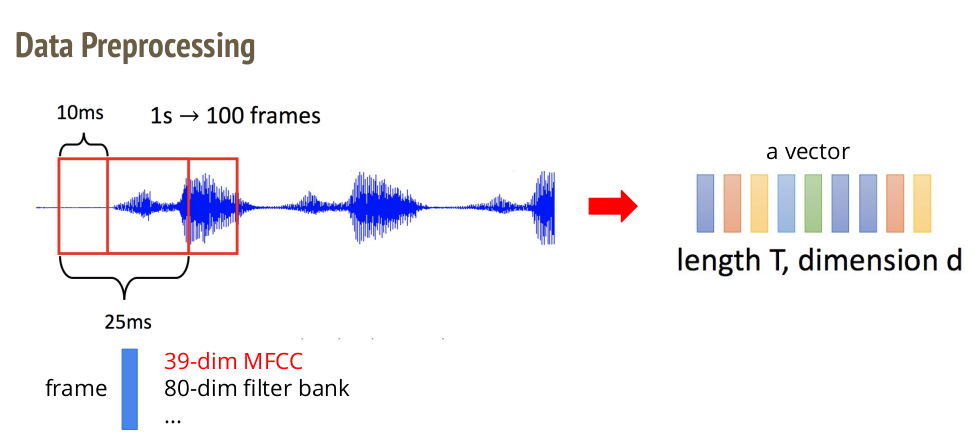
1. Data Preprocessing
给定一段声音信号,助教通过移动窗口(Sliding Window)的方式将他们转换为向量。
具体做法是给定一段语音,假设长度为1.025秒。那么这一秒的语音一共是1025ms,那么取window的长度为25ms,window滑动的step是10ms,那么window从声音的最左端滑动到最右端,一共有(1025-25) / 10 = 100 个Window(注意最后延伸了25帧)。
100个window通过一定的方法(下面会讲)进行处理,就将每个windows的10ms的语音波形信号转换成了一个具有d个dimension的向量。因此,通过Sliding Window的方式就把一段语音转换为一堆向量。
具体来说,把一个window转换为一个vector的算法有很多,例如助教图里举的MFCC、filter bank等算法。而不同的算法转换出来的向量的dimension是不同的,例如MFCC转换出来的向量有39个维度,而filter bank转换出来的向量有80个维度。
助教采用的算法是MFCC,因此我们最后得到的一段语音(例如一个单词)是100 * 39的一个矩阵,或者说是100个39维的列向量拼在一起。
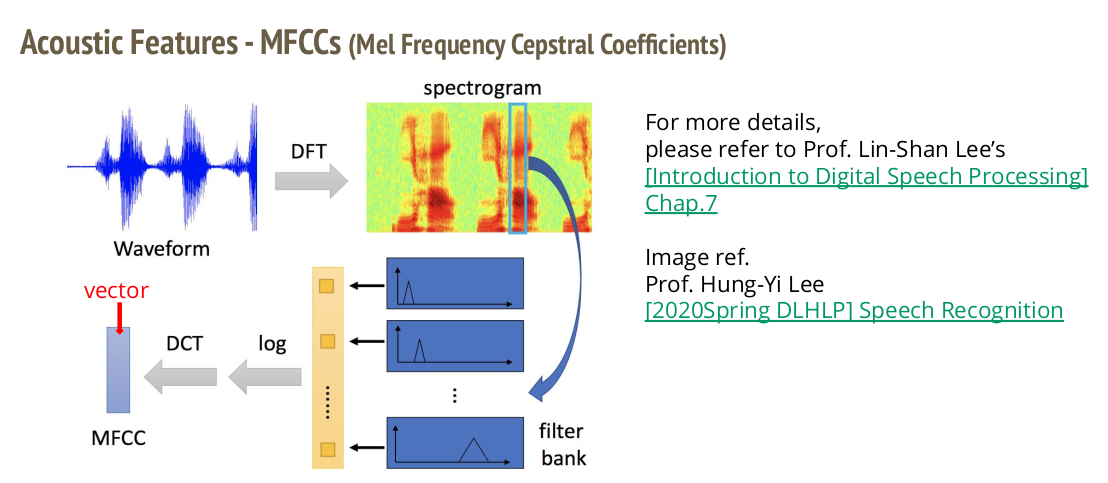
2. Mel Frequency Cepstral 1Coefficients (MFCC)
具体的MFCC的计算方式如下,首先对于波信号的声音信号通过离散傅里叶变换(Discrete Furiour Transformation)把时域信号转变为频域信号,而后通过filter bank得到这段声音在不同频率上的特征。
最后对这些特征取log之后计算DCT,就得到了一段声音信号对应的MFCC向量。
关于MFCC,可以参考李琳山老师讲的课:http://ocw.aca.ntu.edu.tw/ntu-ocw/ocw/cou/104S204
3. More Information About the Data
我们上面说,我们在进行Classification的对象是一个Phoneme,即我们现在要对一个长度为39维的vector进行39分类。
然而在真实情况下,Phoneme并不是单独存在的,而是和前后的Phoneme在一起,构成一个单词。所以,助教给的一个training example中的feature除了当前的Phoneme以外,还会有这个Phoneme的前五个和后五个Phoneme,一共11个Phoneme在一起,构成一个input。然后把这个matrix按列flatten成一个vector,就成了我们使用numpy解码之后的得到的input

所以,对数据在进入网络前进行后处理可能会有所帮助。
而且,因为已经告诉了大家这个数据集是怎样得到的,因此自己复现出来上面的步骤然后找到测试数据的label是严格禁止的,也不能手动听声音或者用其他的方法得到phoneme的label

3. Dataset & Data Format
本次题目所使用的dataset是来自于一个叫做TIMIT的数据集,在语音识别领域里面称为Corpus。它是英文的一个Corpus。
助教已经对原始数据集进行了处理,得到了我们上面说的每一个input都是11*39长度的向量。我们的数据集最后是三个文件,分别是:
- train_11.npy:训练数据的feature
- train_label_11.npy:训练数据的label
- test_11.npy:测试数据的feature
此外我们也不能使用额外的数据

4. Baselines
助教在Colab上提供了Sample Code,我们直接跑就可以过Baseline。
如果要过Strong Baseline的话,助教给了下面的几个tip:
- 改变网络的架构
- 训练阶段调参:Batchsize、Optimizer、Learning Rate、epoch……
- 一些Tricks:Batch Normalization、Dropout、regularization
因为这次是分类任务,因此计算分数就是按照准确率来给分,所以越大越好

3. My Solution
下面是我关于本次任务的理解和更新
1. Thoughs
这个是一个classification的任务,最后的输出是一个类别的one-hot向量,所以网络最后一层输出是和类别数量相同长度的一个向量。
然后因为要归一化,或者说引入概率(虽然只有Sigmoid才是从概率推到得到的),对最后的输出使用softmax,使得最终类别的概率向量的总和为1,而每个Dimension都小于1。
然后从所有的类别中选取出来(伪)概率最大的类(argmax)别作为网络最终输出的类别。
需要额外注意的是,Cross-Entropy Loss中已经帮我们集成了Softmax来算,因此训练的时候我们没有必要自己算softmax,但是在生成submission.csv的时候还是需要的自己算的。
除了这个基础的问题以外,还可以试试Self-Attention来提升性能。
2. Updates
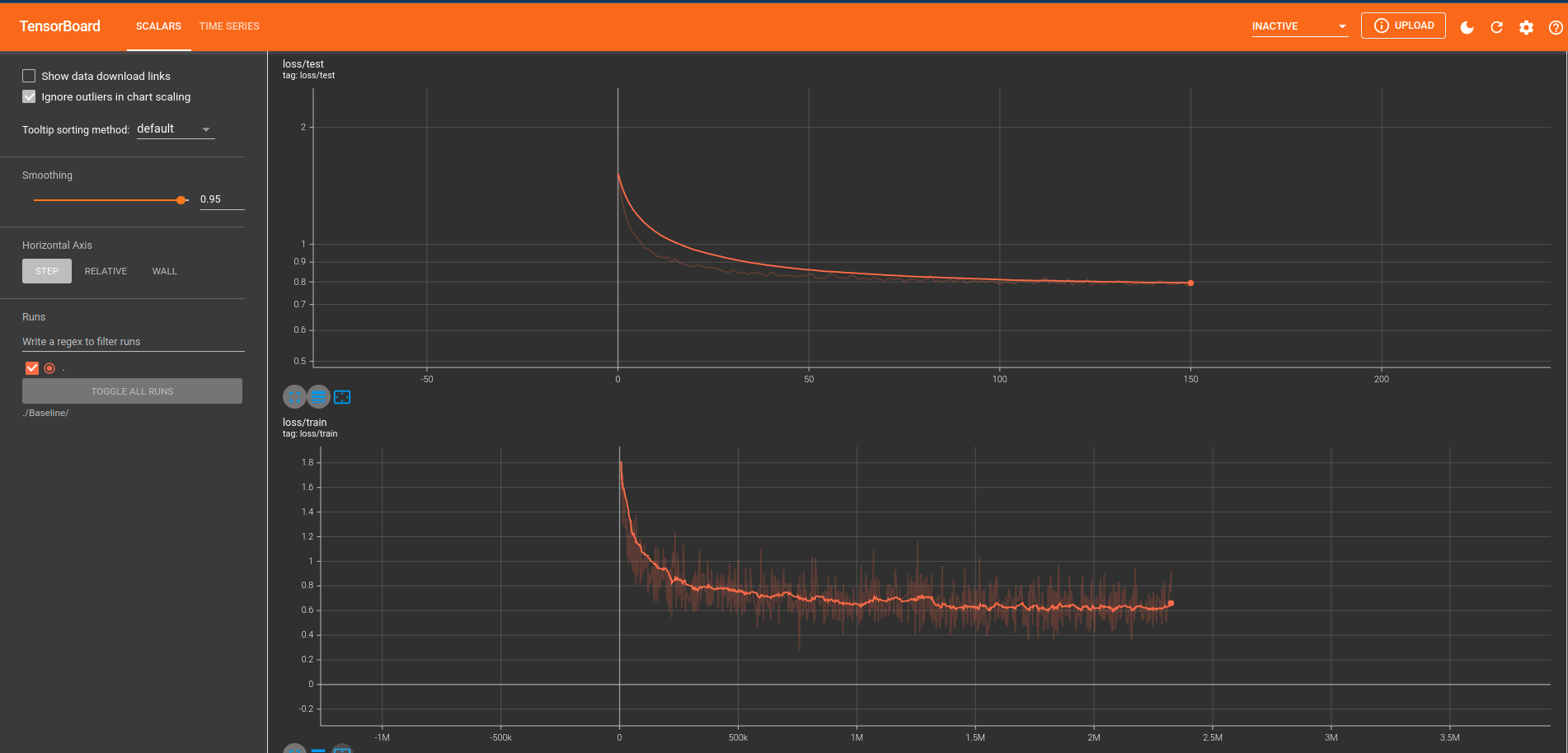
1. 2022.2.5:完成了基本的框架🚩
- 进展:完成了基本的框架的搭建,开始了Baseline的训练。完成的框架包括训练代码,网络的定义,dataset和得到提交文件的代码;这次使用了TensorBoard来监控训练过程,避免了自己用Matplotlib要花费大量的时间来写和训练无关的可视化代码